
Subj + minor fixes to FeedsSource.inc so that processing EMPTY parser results won't break the batch operation (it was before).
Functions:
* CSV parser configuration page and Importer start screen:
- source file encoding selection
- checkbox to check source encoding
* Parser
- converts encoding of source data
- checks source encoding and if it differs - throwing an exception
Screenshot:
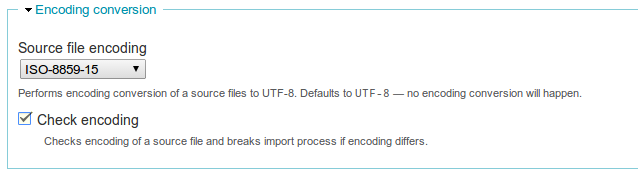
Requires: mbstring PHP extension
| Comment | File | Size | Author |
|---|---|---|---|
| #112 | interdiff-1428272-110-112.txt | 1.04 KB | MegaChriz |
| #112 | feeds-encoding-support-csv-1428272-112.patch | 16.5 KB | MegaChriz |
| |||
| #110 | interdiff-1428272-108-110.txt | 2.35 KB | MegaChriz |
| #110 | feeds-encoding-support-csv-1428272-110.patch | 16.47 KB | MegaChriz |
| #108 | feeds-encoding_support_CSV-1428272-108.patch | 15.89 KB | MegaChriz |
| |||









{kind=link}
{kind=link}
Comments
Comment #0.0
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #0.1
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #0.2
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #0.3
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #1
OnkelTem CreditAttribution: OnkelTem commentedComment #1.0
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #2
dmstru CreditAttribution: dmstru commentedHi!
Cool features. I need this - I must check it.
Rus:
Пацаны, ваще ребята!
Молодцы, четко, могёте, умеете!
Пошел тестировать.
с ув., Алексей
Comment #2.0
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #2.1
OnkelTem CreditAttribution: OnkelTem commentedNote
Comment #3
OnkelTem CreditAttribution: OnkelTem commentedSupplying patch to 7.x-2.x git version.
Since
commerce_feedsdev branch haven't been updated to accomodate severe changes in thefeeds2.x git branch yet (getting error message:Class FeedsCommerceProductProcessor contains 2 abstract methods ....), I had no chance to test the patch.Comment #3.0
OnkelTem CreditAttribution: OnkelTem commentedasd
Comment #4
dmstru CreditAttribution: dmstru commentedHi your patch not work:
:41: trailing whitespace.
:43: trailing whitespace.
:121: trailing whitespace.
$defaults = $this->configDefaults();
:125: trailing whitespace.
'#collapsible' => TRUE,
error: patch failed: plugins/FeedsCSVParser.inc:17
error: plugins/FeedsCSVParser.inc: patch does not apply
I try to use it in last dev version.
ALEX
Comment #5
dmstru CreditAttribution: dmstru commentedPlease contact with me via mail or skype awa_77.
Comment #6
OnkelTem CreditAttribution: OnkelTem commentedFixed patch to 7.x-2.0-alpha4
* Fixed errors in previous (#0) patch: added missed encoding conversion when a cell allocates more then one line.
* REWORKED parser. This is serious change. I believe the original CSV parser did things in a wrong way, treating an arbitrary double quote as a delimiter. IMO, this violates CSV rules, which states, that a field should be [fully] double quoted, when something uncommon happens in it. For example:
;A string with a "double quote in it;should definitely break parsing process. The correct variant would be:
;"A string with a ""double quote in it";But current implementation will accept the former and will feed the fields' value with subsequent lines until next double quote.
In my patch it will throw an exception with corresponding message about it, stopping parsing.
p.s. Moving the issue back to alpha4. This is odd, I know, but I lost in versions.
Comment #7
polom CreditAttribution: polom commentedHi,
I have import problems related to encodings (my CSV files are is-latin 1 encoded) and as re-encoding them is not my favorite choice I tried to find solutions.
This patch seems a nice deal but I can't apply it. I have Feeds 7.x-2.0-alpha4 but here is what I get :
$ patch < adding_encoding_conversion_support_2.patch
patching file FeedsSource.inc
Hunk #1 FAILED at 343.
1 out of 1 hunk FAILED -- saving rejects to file FeedsSource.inc.rej
patching file ParserCSV.inc
Hunk #1 FAILED at 74.
Hunk #2 FAILED at 92.
Hunk #3 FAILED at 194.
Hunk #4 FAILED at 232.
Hunk #5 FAILED at 258.
Hunk #6 FAILED at 320.
6 out of 6 hunks FAILED -- saving rejects to file ParserCSV.inc.rej
patching file FeedsCSVParser.inc
Hunk #1 FAILED at 17.
Hunk #2 FAILED at 101.
Hunk #3 FAILED at 145.
Hunk #4 FAILED at 154.
Hunk #5 FAILED at 180.
5 out of 5 hunks FAILED -- saving rejects to file FeedsCSVParser.inc.rej
Am I missing a point here ?
Comment #8
OnkelTem CreditAttribution: OnkelTem commentedDoes
patch -p1 < patchfilework for you?Comment #9
emackn CreditAttribution: emackn commentedComment #10
polom CreditAttribution: polom commentedyes it does :
$ patch -p1 < adding_encoding_conversion_support_2.patch
patching file includes/FeedsSource.inc
patching file libraries/ParserCSV.inc
patching file plugins/FeedsCSVParser.inc
Unfortunately my iso-latin encoded CSV file could not be imported and I had to convert it.
Comment #11
OnkelTem CreditAttribution: OnkelTem commented@polom
Would you send me an example file?
aneganov at gmail d0t com
Comment #12
derhasi CreditAttribution: derhasi commentedThe patch works for me.
Cleaned it up for coding styles and renamed it, so the issue is referenced. (@see).
@polom, did you set the "Source file encoding" in the "Settings for CSV Parser"?
Comment #13
derhasi CreditAttribution: derhasi commented*arg*, sorry forgot to attach the patch
Comment #14
emackn CreditAttribution: emackn commenteddo you have a test for this?
Comment #15
derhasi CreditAttribution: derhasi commentedOnkelTem,could you provide a test for that?
Comment #16
OnkelTem CreditAttribution: OnkelTem commented@derhasi, I would gladly make one, if I were know how to do that :) Really, I never created unit tests before.
Comment #17
Yuri CreditAttribution: Yuri commentedthere is a patch in the issue summary, and in #13.
Which one to use? I applied #13 and update.php, nothing changed so far, I still have error
SQLSTATE[HY000]: General error: 1366 Incorrect string valueComment #18
OnkelTem CreditAttribution: OnkelTem commentedPlease, provide a copy of example data file which produces the error.
Comment #19
Yuri CreditAttribution: Yuri commentedIn my case, I use feeds, mailhandler and mail comment modules (latest devs in d7)
The following error messages appear on
http://www.exampledomain.com/import/mailhandler_commentsThe drupal error log shows:
and the feeds log shows:
Comment #20
Yuri CreditAttribution: Yuri commentedThe data imported is a general Gmail message like 'hello' (of which I have set utf8 for outgoing messages, according to http://support.google.com/mail/bin/answer.py?hl=en&answer=22841
Comment #21
OnkelTem CreditAttribution: OnkelTem commentedAre you mails come in CSV format?
Comment #22
OnkelTem CreditAttribution: OnkelTem commentedComment #23
xaqroxSeems to work really well for me. Don't know the test framework very well either or I'd be right on it. I found a bunch of other issues which I believe this solves, which I closed as duplicate. Hope that's not too presumptuous.
#1605628: Encoding problems while importing from CSV
#1471950: CSV Parser: Check and Convert the Encoding
#1220606: Add support for encoding conversions for any parser
#1319142: csv in ISO 8859-15/EURO
Comment #24
twistor CreditAttribution: twistor commentedComment #25
OnkelTem CreditAttribution: OnkelTem commented@twistor
We probably need to split this issue, since #6 is reporting about serious bug in parser.
What do you think?
Comment #26
twistor CreditAttribution: twistor commentedYes, these are very separate issues.
Comment #27
OnkelTem CreditAttribution: OnkelTem commentedSeparating encoding support from the rest.
Comment #28
OnkelTem CreditAttribution: OnkelTem commentedMoving two more changes into separate issues:
#1720658: Empty parser's results fails import
#1720724: Fix DQUOTES handling according to RFC 4180
Comment #29
twistor CreditAttribution: twistor commentedThis should use extension_loaded(). Move this check to the top of the function, don't check twice.
This whole fieldset should be conditional on the mb library.
Should use extension_loaded().
Could you please provide an example CSV file that needs this functionality?
Comment #30
Stan Turyn CreditAttribution: Stan Turyn commentedHi twistor,
I'm attaching a sample CSV file that requires conversion. Any chance to see the patch commited to dev?
Comment #31
mtoscano CreditAttribution: mtoscano commentedHi,
I need encoding conversions from Spanish characters: which one is the patch to use against the current alpha7 release?
Thanks
Comment #32
Dubs CreditAttribution: Dubs commentedThanks so much for your time on this essential module!
Please can this be committed - this would be so useful as I feel pain at the moment every time I have to import Euro characters!
Comment #33
imclean CreditAttribution: imclean commentedTo the last 3 posters, see #29. The patch still needs work before it can be committed.
Comment #34
Jerenus CreditAttribution: Jerenus commentedHere is the patch based on all the previous. And I made some modifications to let it work.
Comment #35
Jerenus CreditAttribution: Jerenus commentedThe final one.
Comment #36
pcambraComment #37
spuki CreditAttribution: spuki commentedIt's not working for me. File encoding is Windows-1251, but it was recognized as CP936. So I just commented lines with encoding checking.
Comment #38
bjcone CreditAttribution: bjcone commentedI downloaded the patch and it seems to be working to check the encoding of individual lines. However, I ran into a case where the file I was attempting to import was encoded such that fgets() did not recognize the end of line character and returned the full contents of the file. At this point it is too late for this patch to help.
What I found to resolve this issue and enable feeds to import my ASCII-encoded file was ini_set("auto_detect_line_endings", true). See the bottom of the page at http://www.php.net/manual/en/filesystem.configuration.php#ini.auto-detec... for more information. It seems as though PHP, without this setting, does not separate lines which only end in \r (Mac Carriage Return character).
Hope this is useful to someone else as it took me a while to find.
Comment #39
liquidcms CreditAttribution: liquidcms commentedi have issue similar to #37. i saved a file from Excel (2007) as .csv. the file has 5 lines, 3 of which have odd non-ASCII dashes. when hitting the detect encoding line in the patch; as spuki states, those 3 lines are detected as CP936.
NOTE. comment in #37 about commenting out those lines doesn't do anything; mb_detect_encoding doesn't modify the data it simply determines the encoding. with or without the array of encoding types listed it still determines these lines are CP936 and the part of the code which then does the encode still runs (that check is simply to make sure we don't re-encode data that is already UTF-8.
so the only issue (and maybe not fixable) is that to convert those dashes in CP936 to UTF-8 the dash is simply removed - this is not a great solution; but without the patch and the encoding conversion Feeds import fails on these characters.
ALSO - as noted in #1140194: SQLSTATE[HY000]: General error: 1366 Incorrect string value for a field with accents if i open the Excel saved CSV into Notepad and then re-save as UTF-8, the dashes import correctly (with or without this patch; although i agree would be nice if Feeds could handle this).
Comment #40
liquidcms CreditAttribution: liquidcms commentedturns out losing characters when using PHP to convert from CP936 to UTF-8 is a bug in PHP 5.3 and has been fixed in PHP 5.4.0 (https://bugs.php.net/bug.php?id=60306)
Comment #41
liquidcms CreditAttribution: liquidcms commentedbtw, patch in #35 does not adhere to drupal coding standards. i think the attached is somewhat closer
Comment #43
Jerenus CreditAttribution: Jerenus commentedComment #44
msti#35 works for me
Thanks!
Comment #45
mstiscreenshot
Comment #46
Summit CreditAttribution: Summit commentedHi, for me too! Setting this to RTBC ok?
Greetings, Martijn
Comment #47
meSteJust to be clear: is #35 the patch that will be committed?
Comment #48
twistor CreditAttribution: twistor commentedAs was already pointed out, the patch in #35 breaks Drupal coding standards.
Honestly the to, from, check encoding business seems too complicated. Feeds is complicated enough. Is there a valid reason why we can't just automatically detect the encoding, and use that without any user interaction?
Comment #49
Honza Pobořil CreditAttribution: Honza Pobořil commentedtwistor: Because sometimes the automatic detection is not reliable. It's nice to have auto detection, but not only this.
Btw, if you think Feeds is too complicated too, see this project.
Comment #50
13rac1 CreditAttribution: 13rac1 commentedHere is #35 plus the coding standard changes from #41. Should pass tests. Works great for me to import international characters. Thanks everyone.
Comment #50.0
13rac1 CreditAttribution: 13rac1 commentedasd
Comment #51
Jerenus CreditAttribution: Jerenus commentedAre we have the conclusion that the demand of user interaction?
Comment #52
13rac1 CreditAttribution: 13rac1 commentedI've refactored this a bit:
It needs simpletests and possibly more refactoring to fit better within the current code architecture.
Comment #53
johan2 CreditAttribution: johan2 commentedHi, I installed the latest patch 52. I have a csv with terms in a column with a special character (ë). When I import the csv (utf-8) the term is not recognized. The select term field stays empty. I am struggling for a week with this. The only thing that works is to make a fake term without special character and try to change it by deleting the term and try to merge it with the intended taxonomy term with the special character or changing the term name once it is imported.
Comment #54
13rac1 CreditAttribution: 13rac1 commented@johan2 Have you tried any other encoding options? Windows‑1252 worked for my imports.
Comment #55
johan2 CreditAttribution: johan2 commentedI am working on a power mac with excel 2001. My best setting to save from excel is -windows csv-. With Smultron and Textmate I controlled the file, and it shows no problems. A text is imported fine to a Text-field except when it has to go to a Term-field with special characters then it goes wrong even when changing the "ë" to "ë".
I suspected also the file... is it really utf-8 ? I found more issues concerning this.
Comment #56
johan2 CreditAttribution: johan2 commentedIt must have something to do with the taxonomy. When I export a Term to csv from the site it will export the "ë" to "ë" . I kow that my excel is not the newest but through text-edit or smultron or textmate the text can be exported to utf-8, even changing the "ë" manually. Only for the Term the issue stays unsolved other text-fields have no problems and import correctly.
Comment #57
johan2 CreditAttribution: johan2 commentedWhat also happens is if you adapt the same Term, changing "ë" to "e" in both taxonomy and csv-file, the import can go wrong because something stays in memory. I don't know what it is but flush cache is not enough or updating aliases. Changing abrupt to another Term that was in the taxonomy before works... So once it goes wrong you are started for a lot of worries since you are not sure what to do.
Comment #58
johan2 CreditAttribution: johan2 commentedI have some more information about what happens. It seems that a great deal of the problem can be caused by the uploading process. When creating new terms is allowed (because otherwise the term stays empty) on import then the csv file creates for the same collumn with the same term several times a new term and in that process it ends up with ? ? ? around each character. So many duplicates are created. I installed the merge module 7-1 and here I noticed this behaviour. Before I had merge 7-2dev and the replace module, I desinstalled them. But also good news is that the special characters are passing.
Comment #59
13rac1 CreditAttribution: 13rac1 commentedSo, do you mean this feature patch is working correctly?
Comment #60
johan2 CreditAttribution: johan2 commentedI did some more testing and ended up installing Openoffice. Some of the characters in excel didn't export correctly. This was not obvious to find out. In the Openoffice Calc (spreadsheet) I noticed that some characters had ? around them. So this was also the case in the import with Feeds. Once I deleted these and exported the sheet again to csv the Feeds-import worked. The problem was that these ? were invisible in a texteditor or textmate. To import excel into Openoffice goes through a wizard and the software is free, so for me this is solved ;-)
Comment #61
johan2 CreditAttribution: johan2 commentedThanks for the great module. Just imported over 10.000 records with all kinds of data inline: title, number (mixed 1a, 1.1, 2, etc) ,category, subcategory, dates, description, certificate number ... And in not more then a few minutes everything was in my views without problems. So thanks again!!
Comment #62
henkit CreditAttribution: henkit commentedHi,
Just installed #52, working like a charm now! :) Thanx so much!!!
Henk
Comment #63
Summit CreditAttribution: Summit commentedYep https://drupal.org/node/1428272#comment-7349918 worked!
Setting this to RTBC ok?
greetings, Martijn
Comment #64
franzThanks for all the work!
I'd love to have a test for it though.
Comment #65
sphankin CreditAttribution: sphankin commentedHi,
I've been getting the SQLSTATE[HY000]: General error: 1366 Incorrect string value: '\x92t message in my logs when feeds is trying to process a mail message from mail handler.
I've worked out that in the text the word don't is stopping it from working properly because of the'.
I've tried implementing the patch as suggested above but that still doesn't seem to work.
Also I'm not sure where the GUI as printscreened above is to change the source file encoding?
Thanks in advance.
Comment #66
msti@sphankin The screenshot above shows the import form located at import/name_of_importer
If you dont see the options in the screenshot, the patch is not applied properly. Here is how to apply patches: https://drupal.org/patch/apply
Comment #67
sphankin CreditAttribution: sphankin commentedHi @msti, thanks for the reply. I've followed the patch instructions and I still can't see anything/it isn't fixing the issue. As far as I can tell (looking through the patch) the patch is being applied properly. Would it make a difference if I'm importing an email instead of a CSV file? Thanks.
Comment #68
13rac1 CreditAttribution: 13rac1 commented@spankin: this is only for the CSV parser.
I'll be able to look into writing a simpletest later this month.
Comment #69
sphankin CreditAttribution: sphankin commented@eosrei - thank you, that would be great!
Comment #70
sphankin CreditAttribution: sphankin commented@eosrei - Hi. Any development on the email parser?
Thanks,
Sam
Comment #71
13rac1 CreditAttribution: 13rac1 commented@sphankin: This patch is only for the CSV parser. I don't have time/need to work on the email parser. Please create a separate feature request issue for email functionality. I still hope to be able to implement the needed simpletests for this patch, but it is feature complete as is.
Comment #72
franzI used this patch with success on a project. I'm seriously just waiting for tests to commit it.
Comment #73
twistor CreditAttribution: twistor commentedWhat franz said, needs tests.
Comment #74
Rosamunda CreditAttribution: Rosamunda commented#52 WORKED FOR ME! THANKS!!!
Comment #75
acouch CreditAttribution: acouch commented@franz or @twistor, could a test just involve adding international characters to one of the csv files in feeds or should it have its own test?
Comment #76
franzIdeally, we should have an individual assertion that verifies if the code works well with the encoding. What matters most is to make sure the tests appropriately cover the possibilities and provide an easy output in case it fails. That's my take on it at least.
Comment #77
HeathN CreditAttribution: HeathN commented#52 is the way to go. Thanks for this patch. What is the status on getting this into the next build?
Comment #78
acouch CreditAttribution: acouch commentedIf someone can provide a file or files that works only with the new conversion that they would be comfortable being added to the project I can write the assertion.
Comment #79
aimeerae#52 worked for me. Thank you for the patch!
Comment #80
Summit CreditAttribution: Summit commentedHi,
Anyone up for the tests? Than I think this can be committed, right?
Greetings, Martijn
Comment #81
franzSo all we need is a CSV file with non utf-8 encoding to test the feature. If someone can provide, then acouch writes the assertions and we commit.
Comment #82
acouch CreditAttribution: acouch commentedI found that the patch in #52 does't allow the encoding settings to be changed on a per-node basis. I added
$form['encoding']['#default_value'] = isset($source_config['encoding']) ? $source_config['encoding'] : $form['encoding']['#default_value'];to the sourceForm which fixed this. Didn't get a chance to test this, so setting to 'needs review'. Will reset if the test passes and will still wait for a file to write test encodings.
Comment #83
13rac1 CreditAttribution: 13rac1 commentedThis should be "Needs Work" until tests are written. I've got three higher priority projects in front of the project needing this, so I cannot work on it.
Comment #83.0
13rac1 CreditAttribution: 13rac1 commentedFixing screenshot
Comment #84
BrightBoldPatch in #52 solved the problem for me as well. (Sorry I didn't test #82 — I was short on time and didn't need the additional functionality it offered so I went for the earlier one with proven success). Wish I could write tests to help get this committed — it's great!
Comment #85
liquidcms CreditAttribution: liquidcms commentedsomewhat related but maybe needs a new issue:
if the column headings have non standard characters (mine have french characters) then that column is skipped on import.
Comment #86
liquidcms CreditAttribution: liquidcms commentedhmm..as i mentioned in #39 above:
i was getting the import to crash when it would encounter a non-english character. the path in #52 fixed it from crashing; but it is simply removing those characters. that is certainly not a solution.
Comment #87
liquidcms CreditAttribution: liquidcms commentedughh!! at a bit of a loss with this... as i mentioned in #86 (and #39) i have the patch from #52 and my import no longer crashes on FR characters; but they get dropped.
I have looked in to the code a bit more and this is making less sense the more i look.
taking the code from the patch i do this in a devel/php window:
and the result is: Date entrée
but, when i use a debugger and step through the same code in the feeds function: fixEncoding()
after running mb_convert_string() the character are lost; exactly as occurs when doing the import.
my guess is this has something to do with the devel/php having some html encoding possibly in the mix that the import function doesn't have; but also confused why so many people seem to be having success with the patch in #52.
is it possibly due to using PHP 5.3 instead of PHP 5.4?
Comment #88
liquidcms CreditAttribution: liquidcms commentedi admit i do not understand all the aspects of dealing with other character sets, but i ran these tests to show if the issue is PHP version dependent.
running a test file via php on command line (Windows)
i set this as my test file:
results are:
i am sure the ? is just a display issue with the command shell; but it is clear that PHP 5.3 and PHP 5.4 act differently
i'll set up PHP 5.4 for the web server and try the CSV import to be sure.
Comment #89
liquidcms CreditAttribution: liquidcms commentedfixed. in the fixEncoding function i replaced this line:
$data = mb_convert_encoding($data, $this->to_encoding, $detected_encoding);with this one:
$data = utf8_encode($data);Comment #90
13rac1 CreditAttribution: 13rac1 commented@liquidcms utf8_encode() only converts a string encoded in ISO-8859-1 to UTF-8. It doesn't cover any other conversions
mb_convert_encoding() converts between any listed encoding and is multi-byte string capable. See: http://www.php.net/manual/en/function.mb-convert-encoding.php
While this code may need some help, utf8_encode is not the answer. Sorry.
Comment #91
liquidcms CreditAttribution: liquidcms commented@eosrei thanks for the info.
i do not doubt what you are saying; but utf8_encode does work. :)
also the code in the patch: mb_detect_encoding($data, $this->from_encoding) returns utf8 for my data (not iso-8859-1)
and mb_convert_encoding certainly does not work (although, as i have said, perhaps it is only busted for < php 5.4).
Comment #92
祥子 CreditAttribution: 祥子 commented82: feeds-encoding_support_CSV-1428272-82.patch queued for re-testing.
Comment #93
13rac1 CreditAttribution: 13rac1 commentedSetting issue status back. No need to test until tests are written.
Comment #94
rcodina CreditAttribution: rcodina commentedThe patch in comment #82 works for me with these php versions:
5.3.10-1ubuntu3.10
5.2.17
I had no need to use "utf8_encode" instead of "mb_convert_encoding". I think "mb_convert_encoding" works really well here. However, I had to specify the exact charset of my CSV file to get it to work (in CSV parser configuration form). The "auto" option doesn't work for me.
I really think this patch must be put on recommended release ASAP because this is a key feature for a lot of Drupal sites in spanish, french, german, etc
Thank you so much!!!
Comment #95
cgdrupalkwk CreditAttribution: cgdrupalkwk commented#82 worked great for me.
Comment #96
Niremizov CreditAttribution: Niremizov commented#82 , #52 - "Check encoding" checkbox is not optional. This checkbox is badly needed, because there is not guarantee that string encoding would be determined properly with mb_detect_encoding() function.
The problem is that mb_detect_encoding() returns the first character encoding sheme that it determines. What this leads to?
Example: File contains multi language strings and uses Windows-1251 (CP1251) or any other character encoding sheme, that is compatible with ASCII (same codes for English chars). If first char in the processing string is English, then mb_detect_encoding($data, 'Windows-1251') - returns FALSE, because it detects ASCII first.
But mb_check_encoding() - works better in this case.
Comment #97
Niremizov CreditAttribution: Niremizov commentedAttached patch in addition to #96 comment.
Comment #99
barryvdh CreditAttribution: barryvdh commentedPatch #82 does seem to fix my import issues with the latest dev version. Any reason this isn't merged yet?
Comment #100
MegaChriz CreditAttribution: MegaChriz commented@Barryvdh
Yes, a test should be written for this issue. After that it is probably ready for commit. See also comment #81.
Comment #101
jtsnow CreditAttribution: jtsnow commentedHere is a patch that includes some tests.
Comment #102
acouch CreditAttribution: acouch commentedComment #104
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedI found a few minor issues with this patch: coding standards and php notices on the csv parser settings page when the extension mbstring is not available. I'm working on fixing these and I also write a test to cover the behaviour when the mbstring extension is not available. Other then that, I think everything works OK. Great work everyone!
Comment #105
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedIn comparison with the previous patch, this patch doesn't change the base functionality, but it fixes minor things (coding standards, php notices) and adds an extra test.
Details:
ParserCSV::fixEncoding()has been renamed toParserCSVEncodingExceptionso modules that extend the CSV parser can easier distinguish which exception they receive.FeedsCSVParserTestCasehas added that tests the CSV parser in the UI. It has two test methods: one to test behaviour when the mbstring extension is not loaded and one to test that import is halted when a CSV file in the wrong encoding is supplied.I think this is ready.
Comment #107
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedApparently, items with encoding issues can not be processed during a test without test failures because in < PHP 5.4 that will result into the following error:
(I work with PHP 5.6 locally, so I did not get the test failure there.)
I've worked around this by emptying the list of items to process after parsing for the test that was failing (which was
FeedsCSVParserTestCase::testMbstringExtensionDisabled()). The processing part is not relevant for that test anyway. The list of items will not be emptied in all other tests.In comparison with the previous patch only test fixes are added.
Comment #108
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedReroll of the patch in #107.
Comment #109
twistor CreditAttribution: twistor as a volunteer commentedWhy is this private?
the extension_loaded() and variable_get() calls should be moved to the constructor, so they are only checked once.
from_encoding and to encoding should be camelCase.
to_encoding and from_encoding should be checked that they aren't the same value.
Comment #110
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedThe method
ParserCSV::fixEncoding()was made private by OnkelTem in #6, but I can not see a particular reason for it in that comment. I made it public now.I also fixed the other concerns of #109.
Comment #112
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedThe encoding should be checked even if "fromEncoding" is equal to "toEncoding".
Comment #113
hargobind#112 works great on my custom import. I only tested this to convert from Windows-1252 (ANSI) to UTF-8, but I don't see any reason why it would fail for any other conversions.
Comment #114
MegaChriz CreditAttribution: MegaChriz as a volunteer commentedCommitted #112. Thanks all!
Comment #117
mikeytown2 CreditAttribution: mikeytown2 commentedIf you wanted to support auto utf-8 translation of the encoding there is this https://github.com/neitanod/forceutf8
Also came up with this which seems to work for my use case.