
I'm pushing 530 urls in the queue and start running concurrent URL checks with background process calls. Thread limit is ONLY 4. CPU spikes up to 100%, machines becomes unresponsive and memory spikes to... 400+MB and grows very fast up to 1.5GB... after some time cron finishes and only 60 links are checked.
This is not what I expected and it's not usable :-(.
I'm posting latest linkchecker patch in #380052: Add support with non-blocking parallel link checking.
| Comment | File | Size | Author |
|---|---|---|---|
| #19 | httprl-1869002-19-shrink-domain-connections-default.patch | 437 bytes | mikeytown2 |
| #18 | httprl-1869002-18-revert-head-only.patch | 2.43 KB | mikeytown2 |
| #10 | 2012-12-21_101029.png | 9.13 KB | hass |
| #5 | httprl-1869002-5-head-only.patch | 1.55 KB | mikeytown2 |
| #4 | httprl-1869002-4-slower-timings.patch | 1.75 KB | mikeytown2 |









{kind=link}
Comments
Comment #1
mikeytown2 CreditAttribution: mikeytown2 commentedHTTPRL uses usleep() and in $tv_usec in stream_select() in its event loop in order to not eat up CPU time. Have you tried this with the latest dev? I can not reproduce what you are reporting after processing 5k URLs (using the latest dev of HTTPRL).
Comment #2
hass CreditAttribution: hass commentedI've tested with DEV. After send_request has been executed the load spikes. Just creating/queue the array of links is fine, but when it starts checking for some time cpu load is 100%. Than it goes down to ~25% until it finishes. Memory load is extreme. I'm not sure when I find time to debug the source of this in httprl. What's your memory load and CPU?
Comment #3
mikeytown2 CreditAttribution: mikeytown2 commentedCPU usage bounces around between 0% and 5% (via top).
Memory usage is flat.
I was able to check 1,240 URLs in a single cron run when "Number of simultaneous connections" is set to 128. Function times out after that (hits 3 minute limit).
I put this at the bottom of _linkchecker_check_links().
Output from that:
37525176 = 36MB
10451392 = 10MB
What version of PHP and what OS are you on?
Comment #4
mikeytown2 CreditAttribution: mikeytown2 commentedYou can try this patch out, it increases the waiting periods inside of the loop.
My only guess for the memory usage is a GET request that returns a lot of data. I could make an option that kills the connection once we have the headers if this is what is causing the memory usage.
Comment #5
mikeytown2 CreditAttribution: mikeytown2 commentedThis patch has been committed to 6.x & 7.x. Adds a new option called head_only.
Allows us to only get the HEAD when using things like GET. I'm guessing that one of the links in your database points to a url with a lot of bytes to download and it only supports GET. This addition should make your use case more efficient.
Comment #6
hass CreditAttribution: hass commentedPlease rollback. The option is "method" that set's HEAD or GET. If I request with GET I have also set "Range" to request the first 1024 bytes only. You may remember this from past discussions.
See linkchecker:
Comment #7
hass CreditAttribution: hass commentedremoved
Comment #8
hass CreditAttribution: hass commentedPlease note that 100% of my tests have been HEAD requests as I know.
EDIT: There have been only 3 GET requests in 1500 urls.
Comment #9
hass CreditAttribution: hass commentedWindows 7 SP1 (x64)
PHP 5.3.1
MySQL 5.0.67
Comment #10
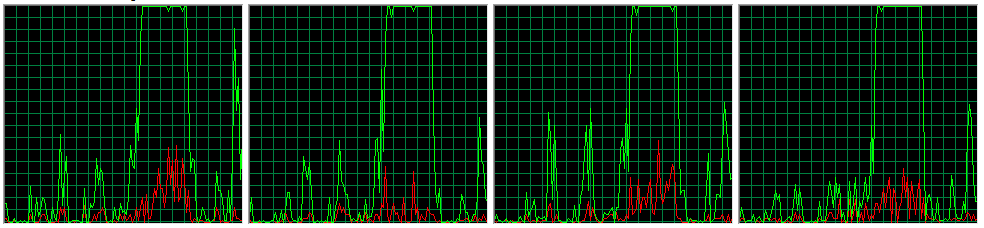
hass CreditAttribution: hass commented100% CPU on 4 cores:
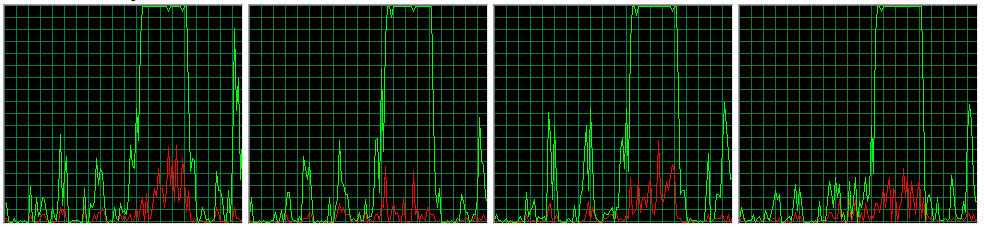
Comment #11
mikeytown2 CreditAttribution: mikeytown2 commentedI'll explain how head_only works, I don't think I need to roll this back. PS did you look at the patch in #5?
head_only = FALSE:
A GET request goes out with a range request of 0-1024. The server decides to ignore the range request and send everything back. And yes this is valid: http://stackoverflow.com/questions/720419/how-can-i-find-out-whether-a-s...
head_only = TRUE:
A GET request goes out with a range request of 0-1024. The server decides to ignore the range request and send everything back. HTTPRL closes the connection after we have gotten the HTTP headers.
The other idea on why your servers CPU usage is going up is that linkchecker is checking internal links (hitting your own server). You have a 4 core box, 4 concurrent requests to your box can in theory make it hit 100% CPU usage across all cores. If this is the case we can set the domain connection limit for the localhost to be 1 instead of the default of 8. This would also explain the memory usage.
Comment #12
hass CreditAttribution: hass commentedThis sounds not standard conform to me. Please see #1426854: Enforce Range headers on the client side. If I add a Range header I set the byte range in linkchecker and HTTPRL module is not allowed to do anything I have not specified. HTTPRL will never receive any byte more than 1024 bytes from the remote server if I set
$headers['Range'] = 'bytes=0-1024'. There is no need to add any extra options likehead_onlyto the module. If you'd like to add any extra logic you need to look for theRangeheader and depend on this one, but you should not create your own non-standard one. Note that I could also specify a byte range of$headers['Range'] = 'bytes=2000-6543'in linkchecker if I need exactly these bytes to be downloaded. I hope this makes clear that we are not talking about the first 1024 bytes only. Range is a generic HTTP feature mostly used by download accelerators to download packets in parallel and resume broken downloads just as a few examples. I'm only "abusing" it here to prevent a full file download. I could have been written$headers['Range'] = 'bytes=0-1', too.I would strongly suggest a rollback. I also see no byte range in patch #5. It may be better to document the Range header somewhere.
You are correct. HTTPRL have hit my own server. I'm sorry for this. I have disabled all localhost links and now all is good on my box. HTTPRL runs with ~80MB memory and quite normal CPU load. However I do not see the watchdogs. I'm not sure if something exists in httprl and the process never comes back to linkchecker to save the watchdog entries and to remove the named lock.
Comment #13
mikeytown2 CreditAttribution: mikeytown2 commentedSadly this is not correct. Some servers do not implement Range, or have intentionally disabled it for past security vulnerabilities.
http://serverfault.com/questions/304859/apache-disable-range-requests-di...
Parsing the range header and killing the connection if the data downloaded exceeds that limit if the Response is not a 206 does sound like a better option, just requires more work. I'll work on this :) Reading up on this to see what I need to do in order to parse the range header http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.35
Comment #14
hass CreditAttribution: hass commentedSounds more than perfect :-) looking forward to this...
Comment #15
mikeytown2 CreditAttribution: mikeytown2 commentedChanging the default domain_connections from 8 to 2 might be a good idea. I got 8 by taking the highest level (IE 10) from all modern browsers. All other modern browsers are at 6. This setting could be related to this issue #1837776: Background requests going to the correct IP but wrong Host..
Range Header:
Looks like I need to be able to parse these and get the byte count.
Response back from a request with lots of commas looks like this:
URL: http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
Request modified via https://addons.mozilla.org/en-us/firefox/addon/modify-headers/
Range: bytes=28-175,382-399,510-541,644-744,977-980Headers Back:
Content:
Being able to glue this back together will be a feature in the future (multipart decoding). Luckily for us all of this doesn't matter as I'm trying to figure out what the the last byte I need and don't download after that when I do a range request and instead of a 206 I get a 200.
The thing with enforcing the byte range is I will be taking a 200 and converting it to a 206. Something like this should require a setting in order to turn it on as it might be un-expected behavior.
Comment #16
hass CreditAttribution: hass commentedContent-Range and Accept-Ranges may allow to identify if the server allow ranges. I never seen status code 416 (Requested range not satisfiable), but it seems to exists.
Second to last comment in http://stackoverflow.com/questions/2209204/parsing-http-range-header-in-php . Fully untested myself :-)
Comment #17
hass CreditAttribution: hass commentedhttp://www.ietf.org/rfc/rfc2616.txt
Comment #18
mikeytown2 CreditAttribution: mikeytown2 commentedGoing to re-open #1426854: Enforce Range headers on the client side and use that for the location of the range header.
This patch has been committed. It reverts the patch in #5 and fixes documentation for one of the error constants.
Comment #19
mikeytown2 CreditAttribution: mikeytown2 commentedCommitting this patch so I can close this issue. Patch changes domain_connections from 8 to 2.