
Problem/Motivation
The class Attribute is used in drupal to collect and render html attributes. It applies 'htmlspecialchars'(inside check_plain) to everything. It modifies the value of any attribute that may contain one of the five special characters(&,',",<,>). The purpose is to allow these characters to be displayed on the page but not treated as markup in the document. But drupal's blanket approach has the side affect of eliminating the use of 'numeric character references'(NCR's). These are identified by a prefix of '&#', a decimal or hexadecimal number N that maps to the unicode character set, and a suffix of ';'. NCR's are legal html markup and are supported by all mainstream browsers(though some older implementations were poor, eg. IE6). By converting the '&' in the NCR to '&, check_plain destroys the NCR.
This has stopped #1836160: Support icon fonts in menu links. That issue uses the 'data-*' attribute to display iconic characters from an icon font in menu links. The patch there retrieves and properly saves the attribute, but when the link is to be printed to the document a call to Attribute ends up in modifying the string and destroying its value as an NCR.
Solution
The solution is to filter out NCR's from being processed by check_plain in AttributeString.php









{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
dcrocks CreditAttribution: dcrocks commentedMy concern is just with menu links. But these attributes can be added to any html element. 'Attribute' is called from 88 different places in drupal and seems the logical place to address this problem. I think security issues with attributes are addressed separately and not an issue in Attribute itself. Because of its common use I think any change to Attribute deserves discussion.
Comment #2
dcrocks CreditAttribution: dcrocks commentedWould it be better if only the 'title' attribute went through check_plain?
Comment #3
sunEvery HTML attribute has to go through
check_plain()/htmlspecialchars().I do not see a patch in the referenced issue, so I'm not able to clarify any further.
Comment #4
dcrocks CreditAttribution: dcrocks commentedPatch on my issue available
Comment #5
Damien Tournoud CreditAttribution: Damien Tournoud commentedThe attributes in question are supposed to be plain-text and have to be encoded on output. There is no reason to change that.
Comment #6
dcrocks CreditAttribution: dcrocks commentedBut they aren't. A 'numeric character reference' is a legal html encoding. It is not plain text. Please see Character references . Yes, all attributes are printed to the page. But no, most aren't displayed on the screen. What is the basis of this rigid requirement for check_plain?
Comment #7
dcrocks CreditAttribution: dcrocks commentedThere are 3 properties that a 'numeric character reference' can tested on:
They start with &#.
They can end with a semicolon. Html doesn't require that but drupal can.
They have a maximum length of 8 characters. That is an inferred property but drupal can enforce it.
Comment #8
Damien Tournoud CreditAttribution: Damien Tournoud commentedThe data that is fed to the Attribute class is plain-text, that's by design.
In your particular case, you just need to output a single unicode character, technically you don't even need character references to do that.
Comment #9
dcrocks CreditAttribution: dcrocks commentedNo, that is not the case. Not only is it very unintuitive but to also best support accessibility characters from the PUA(unicode Private Use Area) should be used for inserting icons into menus. And where does it say in the world of html that all html element attributes have to be plain text? I haven't heard a case made yet.
I have a patch and it is a hack, but unless you want to restrict numeric character references to menu links it seems the best way at this time. I also made the title more descriptive.
Comment #10
dcrocks CreditAttribution: dcrocks commentedThe definition of numeric character references(NCR) from the HTML2 spec:
numeric character reference
markup that refers to a character by its code position in the document character set.
The syntax hasn't changed since then. As far as I can tell to find a browser that has difficulty supporting these you have use one predating Netscape 4.5. If these are not supported in drupal then drupal does not support the html spec.
I am sorry if I sound frustrated but I do not understand nor have I been given a reason as to why NCR's can't be supported in drupal. If there is a better way, please tell me, but don't just exclude them without comment.
Comment #11
dcrocks CreditAttribution: dcrocks commentedI have produced a better summary and also changed this to a bug, which is a better categorization. I also need to modify the filter because unicode is bigger than I thought.
Comment #12
sunComment #13
dcrocks CreditAttribution: dcrocks commentedHow can I argue with this designation. My issue #1836160: Support icon fonts in menu links is a feature request but this is a bug by any reasonable definition. I cannot even implement this capability in contrib in 8.x. Drupal 8.x does not correctly support the html 2, 4, 5, or 5.1 spec. Please read the summary again.
Comment #14
dcrocks CreditAttribution: dcrocks commentedMaybe a title change will make it look less like a feature request.
Comment #15
dcrocks CreditAttribution: dcrocks commentedHere is a new patch that might make people happier.
Comment #17
dcrocks CreditAttribution: dcrocks commentedSigh
Comment #18
sunHTML entities can appear anywhere in a attribute value string.
Comment #19
dcrocks CreditAttribution: dcrocks commentedYou're right. I suppose I can think of a few use cases for (multiple)embedded NCR's. This is about NCR support in drupal, not one use case. Going to have to rethink this.
Still think this is a bug, NCR's aren't exactly new.
Comment #20
dcrocks CreditAttribution: dcrocks commentedPossible values sent to Attribute are:
1) A string with one or more embedded html entities. They are not necessarily contiguous and if the entity is at the end of the string the trailing ';' is not required by the major browsers.
2) An array of strings, each with the characteristics of (1).
For the definition of an html entity I am using List of XML and HTML character entity references and Numeric character reference .
Comment #21
dcrocks CreditAttribution: dcrocks commentedA new patch that accounts for multiple html entities in an attribute, It uses preg_match_all to parse the attribute string and then, if a html entity is present it preserves the leading & while check_plain;ing everything else. It basically processes the attribute in chunks, if need be. I did a lot of experimenting on input strings.
If it receives an empty string it outputs an empty string.
If the input string(or string chunk) has no embedded entity, just check_plain everything.
html entities will be individual chunks. The & is preserved and the remainder run thru check_plain. If someone accidentally(or on purpose) inputs a string that looks like an entity(start with &, end with ;) it is still going thru check_plain. Current browsers don't seem to have any problems with strings that have the syntax of an entity but aren't really.
It is all stitched together at the end. One thing to note is that current browsers don't seem to mind if a NCR doesn't end with a ';' when passed in a css 'content' phrase, but this code enforces that. If you, for example, enter a '' as an icon font character it will output '&#028', which will not be interpreted as a NCR, though I know that '' works.
Comment #23
dcrocks CreditAttribution: dcrocks commented#21: 1930322_21_Support_for_HTML_entities_in_HTML_element_attributes.patch queued for re-testing.
Comment #24
dcrocks CreditAttribution: dcrocks commentedDidn't change anything. Didn't see how my patch interacted with he failing test.
Comment #25
dcrocks CreditAttribution: dcrocks commentedDid some tweaks for some special cases.
Comment #26
thedavidmeister CreditAttribution: thedavidmeister commented#25 - This patch needs work:
1. No documentation - You can't just throw a regex like that in and not provide at least an inline comment as to what you're trying to achieve. The vast majority of people who would see this code would not be able to skim read it and understand what it does and why - it took you a few days to get the regex right so that should indicate that a comment is in order if nothing else does.
2. Performance - This Attribute class can easily be used hundreds of times in a page load. check_plain() is fast but I had a quick google for preg_match_all() benchmarks and found this http://maettig.com/code/php/php-performance-benchmarks.php which indicates it is rather slow compared to other regex and string matching functions. Whatever we do in this patch, we need to keep generation of Attributes as fast as possible so I think we should try to provide an alternate way to scan for & characters that doesn't rely on a regex if possible, or if that *really* isn't possible at least does a fast scan for & characters with strpos() and then uses a heavier regex to pinpoint their location only after one is found.
3. No tests - In #20 and #21 you've done a good job of methodically describing what you're trying to achieve, these things all need to be translated into tests so the testbot can verify that the patch is working as expected, especially if further tweaks are to be made.
4. Coding Standards - The patch introduces code that doesn't meet Drupal's basic coding standards. There is incorrect indentation, new lines (or lack thereof) and whitespace throughout the changes that you've made. Please carefully review http://drupal.org/coding-standards as (and I mean this in the politest possible way) it should be trivial to get this right in a 10 line patch - there are Drupal-specific automated tools that can test this for you such as http://drupal.org/project/coder.
5. No interdiffs (http://drupal.org/documentation/git/interdiff). Even though your patches are small in terms of LOC, the logic within them is relatively dense and seemingly getting more so with each new revision. It would certainly help others review your code more efficiently if you were to provide an interdiff.txt file (it won't be sent to the testbots) alongside your patches so we could see at a glance exactly what is changing each iteration.
Comment #27
Damien Tournoud CreditAttribution: Damien Tournoud commentedSorry, but no. This is by design.
In Drupal, a string can be one of two things:
If it's plain-text, it's plain-text, if it's HTML, it's HTML. There is no such thing as an in-between.
HTML attributes (ie. things you store in the
Attributeclass) are always plain-text in Drupal. This is the right thing to do, because attribute values in HTML are *always* text (as described in section 8.1.2.3 of HTML5). When output in an HTML context, those attribute values can contain character references, but that's just because some characters *have* to be encoded in HTML (most notably,&<>).There is *nothing* you cannot do with the current system. You can already output *any* character, including those that are private usage.
Comment #28
Damien Tournoud CreditAttribution: Damien Tournoud commentedAlso, I already explained to you that if you want the user input (ie. the stuff that the user puts in the UI) to be an character entity (not that it is a good idea), you *can* just pass it to
decode_entities()to make a plain-text string out of it. This will output the proper character in the HTML string, and will result in the proper display.Comment #29
dcrocks CreditAttribution: dcrocks commentedRe #26:
I chose 'preg_match_all' because it gave me every chunk in 1 call. I could add a test so that it is only called if the attribute input string contained any ampersand characters. If this goes any further I can address all the issues you pointed out but I will probably need help with the test system.
re: #27 and #28:
What I saw in the standard 8.1.2.3 Attributes is
Attribute values are a mixture of text and character references, except with the additional restriction that the text cannot contain an ambiguous ampersand.
So it isn't a HTML standard, but rather you are stating it as a drupal standard. And as it stands, no, I cannot output anything in drupal. I certainly can't from the menu system.
Yes, I could try to hook in at the last minute to try to find something that should be an html entity and run decode_entities() on it. But that seems very inefficient and inflexible to decode these values from the back instead of at the front. The code I propose supports any html entity, not just NCR's. It would allow me to use a multitude of special, html legal, symbols, eg. 'registered trademark' in my output with ease as well as adding a flexible way to support iconic menus.
Finally, what I am proposing can make drupal more user friendly. If the cons outweigh the pros, so be it. But, I would like someone to point out to me in the documentation where it says drupal does not support html entities. If it doesn't, it should.
Comment #30
dcrocks CreditAttribution: dcrocks commentedYou can close it again, but I do want at least one more comment.
Comment #31
Damien Tournoud CreditAttribution: Damien Tournoud commentedYou are stating your problem wrong. You don't *need* HTML entities in your use-case at all. HTML entities are a mean, not a end.
What you want is to output some Unicode character. You can do that. You have always been able to.
Comment #32
dcrocks CreditAttribution: dcrocks commentedI want to save a unicode character in the attributes of an anchor element in the drupal database. Drupal encodes it before storing it. Where do I tell drupal to decode it when it is read from the database before it is given to the browser.
Comment #33
thedavidmeister CreditAttribution: thedavidmeister commented#31 and #32 make this issue look like a support request rather than a feature/bug, assuming that Drupal does indeed handle unicode correctly as stated in #31.
dcrocks, could you provide a copy of the code you're working with that exhibits the issue? See if we can't find a way to get it working the way you want :)
Comment #34
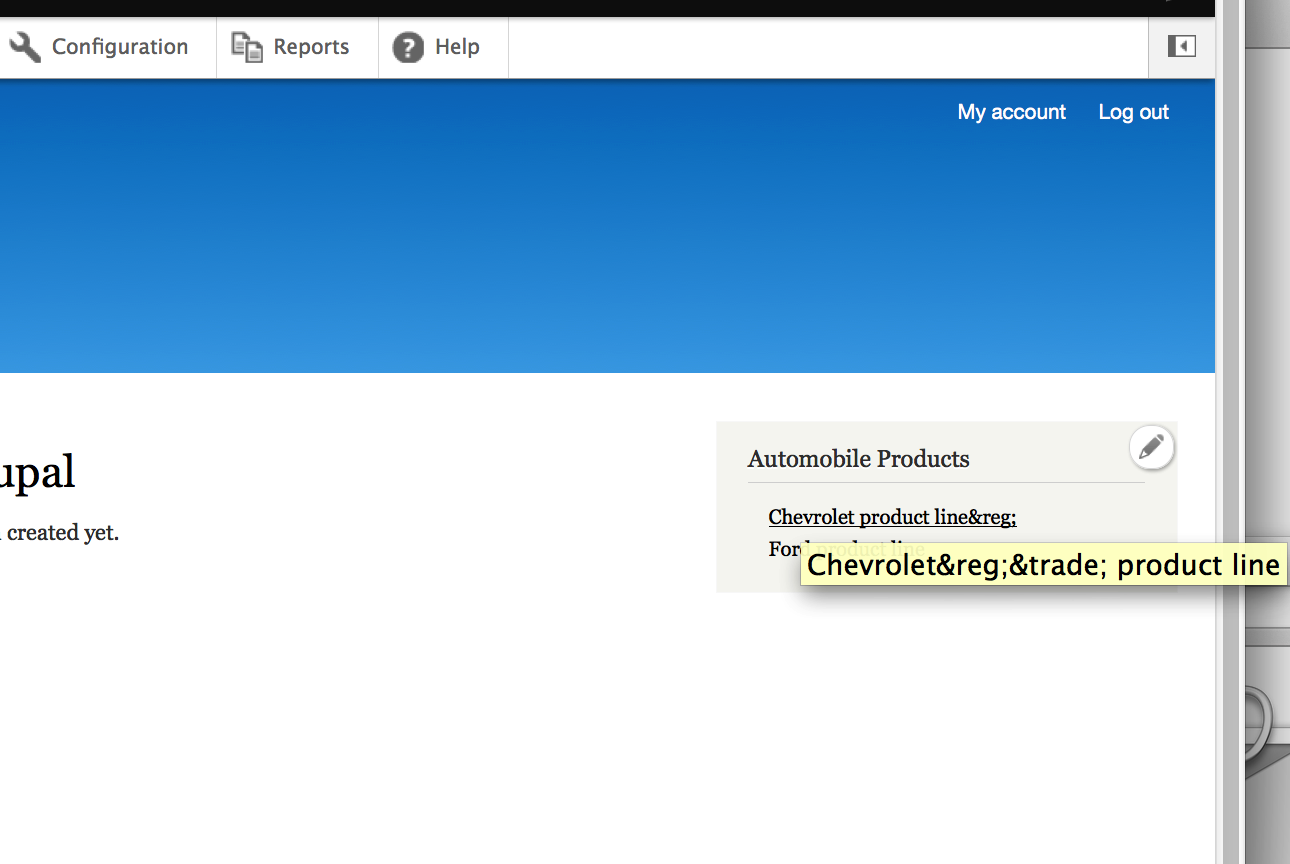
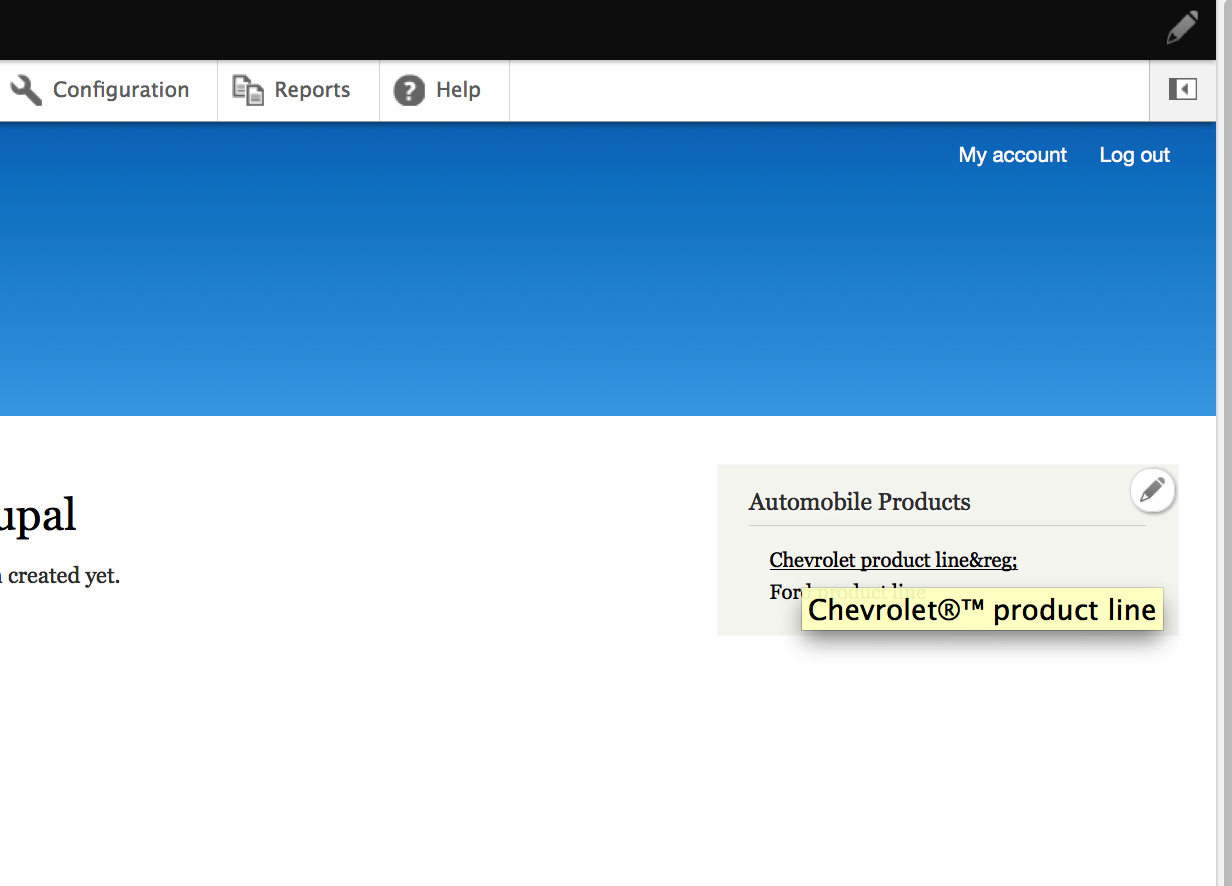
dcrocks CreditAttribution: dcrocks commentedThis started out because of #1836160: Support icon fonts in menu links. I cannot implement that because drupal runs all attributes through check_plain. I know that I can select 'full html' when creating content and that will allow the retention and display of html entities. However, if I were to enter any html entities in a menu attribute check_plain would make the string unusable as a html entity. A simple test is in 'add content' and 'menu' edit. Each attached image shows output after drupal processes them. If, in my case, I added a field to the menu edit title attribute to save a character entity reference, check_plain makes it unusable. Instead of being saved as '&#f00a' it is saved as '&#f00a'.
So this only deals with html entities in attributes and the particular use case is menu item attributes. Whether or not #1836160: Support icon fonts in menu links goes anywhere it also means I can't implement this in contrib as well. Yes, I can find a way to modify menus but not as a modification to drupal forms.That just seems less efficient and flexible to me. It also means I can't build any menu items with embedded special characters, such as ™ .
Comment #35
dcrocks CreditAttribution: dcrocks commentedI guess I could have said it simpler, because the updated issue title does. The code in #1836160-17: Support icon fonts in menu links displays the problem. I don't want to argue over the relative merit of creating iconic menus thru classes in markup with css or using the data-* markup with css here. The point is drupal does not allow html entities in html element attributes.
Comment #36
dcrocks CreditAttribution: dcrocks commentedJust to clarify, there is no problem storing html entities, just when they are loaded to the page.
Comment #37
dcrocks CreditAttribution: dcrocks commentedI did some timing on the code and soon realized that multiple calls to check_plain in a loop wasn't productive. So I reversed the logic and used preg_replace_callback to reconstruct the attribute string. I'll show some timings in another post.
Comment #38
dcrocks CreditAttribution: dcrocks commentedI did some timing on the code in #37. The description follows. With the change the timing is basically additive, ie. the time for check_plain and preg_replace_callback plus a little interpreter overhead. Note that preg_replace_callback takes basically the same time as check_plain if no html enities or character references are present. So best case, and probably the most common one, is that time has doubled. Case 5 is a worst case scenario and pretty unrealistic, because I think the current maximum 'Title' length is 512 characters. Adding support for html entities and character references in html attributes will cost, but I don't think it is prohibitive.
I ran it on my 2009 Mac Pro(2.8 ghz quad core) which is always running as a low activity web server as well as my coding/test machine. I wrote php test scripts which I ran in a Terminal window. I used 'microtime' to bracket a 'while( $i < 1000 )' loop. This is clock time, not cpu time, but probably close enough. I had 3 scripts,
(A) just check_plain as it is done now
(B) preg_replace_callback only
© check_plain and preg_replace_callback together as they would be in drupal.
I had 5 use cases:
(1) A 8 character string containing a NCR, eg. an icon character(my personal test case).
(2) A 39 character 'Classs' attribute string that had no embedded html entities or character references.
(3) A 45 character 'Title' attribute string with no embedded html entities or character references.
(4) A 45 character 'Title' attribute string with 2 embedded character references.
(5) A 1024 character string with multiple embedded html entities and character references.
Comment #40
dcrocks CreditAttribution: dcrocks commented#37: 1930322_37_Support_for_loading_unicode_characters_for_display_in_HTML_element_attributes.patch queued for re-testing.
Comment #41
dcrocks CreditAttribution: dcrocks commentedJust to clarify, the times in #38 are average times, not total.
Comment #42
thedavidmeister CreditAttribution: thedavidmeister commentedI'm not sure that *at least* doubling the time spent in attribute generating functions will fly given the current state of performance in D8...
Check what I said in #26 about how l() works:
Could you do something similar, like:
Regardless, maybe I'm missing something, but if you're decoding HTML entities for display doesn't that undo the sanitisation work done by check_plain()? What happens if I stick
alert('foo')into an attribute after applying one of the patches in this thread? Will it be printed or filtered?
Comment #43
dcrocks CreditAttribution: dcrocks commentedYes, that is a good suggestion. I actually did that earlier but somehow dropped it when I flipped the logic. This should be no less sanitized than before. The code looks for the &...; pattern, which identifies all html entities and character references, and only replaces the html entity & with & when that pattern exists. Any embedded <,>,',etc. are still sanitized as before. Everything in the attribute string is sanitized before the preg_match_callback is called and only the html entity for & is replaced if the pattern matches. Html entities and character references in attributes are legal according to the w3c and I don't see how this output is less secure than previously.
I will redo the patch with your suggestion, as well as my timings.
Comment #44
dcrocks CreditAttribution: dcrocks commentedHere is a revised patch. Script 'C' in timing tests was revised to reflect the new code and only it shows changes. New timings are:
Comment #45
dcrocks CreditAttribution: dcrocks commentedI managed to create an example to show the difference the patch made. I created a custom menu and added character entity references to the 'Description' field. This is the easiest 'attribute' field to work with. The attached images show the affect with and without the patch from #44. This patch supports legitimate attribute content. check_plain() is still run on everything plus the 'title' attribute is still run through strip_tags in l(), so I think the output is as well sanitized as before.
Comment #46
thedavidmeister CreditAttribution: thedavidmeister commentedThanks for doing a bit of benchmarking, however as per #26:
- The whitespace/indentation in the patch is not right, look at the oddly positioned return nested in the if()
- This functionality needs comments explaining what is going on
- Uploading a couple of png screenshots isn't enough, we need actual tests that can be run by the testbots to demonstrate and validate the patches for the issue
- Providing interdiffs for each patch would be great too :)
I'm going to tentatively set this back to a feature request but against the menu module rather than Drupal itself as:
- There's been no word from Damien in 2 weeks on how to achieve this with the current menu system.
- The problem seems to be a combination of the way the menu system saves data and the Attribute class, not necessarily just an issue with Attribute itself.
Comment #47
dcrocks CreditAttribution: dcrocks commentedThanx for the response. I'll start work on your points. But there is no problem with how the data is stored, but with how it is processed before rendering. The basic issue is the blanket application of check_plain on element attributes. This is the situation in drupal 7 as well but there the pertinent function is drupal_attributes() instead of Attributes(). Each is called in their respective implementations of the l() function.
Sorry, actually each is called in many places.
Comment #48
thedavidmeister CreditAttribution: thedavidmeister commentedSo, the problem is that check_plain is double encoding things? I'm sorry, I'm still not 100% sure exactly where in the chain of input -> saving -> loading -> displaying the characters are getting mangled. I haven't actually tested this manually yet, I've just been going on your description on the situation.
I'll fire up a sandbox D8 in a minute but would it be enough to change:
to:
so that you never get to the
&foo;stage in the first place?Comment #49
thedavidmeister CreditAttribution: thedavidmeister commentedYeah... that works for me. No idea what the repercussions outside this issue are, but it definitely got
®to display in a menu title for me.Comment #51
thedavidmeister CreditAttribution: thedavidmeister commentedUgh, that failed test is explicitly looking for raw double-escaped output #829484: Uncaught PDO Exception - XSS. It was mentioned in the comment thread that this was undesirable so I think it's a red-herring here - I've modified the test to look for a single-escaped output string instead.
Comment #52
thedavidmeister CreditAttribution: thedavidmeister commentedI added a basic test for not double-encoding entities in check_plain().
Comment #53
dcrocks CreditAttribution: dcrocks commentedNow I really feel stupid. Yes, the double encode flag will do it. I was going to add a test to MenuRouterTest.php.
Comment #54
dcrocks CreditAttribution: dcrocks commentedDidn't mean to change the status.
Comment #55
dcrocks CreditAttribution: dcrocks commentedOr this
Comment #56
thedavidmeister CreditAttribution: thedavidmeister commentedFeel free to re-roll #52 with your test in it. More coverage can only be a good thing :)
If you could run your benchmark scripts over #52 again so we can compare, that would be nice too.
Comment #57
dcrocks CreditAttribution: dcrocks commentedWhile I work on a new patch here are some timings. Script (A) is check_plain as currently implemented and script (B) is check plain after adding the 'FALSE' flag to stop double encoding.
As you can see, only the unrealistic case 5 showed any meaningful difference.
Comment #58
dcrocks CreditAttribution: dcrocks commentedSo here is a new try. Since the only change was on the tests I did the interdiff there.
Comment #60
dcrocks CreditAttribution: dcrocks commentedSilly error. I'll redo later but in meantime I have been looking at all the places check_plain is called and there may be some where double_encode = TRUE should be used. Perhaps check_plain should be modified to pass the value desired for double_encode, defaulting to TRUE?
Comment #61
dcrocks CreditAttribution: dcrocks commentedThis is a new patch along the lines of #60. It only adds the one test for now and only modifies one place where check_plain is called. This will give a chance to look at the other 100 or so places where check_plain is called or if there are other test problems.
Comment #63
star-szrHate to be the bearer of bad news, but I think you'll want to look at these two issues before doing too much more work down the road of #48.
#882438: Globally prevent double encoding in check_plain() by raising minimum PHP to 5.2.3
#1630468: check_plain() double encoding
Comment #64
dcrocks CreditAttribution: dcrocks commentedI am not talking about using this everywhere, only on attributes. And in particular, my only interest is in menu link attributes. That's why I made the change I did. And this might not be the final form. Html entities are legitimate content for attributes and drupal already supports them in other content. I am not supporting user input generically but only what is available to administrators in drupal's administration system. Things are different today than they were 2½ years ago. Gee, I just used a character entity reference.
Maybe a less dogmatic review is possible.
Comment #65
dcrocks CreditAttribution: dcrocks commentedAnd some more clarification. I don't care if I can't put html entities in menu 'title' attributes, even though that is legal. I want to be able to add data-* attributes to menus and the most reasonable place(and the most common usage) to do that is in the anchor attribute field. But drupal processes that as a chunk.
I don't want to write 2 tons of css every time I want to iconify a menu, or part thereof, and I certainly don't want to maintain it. Maintaining an iconic font is hard enough. I want a flexible system that works as easily with 5 menus as with a 100. That is why I am putting so much time into this, even with my many errors. Visual menu objects are what people are used to and want. Menus aren't plain text anymore.
Comment #66
dcrocks CreditAttribution: dcrocks commentedApples to apples
Comment #67
thedavidmeister CreditAttribution: thedavidmeister commented#63 - thanks for the heads up. I thought it all seemed too easy ;)
#66 - that looks kind of cool, but I'm not sure it will go through simply because it will lead to inconsistent encoding/decoding behaviour across the API in general. From reading the other thread it sounds like at least Damien Tournoud and Sun believe the double-encode flag is a "hack" so you're kind of fighting an uphill battle there :/
Maybe check_plain() is just the wrong tool for this job since it *requires* that all strings passed to it are intended for rendering as HTML that displays exactly the same as the string, meaning wanting to put *any* HTML in there for rendering as HTML is never going to work.
dcrocks has pointed out that the HTML spec supports NCR in attributes so the requirements for check_plain() aren't really met if we're going to follow the spec instead of Drupal's current "by design".
Here's a patch that simply replaces check_plain() with filter_xss() in AttributeString and incorporates dcrocks' test from #66 (and passes it). Let's see if it passes the full test suite.
Comment #69
thedavidmeister CreditAttribution: thedavidmeister commented#64 -
Inflammatory remarks like this are uncalled for.
Comment #70
thedavidmeister CreditAttribution: thedavidmeister commentedah. filter_xss() allows a title like
' title="&"\'<>"'instead of' title="&"'<>"'... no good :/Comment #71
dcrocks CreditAttribution: dcrocks commented'Attribute' is called 94 times in core. A lot less than check_plain() of course. Still, a lot of places to examine consequences.
Comment #72
thedavidmeister CreditAttribution: thedavidmeister commentedfilter_xss(), "just the good bits" :P (also more tests)
Comment #73
thedavidmeister CreditAttribution: thedavidmeister commentedIgnore the last patch. The comments are stupid.
Comment #75
thedavidmeister CreditAttribution: thedavidmeister commentedComment #76
dcrocks CreditAttribution: dcrocks commentedTimings with code in #75: Script (B) now uses the safe decode function.
Comment #77
Damien Tournoud CreditAttribution: Damien Tournoud commentedSorry. Please re-read and understand #27.
Even the current title of the issue is wrong:
This is *already* supported, and has always been (at least since Drupal is 100% UTF-8, which it has been nearly forever).
Comment #78
dcrocks CreditAttribution: dcrocks commentedTry it. Show me. Put any character in a menu-link attribute and display it.
Comment #79
dcrocks CreditAttribution: dcrocks commentedBut I agree, the title is misleading. This is more specific.
Comment #80
dcrocks CreditAttribution: dcrocks commentedtypo
Comment #81
jwilson3It would be helpful to upload a version of the patch in #75 with *just* the tests, to prove that the tests fail with the test bot.
Comment #82
jwilson3also...
Why not move this micro-optimization directly into filter_xss()?
Comment #83
dcrocks CreditAttribution: dcrocks commentedIt seems to me that what #75 does is what htmlspecialchars with the double_encode = false flag does, only slower. check_plain() is a wrapper for htmlspecialchars. Why not put a raw call to htmlspecialchars in Attribute and avoid any api changes. It wouldn't be the only place in drupal.
Am I wrong or is Attribute used only for outbound data?
Comment #84
thedavidmeister CreditAttribution: thedavidmeister commented#78 - Damien isn't wrong, y'know. Just paste a © character directly into a menu link - it's only the html entities that are getting stripped out (which is still not great) but I think you should actually test what he's saying about unicode characters, they *do* work.
#81 - I've attached just the failing Attribute tests for html entities that we might want preserved in HTML attributes. Also a test that *already* passes for a unicode © symbol demonstrating what Damien is saying.
#82 - Seems fair, I've moved the strpos() check into partial_decode_entities_safe() so that it works for anything that calls it but it still seems relatively slow. I don't actually mind the approach in #66. check_plain() seems to be used in two related contexts atm:
1. "Escaping"/sanitising arbitrary strings that could contain malicious HTML before display in an HTML context
2. Ensuring a string intended as "plain text" renders literally as it was written in an HTML context
Please correct me if I'm wrong but I believe the former only ever needs to single-encode characters to ensure security (nothing bad came up in Google when I searched), whereas the second needs to encode every character that can be encoded. The $double_encode flag in #66 does allow check_plain() to work in both these contexts.
Comment #86
Damien Tournoud CreditAttribution: Damien Tournoud commentedWrong. The only use of
check_plain()is to render a plain-text string in an HTML context, aka (2).check_plain()is not (and has never be) a security mechanism, and it only accepts a plain-text string as an input. It doesn't (and has never) (and should not) accept a HTML-ish string as an input.Guys you are just running in circles here. There is plain-text and there is HTML, there is *nothing* in between. Please stop trying to invent it.
Comment #87
Damien Tournoud CreditAttribution: Damien Tournoud commentedI already explained in the other issue that if you have a string containing an HTML entity (for example
), it is *trivial* to convert it into a plain-text string containing this Unicode character:Comment #88
dcrocks CreditAttribution: dcrocks commentedre #87 I see what you are saying, but so far all I have had to do to iconify menu links is to modify an admin form so that the value is saved with the link and added some css. I haven't modified drupal's menu processing in any way. I do think whatever processes drupal adopts to support icons systematically will probably end up modifying the html generated for menu links, if nothing else than to support aria roles and attributes.
Also I don't think that this is an issue about mixing plain text and html because I don't think character references themselves are considered to be html. The definitions I have seen roughly state that, in HTML, XML, etc., character data and attribute values consist of 2 things: (1) character that can manifest themselves directly, or (2) by a series of characters called a character reference.
I am still trying to find out why double_encode is considered a hack, or what kind of a hack it is supposed to be. Perhaps someone can point me to that. Looking at the code implementing htmlspecialchars there are things that are done only if double_encode is FALSE. These include verifying numeric character references are valid numbers and that character entity references are of a proper length and are valid names.
Comment #89
thedavidmeister CreditAttribution: thedavidmeister commented#86, #87 - that's all fair enough. I'm convinced :)
So basically, the official line atm is "if you want to use characters that are represented by HTML entities in plain text strings, never try write the entity yourself, always use the character as-is and let the encoding happen if it needs to". That makes sense.
Really? I was under the impression that it protect against XSS attacks when plain text is used in a HTML context :/
#88 - I don't understand what you're saying. You can use HTML entities in attributes, just make sure they're "fully decoded" into UTF-8 (using the existing Drupal API) before you try to have them rendered by Attribute. If you want to reopen this thread, please provide the *exact* data attribute are you trying to put on a menu link that you cannot get working, with a code example of what you're trying at the moment.
Damien explained why he believes the double_encode flag is a hack in both of the issues linked by Cottser in #64, it's not a mystery - http://drupal.org/node/882438#comment-3325226, http://drupal.org/node/1630468#comment-6109792
Comment #90
dcrocks CreditAttribution: dcrocks commentedWell, I did read those issues and found them less than convincing. There seems to be real confusion as to what character references are. They are not html. They are data. However, some of their data points are used programatically by html. Is 'section' html or is it a word? Is '<' html or a less than sign? I will leave this closed for now while I test out the model suggested in #87. I have to make sure that the character is pulled at the right time from the right font. I had hoped to not have to modify drupal code.
Comment #91
thedavidmeister CreditAttribution: thedavidmeister commented#90 - You don't have to modify drupal code, just save the symbol you want in UTF-8 on the menu item. I've tested it against the title and attributes for menu items on my local with a few different iconic unicode symbols and they all work. The approach of using decode_entities() is just an example of/shortcut to getting the character (since it's probably not on your keyboard) but there are lots of ways to get the character you need outside of decode_entities().
Comment #92
Damien Tournoud CreditAttribution: Damien Tournoud commentedI can understand this is a big one to swallow.
check_plain()by itself doesn't provide security. It is just a conversion mechanism from plain-text to HTML. When you output something in HTML, some characters (mainly<,>,"and') need to be escaped because they have a special meaning.check_plain()is about correctness, it's not about security. If you are not correct in what you output, browsers might misunderstand you and do something you would not expect. That's when the XSS issues comes in.When you have a plain-text string that you want to output in an HTML context, you have to use
check_plain(), even if the plain-text string doesn't come from user input.More context here: http://groups.drupal.org/node/280368#comment-884958
Comment #93
thedavidmeister CreditAttribution: thedavidmeister commented#92 - Indeed. I just tried
(string) new Attribute(array('onclick' => '$.noConflict();'))and got it back, lol.Never really thought too much about it but of course that would happen... learn something new every day :)
so check_plain() is more about not malforming your DOM and allowing malicious things *elsewhere* in the DOM from doing bad stuff than filtering out bad stuff from the string passed to check_plain()?
Comment #94
dcrocks CreditAttribution: dcrocks commentedJust some comments
1) If check_plain() is not about security, with which I agree, then a lot of comments in drupal code and the drupal api documentation should be modified.
2) The api document for drupal_decode() indicates it can be unsafe.
3) Correct output is all I want also, but I cannot get that from check_plain() without the double_encode set to false.
4) Character references are not html, nor are they entities, despite the unfortunate common labeling of them as html entities.
5) Processing a string with check_plain() with double_encode set to true produces a string where the only character references output are those for the small set of 'special' characters'(&<>'").
6) PHP is open source so it is easy to look at the source code. htmlspecialchars() looks pretty straightforward to me and setting double_encode to false actually adds additional validation logic for the values under consideration.
7) check_plain doesn't convert so much as it replaces. Using decode_entities() to put things back seems counter productive.
8) I want to provide a simple, generalized solution for adding icons to menu links. One that is not specific to a particular menu.
9) Double processing the source data could make that difficult to do. Not all menu links take the same path through drupal. I don't think that the primary or secondary links actually see l(), for example.
Finally, I don't see that turning off double encode in check_plain, at least in some specific places, diminishes the purpose of check_plain() as stated in #92, which is to produce correct output.
Comment #95
dcrocks CreditAttribution: dcrocks commentedJust to make the title correct as to what we are dealing with. It is unfortunate that the incorrect 'html entity' label has turned into common usage. Though I have to plead guilty also to that misuse.
Comment #96
dcrocks CreditAttribution: dcrocks commentedI'm going to open this one more time just ask for some common sense be applied here. It doesn't seem reasonable to me to decode something that shouldn't have been encoded in the 1st place. To repeat:
Check_plain() is just a wrapper for htmlspecialchars(). htmlspecialchars() is neither a hack nor black magic. Just look at the source code.
All check_plain does is replace any occurrence of a small set of characters that a browser might interpret as html with the corresponding character references. So check_plain is currently outputting character references and I don't see how that can be construed as mixing plain text with html.
Even though check_plain's purpose is not security, setting double_encode to false does add additional validation code to ensure that the character references examined are of the proper size and value to meet xml/html definitions of legitimate character references. Currently, filter_xss() allows both 'numeric character references' and 'named entities'(see code comments) but doesn't validate them.
htmlspecialchars() is much faster than any combination of preg_* statements. And the only concern are html element attributes, in which character references are completely legitimate. If there is concern about an api change then a raw call to htmlspecialchars() in Attribute would work fine.
Comment #97
thedavidmeister CreditAttribution: thedavidmeister commented#96 - I think the misunderstanding here is in what you're saying in #94.4 about character references not being HTML - maybe that's true but they still don't make sense outside of an HTML *context*, or more specifically they don't make sense in the context of "a string of Unicode characters".
I'm reading between the lines but I believe this is what Damien is trying to say in #86:
When processing a string we have to decide whether the (preprocessed) string is "plain text" or "text with markup" - there is no third option. We also decide whether the string is in plain text or HTML "context".
A plain text string is just a set of Unicode characters.
The concept of a character reference or 'html entity' or whatever you want to call it means nothing in the concept of a string of Unicode characters because Unicode is already an encoding scheme for all the characters we'd like to support (including "iconic" ones). That is to say, there's no characters that have awkward "character references" in Unicode where you have to combine combinations of other Unicode characters to create a new character - every character is just it's own entry in the list of possible characters and none have any kind of double or "special" meaning beyond the fact that they map something in binary to the human concept of a language "character".
A "text with markup" string is a set of UTF-8 characters where some or all of the string is intended as "special" or "meta" information (like HTML tags) for the "content", which is the rest of the string.
In HTML the meta information is generally denoted by these characters
<>'"&;and where these characters are "meta" they are not intended to be displayed, they are intended to be used as instructions by the browser. Additionally there is a whole set of characters (like ©) that don't exist in UTF-8 http://en.wikipedia.org/wiki/UTF-8. If we want to display one of the special characters or one of the characters not available in UTF-8 then HTML 2+ supports a set of "character references" that are interpreted by browsers that support character references (IE7+) as an instruction to display the referenced character in place of the character reference.In a plain text context, a string is just a string - For example, if we were to write a string to a system config file or to the database it's unlikely we want it to be modified in any way so both HTML and plain text strings are left as-is (strings of characters with no special meaning).
In an HTML context we are sending strings to a browser to be interpreted as HTML - we want markup strings to retain some or all of their "meta" information so we send it to check_markup() to filter out the bits we don't want, or to translate "alternate" markup schemes like Markdown or BBcode to HTML, the primary markup system supported by web browsers (note the function is called check_markup, not check_HTML).
We want plain text strings in a HTML context to *not* have any part of the string mistakenly interpreted as markup "meta" information, so we send it to check_plain() which adds markup to the string to ensure on a character by character basis that the browser (a markup interpreter) interprets the plain text characters as the same characters they were when they were still living inside a PHP string.
Turning double-encode off undermines the last example, a plain text string of
®is now being treated as markup for a ® symbol - but that's not what it is, it's still actually a string of 5 Unicode characters that mean nothing like ® outside of HTML. Turning off the ability to double-encode characters in check_plain() changes the fundamental definition of a plain text string from "A set of Unicode characters" to "A set of Unicode characters, where some combinations of Unicode characters are markup representing other Unicode characters".Having the double-encode disabled is considered a hack because the only use-case for it (in the world where you either have plain strings or markup strings) is to take a string that is neither of the two (partially marked up plain text string) and convert it to a markup string. In essence, you are inventing a third type of string that didn't exist before which is "partially marked up plain text string" - Damien, Sun and now myself are all saying this third option is totally unwanted as it will only muddy the waters when extrapolated beyond HTML Attributes to the entire Drupal platform. Security holes could appear, not because the processed "markup string" is insecure, but because having "partially marked up" strings with unclear encoding rules floating around is just asking for trouble.
tl:dr;
You have to choose whether your string is Unicode (in which case just put the unicode characters in the string as-is, copy and paste them from http://en.wikipedia.org/wiki/List_of_Unicode_characters if you have to) or "UTF-8 + markup including character references".
Strings passed to Attribute() (not to be confused with "strings that are HTML attributes" - that's the return value of Attribute()) are required to be the former. If you want a Unicode character to be displayed in your HTML attribute, send a Unicode character to Attribute().
This isn't about needing to decode/encode everything to the Nth degree before rendering a HTML attribute - If you want to send a string containing markup to Attribute() then you have to decode it to pure Unicode first, in the same way that if you want to send a string to a function expecting an array, you have to convert your string to an array first.
@dcrocks, you still haven't really explained why you can't just start with a Unicode string instead of starting with a string of markup. In response to #96 AFAICS it isn't Drupal inappropriately encoding/decoding strings, it's you who is providing strings in the incorrect encoding and expecting Drupal to guess how you want it to behave.
I'm going to postpone this issue until @dcrocks can outline a situation where providing a plain text Unicode string to an Attribute() object somewhere in Drupal (whether saving items through the menu system or otherwise) is *impossible* OR a situation where providing a plain text Unicode string to check_plain() doesn't allow exactly the same set of characters that are available through UTF-8 + character references when the output of check_plain() is sent to the browser.
Comment #98
dcrocks CreditAttribution: dcrocks commentedMy issue is the necessity to special case the processing of character references. First I have to determine that I need to use decode_entity. I then have to be careful that the right font family is in affect when the character is resolved by decode_entity. If I don't it will be set to the unicode replacement character. I am concerned that I can get consistent behavior with decode_entity if I can't find one point of execution for any menu link. If the attribute were preserved I only have to worry about the right font family being available through css. So yes, I want a easier, simpler way to do this. I can't say it is impossible to do this any other way.
I took a quick look at joomla and wordpress to see how they treat double_encode. I've never looked at their code before but I just looked for references to htmlspecialchars and double_encode. Joomla doesn't appear to use it though their is some raw code to process strings and character references but it appears to be mostly for input strings. Wordpress definitely uses double_encode but I didn't have enough time to see in what context.
I also looked at twig to see what it does. If you choose the html_attr context for 'escape' it seems to have the potential to output more character references than check_plain does.
My argument is that character references, in general, are as much plain text as the special 5. I only want to change the default for outputting attributes. I'll write code if I have to but to be honest I have the feeling that adding code to drupal to special case icons for menu links will be less acceptable than this request. And doing it through a contrib module makes menu icons second class citizens.
Comment #99
thedavidmeister CreditAttribution: thedavidmeister commented#98 - Why do you have to "determine that I need to use decode_entity" if you're using a Unicode string that already has the desired Unicode characters in it?
Comment #100
dcrocks CreditAttribution: dcrocks commentedYou're suggesting I use decode_entity in the form interface?
Comment #101
thedavidmeister CreditAttribution: thedavidmeister commented#100 - I'm saying start with the Unicode characters that decode_entities "decodes" entities to rather than starting with a "UTF-8 + NCR" string, then decoding it to Unicode, just so it can be re-encoded.
Eg.
1. go to http://en.wikipedia.org/wiki/List_of_Unicode_characters
2. copy a © symbol to your clipboard from the list (this is the Unicode © character, not the HTML
©character reference)3. Open up D8 and go to admin/structure/menu/manage/main/edit
4. Edit the "home" link
5. Paste your Unicode © symbol into the Description field
6. Save and visit the site's front page, hover over the Home menu item and you'll see that your © character is being rendered in the title HTML attribute - no extra code is required
Comment #102
dcrocks CreditAttribution: dcrocks commentedI don't know that I would recommend that procedure for the average user. And wikipedia won't have any listings for my icon font. But I'm not concerned with the 'title' attribute. That is just the easiest place to play without modifying drupal. But your suggestion is still good.
In the structure/menus/menu-link form interface, when a user enters a NCR for an icon I can store the decode_entity value instead of the NCR. The only problem will be that it means all menu link icons will be pulled from the same icon font. If I did the decode_entity just before the menu link is rendered I can have different icon fonts for different menus.
It would also be nice to have the form interface provide a pick list instead of requiring a NCR. Ease of use over flexibility would win out I think
Comment #103
thedavidmeister CreditAttribution: thedavidmeister commented#102 - true, for some characters it can be a bit of a pain. There's plenty of places other than wikipedia to get Unicode characters, the whole point is that it's a widely supported standard - Mac operating systems have had a built in "character viewer" in them that lets you get to more obscure characters for at least 20 years.
If QWERTY keyboards had full Unicode support, typing a "©" would be as easy as typing an "A" and we probably wouldn't be having this conversation.
The "title" attribute is just an example, any attribute generated by Attribute(), which is any attribute saved and loaded by the menu system, will have identical support for these characters - so data-* attributes all behave in the same way - see the last test case I wrote in #84 (that passes in Drupal core right now).
Unfortunately, when you're dealing with user input you can't make (m)any assumptions about what is "meant" by the input. As I was saying in #97, If you make allowances for "partial markup strings" (like sending an NCR as a parameter to Attribute) there's literally no way of knowing (within the AttributeString class) whether a string provided by an end user
©is supposed to be encoded or decoded or ignored before it is sent to the browser.If you're making a custom iconic font with arbitrary icons for different characters, then yes, it's your responsibility to make sure that the characters in your font are in the correct encoding before they're sent to Drupal if you want the right icon to appear in the right place - which in this case probably means running decode_entities() over a string of NCR characters first but there would be other ways to achieve this.
Comment #105
Damien Tournoud CreditAttribution: Damien Tournoud commentedThis discussion belongs in #1836160: Support icon fonts in menu links. In there, you already had the feedback that asking the user to input a numeric character reference doesn't make much sense:
Using class names instead is the best practice recognized by the industry.
So, let's leave this issue to rest.
Comment #106
dcrocks CreditAttribution: dcrocks commentedThat's fine, but still disagree. This might come back in the future in some other context but I'm not going to fight it anymore.
And I also disagree with your last comment. The class names technique is not an industry standard, nor, in all cases, the best practice.
Comment #107
thedavidmeister CreditAttribution: thedavidmeister commented#106 - You can already do what you want to do - We've written tests demonstrating that this works as well as provided multiple, detailed explanations of the "how" as well as the "why". I don't see that there could be anything to "fight" or "come back in the future" unless we overhaul the way strings are handled across the board.
In #1836160: Support icon fonts in menu links you said:
I don't see the problem with expecting non-novice users to go through a slightly more involved procedure to achieve something very specialised that generally only a relatively competent front-end developer would ever have a use-case for in the first place.
Comment #108
dcrocks CreditAttribution: dcrocks commentedThe method I propose is limited to administrative users and I intend to make it as easy as possible. I just don't think a site administrator should have to go through potentially large css files just to change one icon. For example, in a multicultural environment one icon is not suitable for all. So I think there are use cases to make these easily configurable.
By the way, doing the decode during form processing works rather well. I just have to make it easy for an administrator now.
Comment #108.0
dcrocks CreditAttribution: dcrocks commentedA better summary.