Closed (fixed)
Project:
Drupal core
Version:
x.y.z
Component:
locale.module
Priority:
Normal
Category:
Task
Assigned:
Reporter:
Created:
2 Feb 2006 at 18:58 UTC
Updated:
19 Feb 2006 at 16:00 UTC
Jump to comment: Most recent file

I was asked to review how PO file import is done in Drupal. I was thrilled to see how inefficient the process was. The main problems were:
The first approach had no advantage whatsoever, so my optimization first pass was to eliminate that and read the PO file line-by-line, given that this was the parsing approach anyway. That reduced the memory requirements a great deal. Second it was a bit harder to process the tokenized file string-by-string, without building the big string array. It needed some code-move-around, so that the big array is not built up. This led to the fact that we cannot prevalidate the file, so broken files will be imported halfway before the process signals an error. This was accepted as a consequence on the development list by Dries, Gerhard et al.
The attached patch mostly contains original code, it is just moved around, so I retained Jacobo's credit information.
| Comment | File | Size | Author |
|---|---|---|---|
| #1 | import_memory_chart.png | 20.02 KB | gábor hojtsy |
| Drupal.locale-import-speedup.patch | 13.96 KB | gábor hojtsy |

{kind=link}
Comments
Comment #1
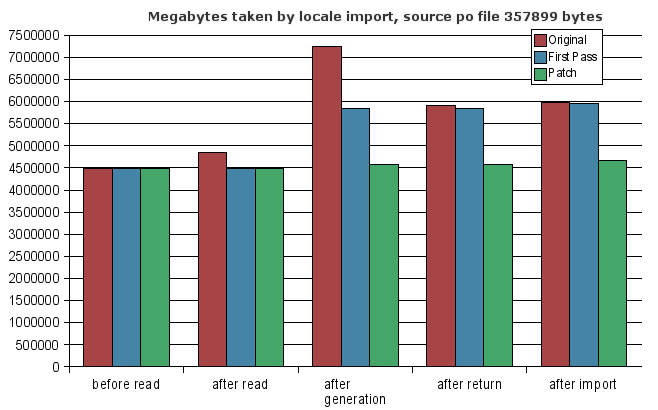
gábor hojtsyHere is a chart which should show the original memory requirement, which nears the 8MB default PHP memory limit with an out of the box HEAD Drupal, nothing additional installed. It also shows the first pass results (getting rid of reading the file at once), and the second pass results, which is reflected in the patch.
Comment #2
gábor hojtsyComment #3
gábor hojtsyErm, the chart actually shows bytes on the vertical axis, not megabytes as the text depicts, but otherwise it is correct...
Comment #4
dries commentedHaven't tried it but the code looks good. I guess this just needs a decent amount of testing before it can be committed. There are only so many translations one can import to test the code so if one PHP4 user and one PHP5 user can import a number of translations we should be OK.
Comment #5
wulff commentedWorks with PHP 5 (Apache 2.0.54, PHP 5.1.1 on windows).
Comment #6
dries commentedSome PHP4 testing anyone?
Comment #7
wulff commentedWorks with PHP 4 (Apache 2.0.55, PHP 4.4.1 on linux).
Comment #8
Cvbge commentedWhile testing this patch I discovered that something is corrupting UTF strings (at least chinese translation). To problem occures with and without the patch.
I've checked that the files contain valid utf8 characters, so it's either PHP, drupal or my setup fault.
When importing chinese simplfied translation:
Comment #9
Cvbge commentedI've tested on a different machine, also got errors (with chinese traditional; didn't get errors with chinese simplfied this time. Weird)
postgresql 7.4.7-6sarge1
php4 4.3.10-16
I'll probably move this to different issue...
Comment #10
Cvbge commentedJust a side-note: if this is PHP/drupal fault, it probably happens also for mysql, it's just mysql silently ignoring (or removing, or something) the illegal characters.
I suppose testing with mysql 5 in strict mode with latest drupal cvs could help checking it.
Comment #11
gábor hojtsyPiotr, I would suggest first checking the translation file outside of Drupal, whether it contains and unicode-invalid char. I bet it does.
Comment #12
killes@www.drop.org commentedCould this be due to the fact that translated strings are stored as blob in mysql and as text in pgsql?
Comment #13
gábor hojtsyTo stay ontopic, and to be sure that this patch fits, I tested again the import with the patch applied and without the patch applied. I have done a
mysqldump ... localet locales_source locales_targetafter each run, and diffed the two files. No difference. Used the upcoming Drupal 4.7.0 Hungarian translation as a test case. PHP Version 4.3.10-10ubuntu4.3Comment #14
Cvbge commented@Goba: I did, I've used simple perl script to convert the file into a one-line file and then used
COPY FROM file(http://www.postgresql.org/docs/current/static/sql-copy.html) to insert the data into a table in postgresql. I've also usediconv -f UTF-8 -t UTF-8 -c zh-hans.po > zh-hans.po.iconvthat should drop invalid characters from input. I found no errors. Thus I assume the file is correct.If you know any other way to check the file (a web-based validator would be the best) I'll check it using that too.
The script:
@killes: hmm right, didn't know that database.mysql uses blobs for that. That makes it work for any data...
I vaguely remember bug reports about locale tables and IIRC column type was changed... It was before Steven's UTF conversion patch. Maybe we should turn tham back into text and fix source of the problem instead...
I'll try to find the bug reports later...
Comment #15
Cvbge commentedHmm it seems it allways was blob... I wasn't able to find bug reports too... Maybe I was mistaken :/
Comment #16
Cvbge commentedI've changed the status by mistake.
Comment #17
dries commentedCommitted to HEAD. Thanks.
Comment #18
(not verified) commented