
 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.The issue of documenting the Drupal database has a long history.
It is generally accepted that the proper way to provide this documentation is through the API module.
The goal is to not only provide basic schema definition in a pretty format, but also to document the various fields by introducing some sort of standardized comment format.
References:
| Comment | File | Size | Author |
|---|---|---|---|
| #12 | Drupal5RC1_Database_0.png | 379.91 KB | rconstantine |
| #8 | Drupal5RC1_Database.png | 380.7 KB | rconstantine |
| #7 | DrupalCASEReport.zip | 572.62 KB | rconstantine |

{kind=link}
{kind=link}
Comments
Comment #1
joemoraca commentedAs far as a "pretty format" what do you think of this drupal ER generated by SchemaSpy please click around (scroll down on this page) it is a very cool tool. Of course it won't show what doesn't exist ... table / field comments...
Joe Moraca
Comment #2
drummCan you grab a smaller .install file from core and to suggest what the documentation would look like in code?
Comment #3
harry slaughterthe format i initially suggested was something like this:
Putting db field documentation on the same line as the field definition would strongly encourage people to keep the info up to date. otherwise it would almost certainly become out of sync very quickly. I know it's a bit unsightly, but I think it's much simpler than trying to define new "doxygen" syntax for labeling field definitions.
api.module would need to be able to parse out create statements and display a data dictionary for each table with a row for the comment. Perhaps the (FK) text could be replaced with a link to the foriegn table.
Comment #4
harry slaughterI'm still very interested in this idea.
However, I believe I'll need a celebrity endorsement.
Unless one or more high-profile drupal developers ratify a standard for documentation of .install files, I highly doubt other developers will bother including such documentation.
So I'll continue waiting patiently until schema documentation becomes a popular topic again :) I know it's not all that sexy, but for new developers, it would be extremely useful IMHO.
Comment #5
webchickAlso interested in this, but imo the best way to do this would be to have .install files use actual foreign key constraints, so that a relational diagram of the schema could be generated by any of a myriad of tools, rather than something custom for our own use only.
I think during the Drupal 6.x release cycle, we're planning on dropping support for MySQL 4.0.x and earlier. "In theory," this means we can switch to using foreign key constraints, which would document the relationships between tables.
There is still the matter of documenting what individual fields do, which are sometimes not clear. Clearly node.title is the node title, but what is authmap.authname, for example? Field-level comments of all fields in core .install files would also be a great improvement.
However, I think this is paramount to add said documention in core, not in the API module, as that's the only way it will *stay* documented. It becomes another requirement like PHPDocing functions: you can't add a new field/table/whatever unless it's documented.
Marking as a 6.x-dev postponed task for core. Probably the first step though is figuring out a standard, based either on what other projects do or based on MySQL documentation... that could start well before the code thaw.
Comment #6
harry slaughterthe documentation itself *would* live in each .install file. the reason this is ticket is under API is that ultimately this module should parse out comments (and schema?). if that's too complicated, we can just use one of the ERD tools to generate the info. though if you recall our try at this last year, we couldn't find a tool that generated the desired output in an acceptable format.
Comment #7
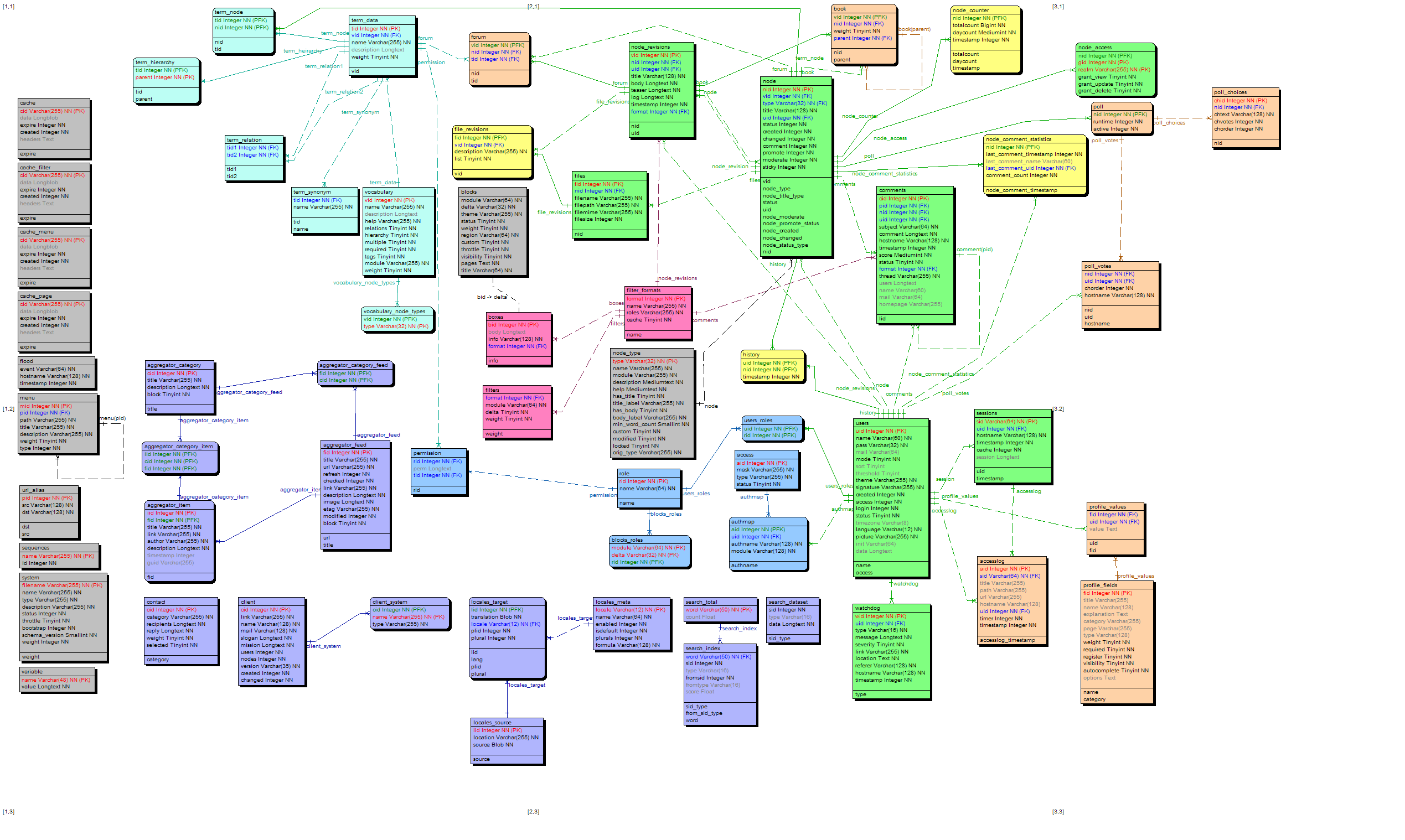
rconstantine commentedIt may be that nobody is interested in this, but I've created an ERD and accompanying HTML report of the Drupal 5 RC1 database (in a zip file). I have done my best to identify all relationships and show them as foreign keys.
I am curious as to why the database is not created and maintained in this fashion. If it were, schema (and therefore install files) could be generated for any number of databases above and beyond MySQL/PGSQL. As I was working through this, I found several things that I consider errors/bad practices, where a fix would not change the current operation of Drupal so far as I can tell. Perhaps I'll submit my findings for patches.
As my company is making a long-term commitment to using Drupal and as it is our practice to base software design on a model of the data, I will probably maintain this diagram for many years to come, whether anyone else is interested or not. I would appreciate verification of this work as is convenient to the reader. My results are a combination of reverse engineering (import into CASE Studio), sifting through the core Drupal install files, and comparing to the work done here: http://cvs.drupal.org/viewcvs/drupal/contributions/docs/developer/database/. Naturally, things don't change too fast so much of it was still relevant. I did make sure that my model matches the current install files.
Note that foreign keys can only come from Primary Keys or Primary Foreign Keys. Also note that because term_heirarchy uses "parent" as part of its PRIMARY KEY, my program will not allow me to create a self reference. Also see this: http://drupal.org/node/105011
LEGEND:
Gray = Lone tables with no relationships.
Purple = Tables and Table Sets with separate install files that don't link to the NODE MASS (what I'm calling all of the tables that somehow connect to NODE)
CYAN = Term-related tables
LIGHT PINK/PURPLE = Vocabulary-related tables
BRIGHT PINK = Filter-related tables
BLUE = Permission-related tables
TAN = Tables and Table Sets with separate install files that do link to the NODE MASS
GREEN = Core tables with what I call ORIGINATING PRIMARY KEYS (those primary keys auto-incremented/created in that table and used as foreign keys in other tables)
YELLOW = Core tables using FOREIGN KEYS as their PRIMARY KEYS
Those last two categories are probably forced. Maybe you have a better idea. I did make one or two changes to the diagram, but that shouldn't affect how Drupal works.
Feedback would be nice.
Comment #8
rconstantine commentedThe ERD image by itself.
Comment #9
webchickA couple things I notice about that diagram:
1. boxes belongs with "block" not with filter stuff. I think "bid" relates to "delta"
2. term_* and vocabulary_* are all part of the taxonomy system so probably should be coloured the same?
3. node_type relates to node through type.
Overall though, nice work! And yes, I agree that the best way for this to happen is for Drupal's schema to store actual PK/FK relationships so that any one of a myriad of tools could auto-generate this diagram.
Comment #10
rconstantine commentedThanks, webchick, for the quick response and for the feedback. I'll change points two and three right away. Regarding point one - that "bid" relates to "delta" - could you elaborate? I'll start looking through the code to find what you mean. Meanwhile, I'll believe you and place "block" near "boxes" similar to what I did for "search_dataset". I found in looking at some of the code that although many more tables are related to each other, they aren't always in the normal database-allowed ways. "search_dataset" is one example because it seems that "type" is shared in common with "search_index" but they don't reference each other at any point. It also seems that a "search_index" is aways worked out/created, or whatever when ever a "search_dataset" is, so I'm not sure why they are separate tables.
I also saw that in some tables, there may be an entry that is a varchar(255) which is a comma-separated list of what were ints in another table; so while there is a relationship, it's programmatic and not built-in to the DB. The program I use allows me to show "informational relationships" which don't import a column as a foreign key, so I'll have to look into them and see if that is how I could show this. Finding all such relationships may take a while.
I am also changing the box and line representation of many tables. Because it is easier, I build my diagrams using non-identifying relationships (square boxes and dashed connections). Usually, at the end, I go back through and identify which are actually identifying relationships and adjust their representation accordingly. I forgot to do that before I posted.
So, webchick, if you can get back to me regarding "bid" and "delta", or if I figure it out, I'll repost the png.
One last thing: can you confirm that the "format" in "boxes" is NOT the "format" in "filter_formats"?
Thanks.
BTW, I'll be doing this same procedure for each module/group of modules I use or develop. I'm looking at CCK and OG for starters. I don't know how anybody works without the big picture. My hat is off to all of the folks out there that can.
Comment #11
webchickFormat in boxes is indeed the same as format in filter_formats. But "boxes" is the table that holds the content of any custom block. So if you could re-arrange the diagram so that filter_formats appears between the block tables and node, that would be ideal.
The blocks table is weird in that it uses a combination of module (like block, og, user, etc.) and "delta" (a unique block ID to that *module*) for identifying a block. So for example, if you look in the user_block function, you'll see the following:
Those will be identified in the blocks table as module: user, delta: 0, module: user, delta: 1, etc.
When the module is "block" (meaning you've created a custom block from block module itself @ admin/build/blocks), then the delta corresponds to the bid in the "boxes" table.
Hope that made sense!
Comment #12
rconstantine commentedAn updated diagram
Comment #13
harry slaughterThis is not really the appropriate thread for providing ERDs. See this thread: http://drupal.org/node/28046 - we discussed using diagrams before and everyone pretty much concluded they would be of limited value and impossible to keep up to date.
Our goal is inline documentation that can be parsed by the API module. This is the only way we have a chance at keeping documentation accurate.
ERDs are proprietary, cannot be automated, put equal emphasis on schema components that are self-explanatory and don't allow for explanation of unintuitive areas of the schema or things that have been done in a non-optimal way on purpose.
Comment #14
rconstantine commentedHarry, I have read the node you suggested and both in that node and this one, I'd hardly say that any kind of consensus was reached. In fact, your own posts in this node suggest the use of ERDs including #6 right before my own first post. Regarding your post in #6, I think that is the best way to do things. Use an ERD program and include notes that can be output. For an example, if you have downloaded the zip from post #7 (which is no longer accurate) and you open "Default.html" and then go to the "attributes" page - if you scroll down to filter_formats.roles, you will see a section called "notes". The notes similar to those in comment #3 of this thread could be put here, or even expanded on. I only did the one to see how it worked. There is also available in the program I use a "comments" section which is similar to "notes". The difference between "notes" and "comments" is that one is output with the SQL, the other is not. Obviously, we would use the one that outputs with the SQL code. In fact, I believe that the output is exactly as you have shown, with the double dash (in MySQL anyway).
Additionally, I am advocating that Drupal's DB be designed using an ERD program because by doing so, errors and flaws are more readily identifiable and good practices are easier to adhere to. Clearly, the higher-ups aren't even looking at this thread since they haven't commented, so who knows if this is even possible?
Lastly, as I already stated, my company is going to maintain this diagram whether anyone else is interested or not. And although I did ask whether this was the right place to post this stuff or not, you didn't point me to where I should post it if not here. It seems the thread at 28046 is pretty much dead so it wouldn't make any more sense posting there than here.
Oh, wait, one more thing - if it could be decided which DB allows for the most documentation and most accurate representation of the ideal Drupal DB, the community could use that as a base and import/reverse engineer the DB into their ERD program of choice for viewing/export to their preferred DB. Plus, why have a person manually port to a particular DB if it can be done relatively automatically? Given an imported/RE DB in an ERD program, and once one had added the necessary additions to the DB abstraction layer, one would only have to export the SQL to their target DB, then cut/paste from the output to the various .install files. Am I wrong about this? Either way, I'm proceeding with what I've started. I'll also be adding the comments that you've already identified, Harry. And should the TBDs be replaced, in the majority of the column entries, I'll update my ERD with them. Thanks for the comments. It would be nice if we could get on the same page somehow.
Comment #15
harry slaughterERD won't work. It's proprietary, etc... same reasons as before. No way you're going to get a bunch of FOSS developers to rely on ERD software, let alone pay a dime for it.
Plus we want a way to document all schemas, not just Drupal core. With a standard format of documentation (TBD) embedded directly in .install files, all tables can be documented, not just core.
If you want to maintain an ERD of Drupal core, I suggest you commit it to contrib and add a corresponding page to the handbook pointing to it. It's definitely a useful thing to have (if it doesn't go stale as free-standing docs tend to do).
As far as this thread, please stick to the topic.
Comment #16
add1sun commentedOK, forgive the newb as she wraps her head around this. I am not a database person but I really want to find a way to get our DB better documented. I've been reading the threads on this and realize it keeps stalling. Am I correct that what we need at this point is simply to have an agreement about what goes into the install file and then write a parser for api.module to do something with whatever we agree on?
As for the .install file "stuff" to be added, why wouldn't we use the FOREIGN KEY (blah) REFERENCES tablename (blah) and the table COMMENT='' syntaxes? MyISAM will ignore the FOREIGN KEY but we can still use it for parsing and it is obvious to folks what it is and it's a standard syntax they can look up rather than trying to find what the "Drupal syntax" is. The table comment syntax would be nice to have and is easy to do as well. Then field comments can be regular -- comments. Sort of like this (truncated a bit):
Please remember that I don't really know what I'm talking about and just coming to this from the perspective of a newbie module dev and doc team maintainer.
Comment #17
Anonymous (not verified) commented+1
I like the idea. The databases that support the foreign key can then make use of it. There has been recent comment about referential integrity in the development list.
Comment #18
rconstantine commented+1 I'm for any advance in this area. I think that if the right comments could be added that could then be parsed, perhaps I could hook the results into an SVG representation so that we could get a visual/non-proprietary ERD going which updates as api.drupal updates. I've literally got 12 or more modules in the works for work right now, so I'm not sure how much help I can lend at present to the commenting effort, but I will if I can. I am volunteering to do the SVG thing once the commenting is done and I've got some time. I figure it could piggy back the parser to identify where to make the boxes, fill them with the table names and their data, and create referential links. So if a few someone wants to spearhead this (add1sun?) and start a group at groups.drupal, that would be cool. I've never written a parser, so I don't know what goes into it. I do get by with the database experience I have, so I'm willing to help there if I can.
Comment #19
webchickTake 3 or 12, I forget... http://drupal.org/node/164983.
Comment #20
gpk commentedAnd for a diagram for D6 see http://drupal.org/node/184586.