
 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.I'd like to see apachesolr have a index rebuilding process tied to Drupal's Batch API. There are times when it'd be preferable to rebuild the index quickly rather than waiting for cron to process several thousand nodes.
| Comment | File | Size | Author |
|---|---|---|---|
| #25 | apachesolr-456420-25.patch | 6.8 KB | tituomin |
| #24 | apachesolr-456420-24.patch | 6.82 KB | anarchivist |
| #16 | apachesolr-456420-6.x-1.x.patch | 6.82 KB | anarchivist |
| #11 | apachesolr-456420-11.patch | 6.83 KB | janusman |
| #10 | batch.patch | 6.96 KB | robertdouglass |

Comments
Comment #1
anarchivist commentedOne of my coworkers and I have put together a really, really rough module to handle reindexing using the Batch API. The code definitely needs work, better comments, etc. - please give feedback if you'd like!
Comment #2
anarchivist commentedComment #3
anarchivist commentedAny feedback on this would be greatly appreciated. Ideally, I think it would make sense to add this functionality to apachesolr, but if the developers think otherwise, I'd like to know.
Comment #4
pwolanin commentedThis is not really a priority for inclusion since it would only be relevant for large sites with developers in a big hurry :)
In those cases, they could change settings.php to increase the # of updates per cron run, and run corn 1x per minute or some such.
Comment #5
anarchivist commentedOK, thanks. I understand your point of view but we have had this use case...
I guess this is something that I should have filed as another issue (and will certainly do if it comes up again), but I was running into the problem of having stale information in apachesolr_search_node which prevented a complete reindexing, which is why this code clears out that table before it starts - have you seen this issue before?
Comment #6
pwolanin commentedIf there is stale info there, that's certainly a bug - though it's possible not all node updates are being caught, especially any that bypass nodeapi (i.e. don't use node_save()) will be missed.
Comment #7
janusman commentedI've been using this module a bit in a test install. I would have found it useful when migrating our D5 site to D6.
@pwolanin: I think Apache Solr itself is geared to site builders, and they *do* have to run cron.php a zillion times to get nodes in... I'm thinking this has an ample audience (potentially, *everyone* who's installing the module for the first time, or perhaps recently activated node access modules, etc?)
Perhaps it's not 1.x material, but 2.x as a contrib/ module? It could go in the current Reindex admin page; I'd recommend it go through a confirmation screen first.
I wonder what would be the impact on the server of doing this kind of batch processing...?
Thoughts?
PS: A code sugestion: change apachesolr_batch_reindex_settings_form() like so:
Comment #8
robertdouglass commentedI love this feature and want it to be an option on the main admin page.
Comment #9
anarchivist commentedAs I have time, I'll work on polishing this code.
Comment #10
robertdouglass commentedHere's a start at a patch for integrating it directly into apachesolr. The actual batch processing is broken but the error is probably something minor. It'd be great if someone could take it and finish it up.
Comment #11
janusman commentedIt was a headache figuring it out, but solved it: the problem was a missing 'file' element in the $batch array, needed when the processing/finishing functions are on a different file than the .module itself.
New patch.
Comment #12
jason ruyle commentedI just installed the patch from #11 and it's running smoothly.
I'm (re)developing a site that has 67k photos/nodes that have to be indexed. It would have taken forever to run the cron version of the update. Not only that, by using the cron method, it was causing really bad apache loads on our system. By running this version, it has reduced the load slightly.
Thanks for the patch.
I do have one question, not sure how possible this is, but we're doing a bulk index from a "re-index". It would be nice if this could touch off of a partially indexed site. I say this because if our browser cuts out, the bulk index stops.
Or maybe there is a way to run this from cli/drush. If I could run it as a background process on the server:
drush updatesolr &
something like that.
But again, thanks for the updates. If there is anything I can provide, please let me know.
Comment #13
robertdouglass commentedGreat stuff! Committed. Thanks anarchivist, janusman.
Open new issues for the suggestions to do bath indexing on the remainder and for adding Drush support.
Comment #14
anarchivist commentedGreat! Glad to see janusman turned this around so quickly. :)
Comment #15
anarchivist commentedI've applied the patch to the latest tarball for 6.x-1.x-dev, and it seems to be working fine. Would someone be willing to add this to 6.x-1.x.dev?
Comment #16
anarchivist commentedHere's a patch based on the application of the patch from comment #11 to apachesolr 6.x-1.x-dev in CVS.
Comment #17
tituomin commentedI also would very much like to see this patch in 6.x-1.x.dev.
Comment #18
aufumy commentedI have been testing this, and I love it.
Whenever, I have an issue with solr, for example most recently, with the capitalization, I might need to test out schema changes, and re-index with existing content, so this feature is very useful for me.
The only minor grief is that at the end of the process, the message is "0 items successfully processed." as an error. Even when cron is run it would say "200 items successfully processed." in red. However the message overcomes the suggestion of error when the number is 200 but when 0, the color and number may alarm an administrator.
Comment #19
pwolanin commentedComment above is relevant - a "catch up indexing" option instead of a full reindex.
If we are re-indexing all content, quite possibly this should only be directly available in combination with deleting the index?
Maybe the "catch up" should be the only thing added - you can trigger a delete or reindex and then catch up to get the content up right away. The same feature would then work to quickly get recent content in the index, or pick up from a failed batch.
Comment #20
anarchivist commented@pwolanin:
This might make sense and wouldn't necessarily be too difficult to add as part of this patch. If I have a chance over the next week I'll see if I can start hacking on this.
Comment #21
robertdouglass commentedI'd say we should sync DRUPAL-6--1 with the code already available (committed to DRUPAL-6--2) and then work on fixing the mentioned warning and making the "catch up" feature.
Comment #22
anarchivist commentedI second @robertDouglass's idea.
Comment #23
robertdouglass commentedOk, maybe someone can look at the error and wrong reporting that happens at the end of batch cycles.
Comment #24
anarchivist commentedHere's a rerolled version of the patch in #11 and #16 against DRUPAL-6--1. This still hasn't been committed to that tag yet.
Comment #25
tituomin commentedI replaced the error message with a more accurate message. Also, now the operation will completely delete the index in the beginning. The user is warned about this.
I think this feature would be nice to have in the 6.x-1.0 version.
Comment #26
tituomin commentedComment #27
janusman commentedWorks, code looks ok.
Comment #28
drewish commentedBumping the status back partially because it's bad form for the patch author to mark it RTBC and partially because I think we need to give this more thought.
I'd suggest that the 2.x code needs more work before we back port to 1.x. #573734: Index controls should be radio buttons with one form submission button has some good ideas. At the very least think we should allow the admin to index all remaining content without starting from the beginning every time. I've got 60,000+ nodes and run into issues after importing content where cron won't be able to catch up. I don't want to re-index from the beginning, I just want to index the remaining content.
Comment #29
pwolanin commentedsounds like it needs work then.
Comment #30
janusman commented@drewish: to clarify the original author was @anarchivist, not me =) See comment #1.
Comment #31
drewish commentedI posted a patch to #573734: Index controls should be radio buttons with one form submission button that does a bunch of cleanup to the batch api code.
In the current 2.x code we combine too many operations. By splitting out batch indexing from the delete and reset operations the interface becomes much easier to understand and use:
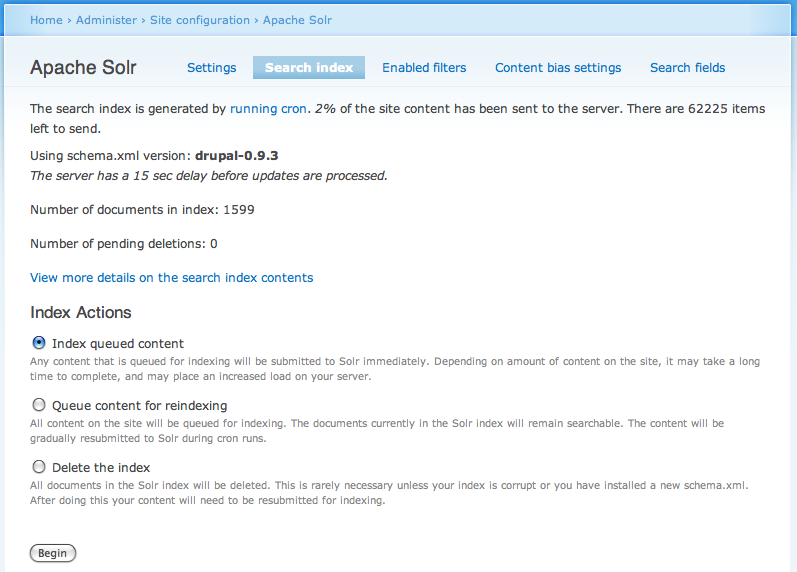
I'd love it if we could get this sorted out in the 2.x branch and then get a clean version backported.
Comment #32
jpmckinney commented#28 through #31: #573734: Index controls should be radio buttons with one form submission button can be committed after the original patches in this issue.
#19, #25: I don't always want to delete the index before re-indexing. Sometimes I just want to re-index.
#18, #21, #23:
Seems to be fixed in #573734: Index controls should be radio buttons with one form submission button (with E_STRICT fixes from http://drupal.org/cvs?commit=358046)
Comment #33
jpmckinney commentedComment #34
drewish commentedI'd suggest just copying and pasting the code from 2.x rather than trying to backport the patch.
Comment #35
jpmckinney commentedRight, but to know what code to copy-paste, you will need the patches to guide you :)
Comment #36
pwolanin commentedIf ported to 6.x-1.x needs to consider the fixes I proposed here: http://drupal.org/node/1062232#comment-4234262
I'm not seeing this as urgent.
Comment #37
alibama commentedworking until i hit 4800 nodes when updating 100-200 nodes at a time, makes it up to 10,000 when updating @ 50 at a time... then it errors out.... running the latest devs on all pieces as of august 15 - any help greatly appreciated, got ~60K nodes
Comment #38
alibama commentedjust wanted to let you guys know that this is a great mod, found that my theme was partly responsible for the timeouts.. it was a fusion theme with some javascript - went to the batch page with the ?op=nojs to turn the javascript off and shazaam was indexing 30k nodes with no timeouts... otherwise it wasnt' so bad - would just close the browser and restart the batch process and it would plow on slowly but surely... ya'll should consider rolling this into a project... it's really a great tool - also in case anyone else has this problem apachesolr views was somehow really messing with the indexing... like destroying it :)
Thank you all for your help
Comment #39
m.stentaThank you so much for this. I was getting ready to roll my own module for batch reindexing. You are awesome (speaking to the original module author, and all those involved in this issue thread). Can't wait to see this included in the official module. (long story short = subscribe)
Comment #40
michael121 commentedHi, is there a way to run the batch indexing without deleting the index, to index only new or updated content like cron does for the 6.x-1.x-dev Branch? Or to catch up the batch....
Comment #41
nick_vhYou can click "index queued content"?
Comment #42
nick_vhAt this point this is going to be postponed until 7 has a stable release. Then we'll work towards a better 6 version.
However, if you'd like to have this you should probably take a stab at this yourself?
Comment #43
michael121 commented#41 - yes, in the 6.x.2.x-dev but not in 6.x.1.x-dev. Here you can only do a full re-index with cron, apllying the patch above you can use the batch api to re-index, but even only a full re-index.
#42 - I think, to do this it is necessary to rewrite a lot of code... I compared the 2.x and the 1.x code and as I understood the code in 1.x it is written to delete the index before re-indexing. I'm not sure where to start...
May be you can give me a tip and I will try.
Comment #44
nick_vhAnd since feature requests are not valid for 6.x-1.x we are moving this to 6.x-3.x
Then again, I'm going to close this because 6.x-3.x will be a backport of 7.x-1.x and this version already support better drush support. Any new functionality should be requested in the 7.x branch and will or will not be backported.