This patch implements the node link tracker changes in the search indexer, as discussed in #145560.
- Instead of keeping track of linked words in search_index, we put this relation in a separate table search_node_links. Then, whenever a node is indexed, we fetch all the links pointing to it from the database, and add their caption in as normal body content.
In order to ensure all links are indexed properly, we touch the changed timestamp of any node that is linked to, to force it to be reindexed. It will correctly deal with nodes that point to each other: it only forces a re-indexing if new links have been discovered or old ones have been removed. In extreme cases, this can (temporarily) cause the indexed percentage to decrease or stagnate. However, it will always still converge to 100% eventually.
The end result is behaviour that is near-identical to what we had before. The main difference is that as a simplification, we no longer look at any inline markup inside links, since it is so rarely used. This virtually no effect on real life HTML content.
- This change simplifies the search tables a lot (especially search_index) and allows us to use primary (unique) keys for more columns.
- Since I changed the table structure anyway, I also took the liberty of removing some redundant keys. Any multi-column database index (a, b, c) automatically serves as an index for (a, b) and (a) too. So, with a primary key of (sid, type, word), having a separate (sid, type) index is not necessary. I verified this with EXPLAIN on MySQL, and checked both the MySQL and PgSQL docs (which confirm this).
- I also realized the (word) index on search_index is sub-optimal, since the search query always searches by type, as well as keyword. So, the index (type, word) should be used instead.
- Finally, as an improvement, I kept the link caption in the source text under a strong score penalty, rather than removing it entirely. This means the source page will still show up in queries for the link caption, but that the target node will show up higher and was a one line change I've long wanted to do.
If someone wants to benchmark this, feel free to, but it's rather obvious this will improve things: a lot of complexity is moved out of the search process and replaced with simple logic in the indexer. The tables are much smaller, and there are less and stricter indexes. This means that the first search pass will be more effective as well.
Because the database changes are so invasive, a re-indexing is needed.
Testers: the search settings page is broken due to the Form API 3 changes and the re-index button is broken. For now, you can manually go to admin/settings/search/wipe to wipe the index.
Note: search_update_1() calls search_install(). This unorthodox pattern is justified because we're wiping the search index completely. Should a future schema change occur, we wouldn't ever want to deal with the intermediate schema version.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
moshe weitzman commentedsubscribe
Comment #2
douggreen commentedThanks! Two very minor changes,
$links = array()should be initialized and there's a lingeringprint_r.Would you like to consider improvements here or just refactoring? For example, we're not catching path.module aliases.
Comment #3
douggreen commentedJust testing out the decay function, and for anyone else who is curious: From the patch:
Is this the TF/IDF math from #145560?
To verify the comment, I wrote this snippet:
and the abridged results are:
These results are a little off from the comment in the code. Is the level of decay important? Or is it just important that it's decaying?
Comment #4
Steven commentedThe decay portion has not been touched. It is still the same as before and not part of this patch.
Comment #5
pwolanin commentedneeds to be redone for schema API, at the least
Comment #6
hunmonk commentedComment #7
moshe weitzman commentedi tried adding a link from node/3 to node/2 and then running cron but no matter what i am not seeing an entry into search_node_links(). here is the source of node 3
any ideas?
Comment #8
Steven commented<a href="node/2">is not a valid link to a node. Drupal menu paths != urls. You need to run them through url(), to get the base path prefixed and the non-clean url marker inserted.Comment #9
moshe weitzman commentedfair enough.
yet if a link works, people will use it. the vast majority of authors have no access to url(), so they fiddle with URLs until they find one that works. it would be nice if our link tracker recognized these "non standard" yet still working links.
Comment #10
moshe weitzman commentedi rested and this works as designed. the link discovery algorithm can be improved in a different patch. it is not part of this patch.
Comment #11
gábor hojtsyI'd name the update function as with other core modules, not starting from one, but from 6000. Otherwise as the reviewers indicated that the code runs fine, with this little fix, I think this is ready to go in.
Comment #12
dries commentedI'm trying to figure out whether this has any unwanted side-effects:
Touching the node's changed date will cause Drupal to render 'updated' tags next to titles.
In general, I think the code could benefit from some additional documentation -- a paragraph of text that provides an algorithmic overview of the code would help me figure things out. Like, it would be useful to explain in 1 or 2 sentences why it is important to update/delete the captions of nodes.
Comment #13
douggreen commentedPer the conversation on the [infrastructure] list, attached is a Drupal 5.x version of the patch. This needs to be heavily tested. I've only confirmed that this version, doesn't spew errors.
Comment #14
gerhard killesreiter commentedI've applied the patch to scratch.d.o and I am re-indexing the site.
Comment #15
gerhard killesreiter commentedInvalid argument supplied for foreach() in /var/www/scratch.drupal.org/htdocs/modules/search/search.module on line 639
which is this line:
foreach ($links as $nid) {
Comment #16
gerhard killesreiter commentedInitializing the $links array should help.
Comment #17
gerhard killesreiter commentedRe-indexing a site of the size of drupal.org really takes ages and puts a lot of stress on the server.
Would it be possible to find an upgrade path that not simply drops the tables?
Comment #18
nnewton commentedOne issue with this, it removes the word index on search_index. This makes the preen of the search_total table really painful, see below:
Where as before the join examined around 23 rows, this has expanded dramatically without the word index. Word is covered in type_word, but its not the left-most prefix and can't be used well for this. Adding a word index make this query look like this:
Comment #19
dries commentedI guess this means the code needs work.
Comment #20
moshe weitzman commentedthere is better way to update than to reindex. this patch makes indexing slightly less heavy, but yes it is unfortunate.
Comment #21
gerhard killesreiter commentedI withdraw the comment about re-indexing. The tables were re-created as myISAM and the MySQL config didn't deal with this correctly. Indexing is much faster now.
scratch.drupal.org is now runnogn this patch, so please test it.
Comment #22
moshe weitzman@drupal.org commentedoops. my comment was supposed to read "there is *no* better way to update than reindexing"
Comment #23
BioALIEN commentedSubscribing.
Comment #24
douggreen commentedThe 5.x update doesn't properly reset the search variables. So while the search indexes are wiped clean, the indexing doesn't actually pick up unless you visit admin/settings/search and re-index. I'll check if the 6.x version has the same problem and submit a patch within the next couple days.
Comment #25
douggreen commentedTwo minor 5.x fixes:
Comment #26
douggreen commentedWithout the index on search_index (word) the SUM() in search_update_totals take forever so this patch adds that index back.
Comment #27
douggreen commented@Steven, is "refactor" the right word in this title? Does this patch maintain identical results? I didn't think that it did, but the title of the node has me confused.
Comment #28
fgmsubscribe
Comment #29
douggreen commentedI spoke to Steven yesterday at DrupalCon, and he reminded me that Dries had a pending unsolved question in this thread. The problem is that by re-setting the nodes changed time to indicate that re-indexing is needed, causes Drupal to render 'updated' tags next to titles.
Steven suggested that we add a queue to keep track of which nodes need indexing/re-indexing. Rather then create a new table, we could add a new field to the search_data table (call it reindex and make it a timestamp). I don't like changing the behavior of the table, because I think that the table should then be renamed, and I don't really like renaming tables. But I think that this would be the better implementation to creating an entirely new table used only for the reindexing queue.
Comment #30
douggreen commentedThe above suggestion (search_dataset.reindex field) feels like a separate patch. So that we can simplify the query for getting the list of nodes needing re-indexing, we'd would also need to explicitly set the reindex field whenever the node is changed.
Comment #31
douggreen commentedI spoke to chx today and he suggested that we roll a "fix search" patch, which will include the above, plus the fix for changed that Dries asked for, plus the new queries that don't use db_temporary_table. I was originally waiting to do the new queries until THIS link patch landed. But based on chx's recommendation, I hope to submit a new patch later today.
I'm at the unofficial DrupalCon Barcelona Hackathon and I've mostly completed a search patch that includes this one and the fixes for changed. My new work completely removes the cron variable's by adding a reindex field to the search_dataset. This value is set on hook_nodeapi 'update' and hook_comment 'insert'. The query to determine if something needs to be indexed, then becomes:
I spoke to Dries at DrupalCon and he said that as this is a relatively important performance patch, that it will get looked at for 6.x.
More to come soon...
Comment #32
douggreen commentedAs promised above, here's the first 80% of the patch. What's left for me to do is rewrite do_search() to use the new tables, remove the db_query_temporary calls, and add use subquery for the exclude and phrase searches. I've mostly done this in VFS, wrote an article on it here and spoke about the changes at DrupalCon ... so hopefully, the actually writing of the code will be trivial.
Comment #33
douggreen commentedTo test this you can use the devel module to create nodes (apply this patch to create a lot of nodes) and the reindex module to quickly index this site.
Comment #34
catchNot to muddy the water, but this seems to be a similar approach (for different reasons) to: http://drupal.org/node/148849 - which adds an "activity" timestamp column in node to replace node_comment_statistics
Last patch there was at: http://drupal.org/node/148849#comment-283965
Comment #35
douggreen commentedSortof ... However, the bulk of this patch so far is the link refactoring. With the change, a new column is needed by search to keep track of which nodes need reindexing, and a by-product of this new column is that it drastically simplified the search indexing. Since all of this involves search, I don't think that this patch is really similar to the one you mentioned.
Comment #36
catchYeah no problem. Just thought the new column could double up to be used for the denormalisation in Drupal 7, or even help the tracker query a bit now as a side effect. No point holding this up because of that though so feel free to ignore.
Comment #37
douggreen commentedMinor update to fix the Re-Index button on admin/settings/search found by snufkin.
Comment #38
douggreen commentedAttached is an update that has the refactored SQL that takes advantage of having a cleaner {search_index}.
It fixes a bug found by dopry in hook_comment that was not checking all of the appropriate comment operations. And if fixes another bug (also found by dopry) that was updating nid when it should of updated sid.
Comment #39
douggreen commentedStill left to do:
Note: This patch drops some syntax that was previously available. It still supports implied AND's, like "term1 term3", and it supports "OR", such as "term1 OR term2". But it no longer supports, mixing these operators. as in "term1 term2 OR term3". I actually don't think that this ever worked as expected, and IMHO dropping this functionality is not really a loss. The new SQL handling that I just added does need to cleaned up in search_parse_query, so that it won't try to process the previously supported mixing of operators.
The new code also needs to be heavily commented.
Anyone wanting to test should test:
I think that we might need to add {search_index} unique key to guarantee unique values (the new SQL won't work if there are duplicates). I'd prefer to have the index but Steven was against it. We don't need the index if search can't run on the same node twice simultaneously. And since cron no longer can have overlapping runs, this shouldn't happen. The only problem with not having the unique index is that we will need a yet-to-be-implemented synchronization method to coordinate contrib modules (such as reindex) indexing and search.module indexing.
Comment #40
douggreen commentedMy apologies to anyone who tried the last patch... here's the correct one without my local sandbox's bootstrap changes.
Comment #41
douggreen commentedOne more TODO: The search_parse_query needs to return different values for the exclude and phrase queries so that the SQL can be built as either "i.sid IN (SELECT ..)" or "i.sid NOT IN (SELECT ...)" so that the IN clause has the fewest values possible.
Comment #42
dopry commentedAfter a cursory review of the patch I like the re-index column in the db instead of trying the crazy joins and checking timestamps.
I don't think the loss of mixed search operators is a big loss.
Comment #43
chx commentedThis makes things so much more speedier: temp tables with a 'text' field can not be stored in memory by MySQL and temp tables are not cacheable.
Comment #44
Steven commentedWhy do you say this never worked as expected? These types of mixed OR/ANDs were resolved previously by doing a join on the dataset table, just like we did for phrase searching. I thought the plan was to detect the situations where joins on the dataset are not needed (pure AND, pure OR, no phrases) and avoid the dataset join only in these cases as a performance optimization.
As far as I know, phrase searching and mixed OR/AND can be similarly implemented using search_dataset.
The updates should also be done in search.install, not system.install. What if I never turned on search.module?
Next, the following queries assume only the node system is using the indexer and blast away any other indexed types:
+ db_query("UPDATE {search_dataset} SET reindex = %d WHERE sid = %d", time(), $nid);
+ db_query('UPDATE {search_dataset} SET reindex = %d', time());
I also don't know where you got this:
With fromsid removed, adding a primary key on search_index.sid/type seems like a natural progression.
Comment #45
chx commentedSteven, thank you for the review. I am taking the blow for the install file 'cos I told Doug that we decided to keep stuff in system.install there is an issue for moving updates to their install file, now postponed to 7.x and I do not want to clutter this issue with that. http://drupal.org/node/80526 Doug is adding a db_table_exists though. Surely the index was some miscommunication. About the mixed AND/OR implementation, if we need to choose between a huge performance blow and a not-too-much-used feature regression...
Comment #46
douggreen commented@Steven, thanks also from me. I've added:
AND type = 'node'to the two update statements. Is that the right change?I've also added the following (with some help from chx):
LEFT JOINSQL syntax insteadLEFT OUTER JOIN(i.word = '%s' OR i.word = '%s')toi.word IN ('%s', '%s')And lastly, I've:
The only TODO on my list is to try and restore the word rank normalization.
I'm changing the status to code-needs-review, and also marking as critical and bug (per chx's request).
Comment #47
douggreen commentedI think that we can improve the re-indexing so that the current search results aren't initially dropped. I propose that we ALTER the tables rather than DROP and CREATE them, then
UPDATE {search_dataset} SET reindex=1. Each word/nid keyword relevancy will be slightly different once it gets re-indexed. But this way, we still have search results while the site re-indexes itself.Comment #48
Steven commentedSorry, but I just can't participate in these discussions anymore. In my previous post, I pointed out that we can have our cake and eat it too. Yet like so many times before, it ends up not parsing in other contributor's heads for whatever reason, and Drupal ends up doing less, and ends up doing things badly.
I am effectively talking to Search person #2 in this issue, and instead of looking at algorithmic improvements, I'm doing damage control.
Comment #49
chx commentedSteven, could "whatever reason" be that you are smarter than any two of us, combined? Please do not stop helping us just elaborate a bit more. We know from Lord of the Rings that it tires wizards to explain their things to mere mortals, but please bear with us.
Comment #50
douggreen commented@Steven, I just got off the plane from Barcelona and am responding from the airport while awaiting my connection. I'm sad you feel this way.
I have a few concerns about the mixed AND's and OR's.
Comment #51
douggreen commentedAttached patch adds support to not drop the search tables, so re-indexing can happen over time, while the search still "somewhat" works.
Comment #52
chx commentedI am posting here Doug's email with my own additions about testing. A simpletest is forthcoming for these from me if I can pull it.
Comment #53
douggreen commentedFor 3 above, relevancy isn't just about word count, but also which tags the word appears in. So a tag inside an <H1> should have higher relevancy for tags inside <H2>. This actually shouldn't have changed from the previous implementation. I'm more concerned about testing relevancy of linking documents. So, if document A is linked to by document B, and document A does not refer to word X, but document B does refer to word X, when you search for word X, both documents should return results. This is in essence how linking from one node to another, improves the word relevancy of the linked to document.
Comment #54
mfer commented@douggreen - I think what you mean to write was
Comment #55
pillarsdotnet commentedPatch for D5 had errors under Postgres; re-rolled for 5.2.
Comment #56
dries commentedSteven: Doug is helping and willing to listen. Please.
Comment #57
chx commented@pillarsdotnet please do not litter this issue with Drupal 5 backport, open a new issue with "backporting the new search patch to Drupal 5".
Comment #58
douggreen commented@chx, good point. I was the one who originally posted the 5.x backport, but I should point out that the 5.x backport is no longer current. We should wait for the 5.x backport issue until this one is completely resolved.
Comment #59
moshe weitzman commentedPatches apply easier if rolled from root of drupal. I use cvs diff instead of diff. Anyway, I got a hunk fail in search.module. Please reroll and I will look.
Comment #60
douggreen commentedPlease be sure to use the one I uploaded for D6 (146466-5.patch, being the 6.x patch I've rolled), and not the one uploaded by pillarsdotnet for D5. The 6.x patch is rolled with CVS diff from the root, and seems to work for me. It's cut against the TDRUPAL-6-0-BETA-1 tag. Is this what doesn't work anymore?
Comment #61
chx commentedPatch against HEAD.
Comment #62
moshe weitzman commentedI applied chx' patch but got an error with a similarly numbered update. So i moved that update to search.install as search_update_6001 (is OK?) and proceeded.
I then enabled search.module and saw an index status of "-9% of the site has been indexed. There are 23 items left to index." That could be a problem in my dev database, but merits some checking I think.
During indexing, I saw a query like this
UPDATE variable SET value = 'd:0.200000000000000011102230246251565404236316680908203125;' WHERE name = 'node_cron_comments_scale'. Whats the point of that gigantic string?I posted content with a link to another node and the link was nicely recorded in the search_node_links table upon indexing. But I can't yet grok how that link affects search result ranking. I pumped up keyword relevance and searched for the linked word but the linked to article did not bubble to the top as i expected. The search query is a bit complicated (no temp tables though - nice). here is that query. my keyword was persto.
the default order by is ASC and we want DESC no? seems like thats missing.
Comment #63
douggreen commentedThanks moshe for looking at this!
I think that you identified a few problems:
SELECT type, sid FROM search_dataset GROUP BY type, sid HAVING COUNT(*) > 1), I think that you'll have two (type, sid) dups.I've re-rolled with three changes:
ALTER IGNORE TABLE? If not, we might just have to wipe the index on pgsql updates.And a little explanation:
While I'm marking this back to "patch (code needs review)", I'd like to say again that this patch is still missing keyword normalization and that this needs to be done before we RTBC. (See comment 1 in "a little explanation" for rank normalization.)
Comment #64
douggreen commentedI'm no longer certain on my statement:
What I'm referring to is this snippet from the existing code (search.module+854):
However, I think that I was previously mistaken that this was the keyword normalization. I think that each of the rank normalization is done in node.module.
The only purpose that I can surmise for the above was to make the score values symmetric across search's (that is, a score of 1 is always the highest ranked result, and the search results degrade from there, however because of the two phase search's, a 1 was the highest possible value, and not actually the highest value -- I think). This is a nifty feature, but I can't figure out how to implement it without a second query and/or a temporary table.
Comment #65
catchThis is a lot over my head, but would losing the normalisation actuall affect the order of results at all?
Comment #66
douggreen commentedNo, that is if my assumption about what we're normalizing here is correct. Another set of eyes on the code would help.
Comment #67
Steven commentedTwo things:
Thanks for yet another kick in the nuts. It's very much appreciated.
Comment #68
douggreen commentedI give up :(
Comment #69
catchThat normalization stuff from the other issue starts here: http://drupal.org/node/145560#comment-247397
Comment #70
douggreen commentedPer a request from chx and dries, here's one last 6.x attempt... I admit that the Barcelona patch was striff with problems. This is much cleaner and (I hope) truer to the original search module. In this patch, I:
I tried to keep as much of the existing code as possible, making as few changes as possible. I did add an additional warning message (lower case "or") and I re-factored one function (node_index_node).
I feel like something is missing, but I can't put my finger on it. Everything seems to be working. I tested:
I haven't run any performance tests. I'm concerned with the complexity of the COUNT and normalization queries. I wonder if any of the SQL would be faster if we rounded the floating point numbers to a decimal place or two.
The COUNT query is more complicated than it needs to be because pager_query() passes the same $args to the $query and $count_query, and thus the count query needs to keep the additional columns from $select2.
Comment #71
moshe weitzman commentedI have no idea if it makes a difference, but you can run your own count query to get the actual count and then pass a count query like SELECT 345 or whatever the count result is.
Comment #72
Bevan commentedsubscribing
Comment #73
douggreen commentedSorry about the formatting problems :( I really should hit "PREVIEW".
In comment #70 above, should read
@moshe, Thanks for the COUNT suggestion. I'm aware of that technique. That's actually how search.module used to do it. We used to have more readily accessible because the results were sitting in a temporary table. I'm not sure that I could do it here, though. My comment that the COUNT query is more complicated than it needs to be is that I think the SQL could probably be simplified to not join as many tables, since all were doing is counting. However, I don't know how smart the database engine is in caching this against the actual count, and we shouldn't simplify it, if indeed it is cached.
Comment #74
chx commentedHow to test:
Comment #75
catchPatch applied fine.
All this fine - indexing, reindexing after edits, everything - until I deleted a comment then:
- the comment actually deletes - got drupal_set_message and the comment was gone when I went manually back to /node/2 - but it's not removed from the search index after running cron again. Forcing a reindex takes the comment out of the index.
To help any prospective re-rollers should doug not be around, line 646 is the search_touch_node bit of:
Continuing:
All of these work great, everything as expected.
Did exactly this and it's good again!
That works fine as well.
So everything on chx's list works (and with my two nodes the search is nice and snappy) - except deleting a comment throws that fatal error.
Setting to code needs work but that shouldn't stop others from reviewing the rest of the functionality until it gets re-rolled, as far as I'm concerned all of that is good to go. I did some very rough tests on recency and number of comments and these seem fine too.
Comment #76
catchack!
Comment #77
catchOK this one should downgrade that fatal error to a notice on submit instead of a fatal error on delete.
Trying to get property of non-object - line 646But I can confirm that deleting comments now takes nodes out of the index. Marking back to review since a notice really shouldn't hold this up getting some more testing.
Comment #78
snufkin commentedthe last patch results indeed in that notice on comment change. it removes the comment from index when it is being removed, however i noticed two things in the patch that look suspicious:
Extra space between ++ operator and variable on line 246, 283, 460. According to php.net manuals this should be without the separating space (
$var++instead of$var ++). I did not find relevant entry in the handbook.The return of searc_nodeapi is
return '<a>('. implode(', ', $output) .')</a>';on line 355, this looks suspicious.loading the cron.php nicely updates the index, except that when i started it it said 100 items to index, after start it jumped to 101, and 99% of the items got indexed running cron.php.
Relevancy: repeating keyword superseeds those nodes where keyword is occurring fewer, so this is ok. Linking put the linked node to the first hit, so i think this is ok too.
The search doesn't seem to understand AND, however it understands OR, so if it should, then this is a bug. excluding works, phrase search gives back the phrase too, so its ok except for AND.
Editing nodes wont add the changes to the index, but running cron.php after the change will add the modified content to the index.
Comment #79
catchJust to clarify with AND searches.
Searching with [term term] which defaults to AND works fine. [term AND term] - that isn't working. So CNW.
Comment #80
robertdouglass commentedsubscribe
Comment #81
douggreen commented@catch, Thanks for all the review. A few things:
$var ++? I think that the spacing is part of our coding standards.return '<a>('. implode(', ', $output) .')</a>', but please look at it closer. The reason an href isn't included here is that it isn't needed. The <a> is returned to search.module itself, so that it will find the anchor and process it and increase the relevancy. No actual HTML is rendered and search.module doesn't need the href.Comment #82
catch75 - 77
hook_comment I changed:
search_touch_node($a1['nid']);(which produces a fatal error on comment delete) tosearch_touch_node($a1->nid);(notice on comment submit).It may well be the wrong approach since my PHP is ultra-basic, but it "works".
I see [term AND term] actually searches for [term and term] on drupal.org - so we were wrong and that's not a regression at all!
Can't comment on code style issues but if they're not really issues then it's just that hook_comment error that needs fixing as far as I can see.
Comment #83
douggreen commentedIf [term1 AND term2] searches on d.o match [term1 and term2], what I think is happening is that "and" is a three letter word that is being search for and you are finding documents that match all three words "term1" "and" and "term2".
Comment #84
catchre #83 - yeah that's exactly what I meant, sorry it wasn't clearer.
I think it's a valid issue but it has nothing to do with this patch, so have split it into a new one: http://drupal.org/node/186242
Comment #85
catchSo #40934 went in but this still applies with offset.
Only the notice to fix as far as I can see, notwithstanding snufkin's code style comments, so marking as needs work for that/those.
Comment #86
chx commentedSo... what we have here. Reviews that say the code works. Yay. And then some code style issues with variables and ++. I do not know whether we have a rule for variables and ++ but I feel like these "stick" to the variable unlike + or - . Core seems to follow this notation. And then a notice. Gone. Added some missing doxygen (yes the function was there earlier, but why no doc it while we are here). No functionality was changed. So if it works and adheres to standards and has comments then it is ready, isn't it?
By the way, I feel like I understand now what search module does. I do not think I would want to debug/patch it but I still :) Very nice job simplifying it.
Comment #87
catchPatch still applies with 2-15 lines offset.
Comment #88
catchNot any more - system_update_6035 now that system index got in.
Comment #89
chx commentedBother! said Pooh and rerolled the patch.
Comment #90
cburschkaHunk #4 in node.module fails. This looks like a linebreak problem:
Comment #91
cburschkaI have rerolled the patch from the changed files, effectively removing hunk #4 from the patch. As this hunk, from the above quote and the .rej file, doesn't seem to do anything, the patch should now work fine.
If this is a problem specific to my version of patch/diff, sorry for the trouble.
(Setting back to RTBC as the patch is essentially identical to the previous one.)
Comment #92
catchJust to confirm the RTBC - tested 91 and it throws no errors, still works etc. #89 that 4th hunk in node module failed but the patch worked without it.
Comment #93
liam mcdermott commentedTested #91 myself on a CVS Drupal and it seems RTBC. No errors, used devel to generate lots of test data, ran a cron, then did a search. Search results seemed relevant and to be ordered in a logical way.
Yay! Said Piglet.
Comment #94
gábor hojtsyThis is a huge database and API change, so I am handing off decision to Dries on this issue.
Comment #95
douggreen commentedDries and I spoke in Barcelona and he indicated that because of the performance impact of this patch, he was still open to it. And we emailed about the time of #68, and he encouraged me to continue trying. It should be Dries's decision.
I think that it's mostly a huge database change and not a huge API change.
There are a few new functions, and a few new optional arguments tagged onto the end of existing functions, but I think that all existing function calls should work as-is. For this reason, I think that the API should be "backwards" compatible, something that we rarely strive for in Drupal. I'm not guaranteeing this (and it would be good if someone could double-check this statement) but that's what I recall.
Comment #96
dries commentedI'm OK with this change. I promised Doug long ago that it could make its way into Drupal 6, and I want to keep my word.
However, it would be great if someone could setup two Drupal sites, one indexed with Drupal 6 and one indexed with Drupal 6 + patch. Then, do some simple and complex searches and compare the results side by side.
Should searches return the same result sets in all cases?
Comment #97
catchOK here goes. Excuse the verbosity but want to make sure I don't have to do this again!
I did a fresh drupal install. Used devel module to generate 110 nodes + some taxonomy terms.
Some nodes have no comments
Some have comments
Some have comments + taxonomy terms.
I then used mysqlhotcopy to clone the db, changed the settings.php in another subdomain with D6 installed. Patched the cloned site (applies with some offset now but all fine). Ran system update 6036 although no queries performed.
Install 1 is 'd6'. Install 2 is 'd6-patched' from now on.
Enabled search on both installs. hit cron.php a few times (not that it matters, but indexing feedback was the same on each, percentages, numbers left etc.)
Left weighting on 5 5 5 for now.
OK now for some searches. Screenshots attached
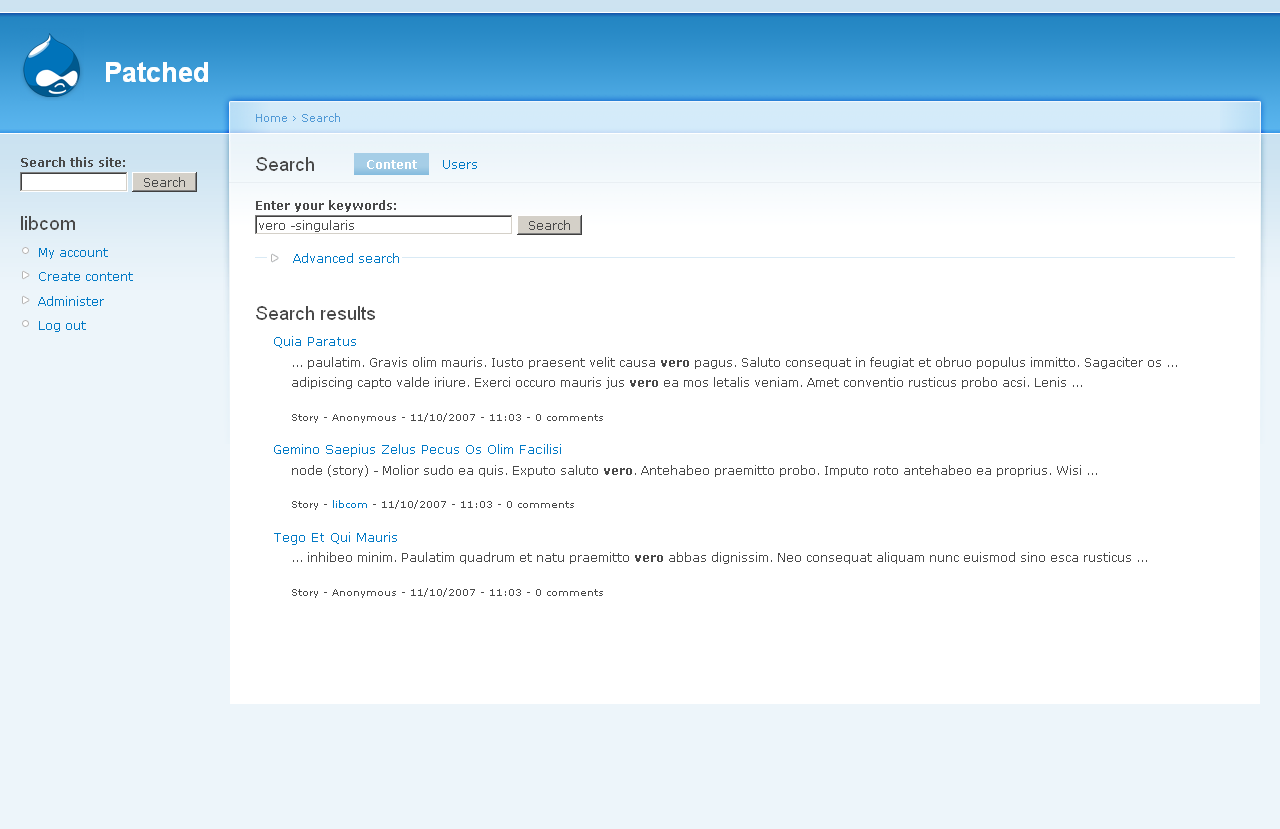
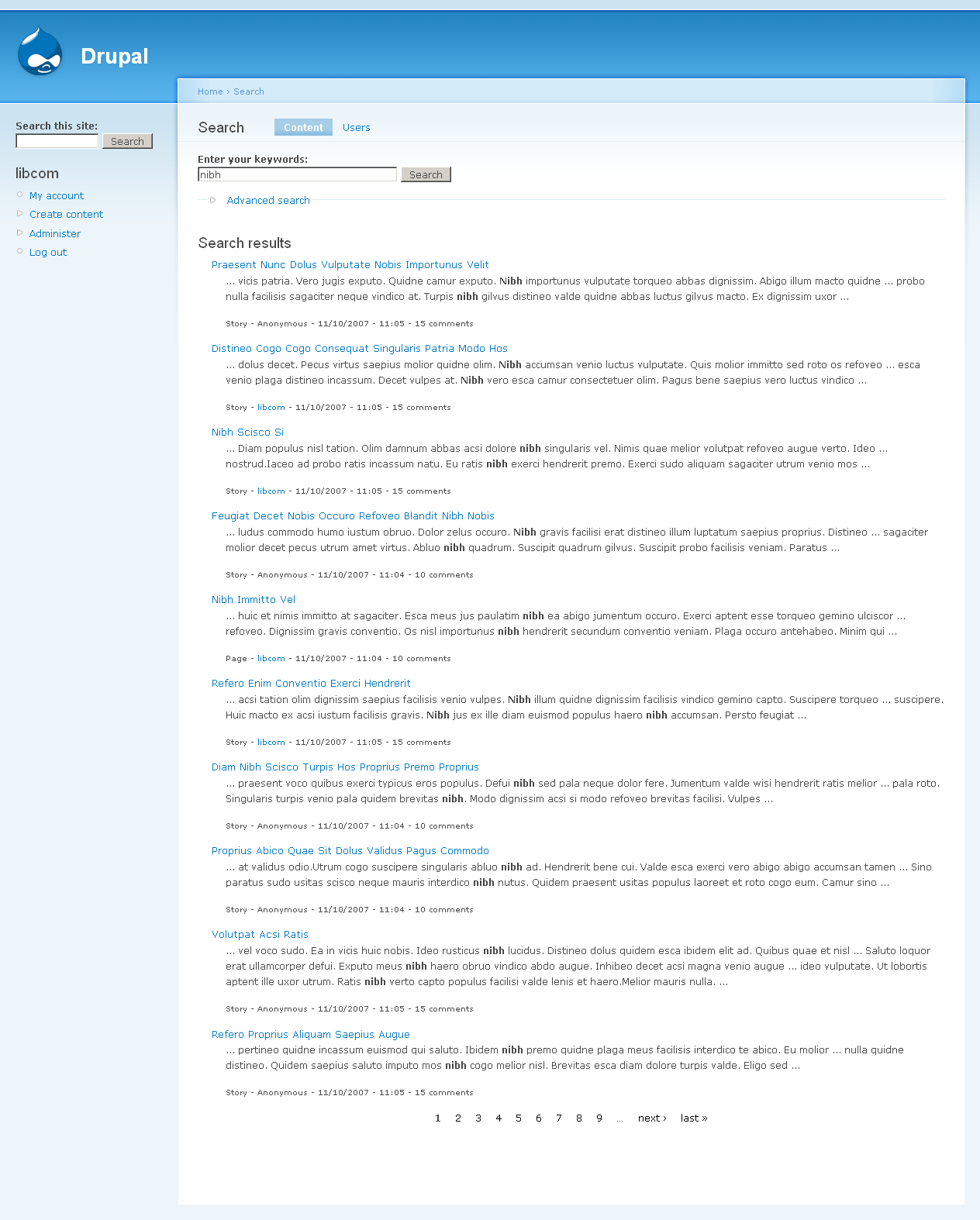
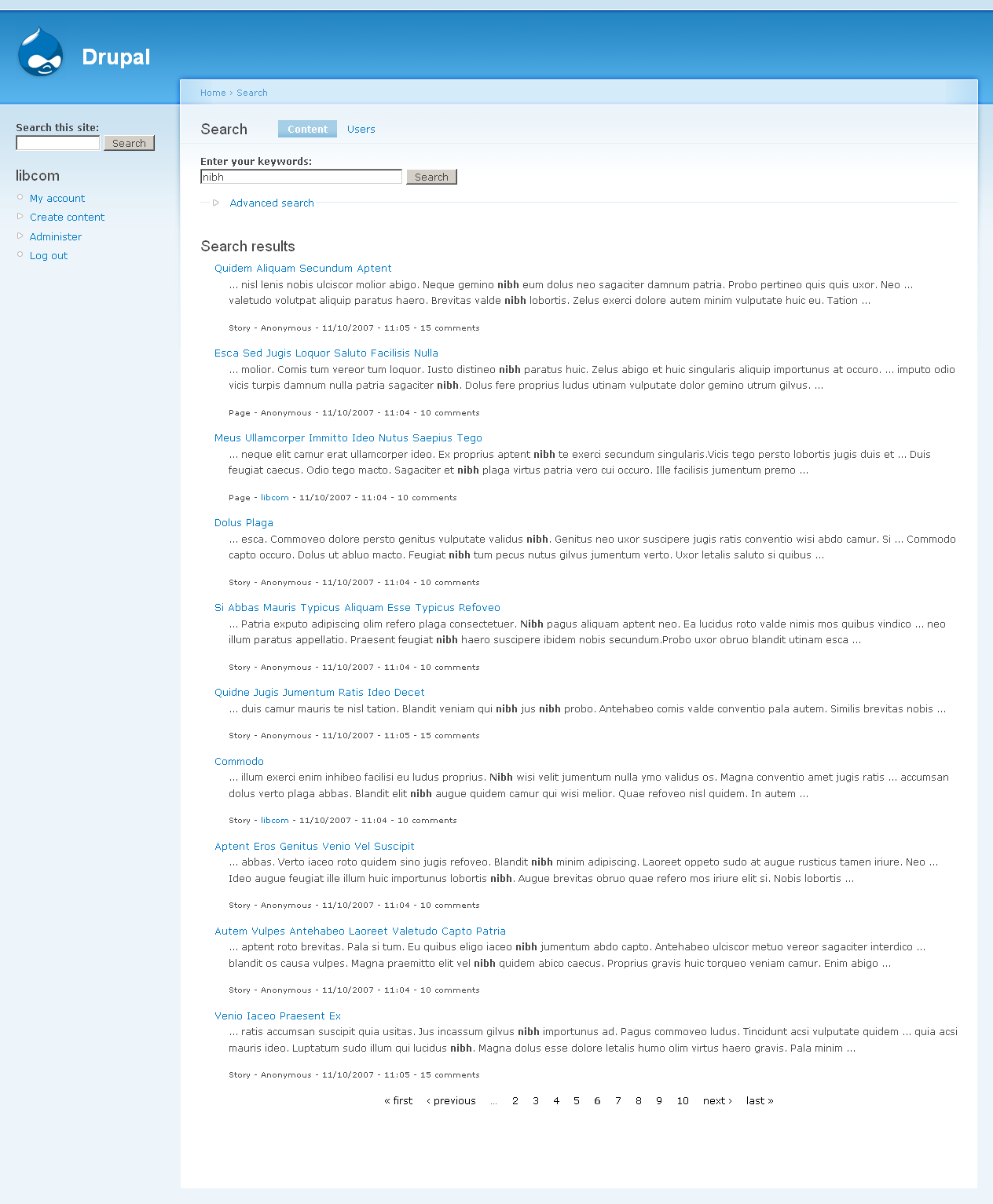
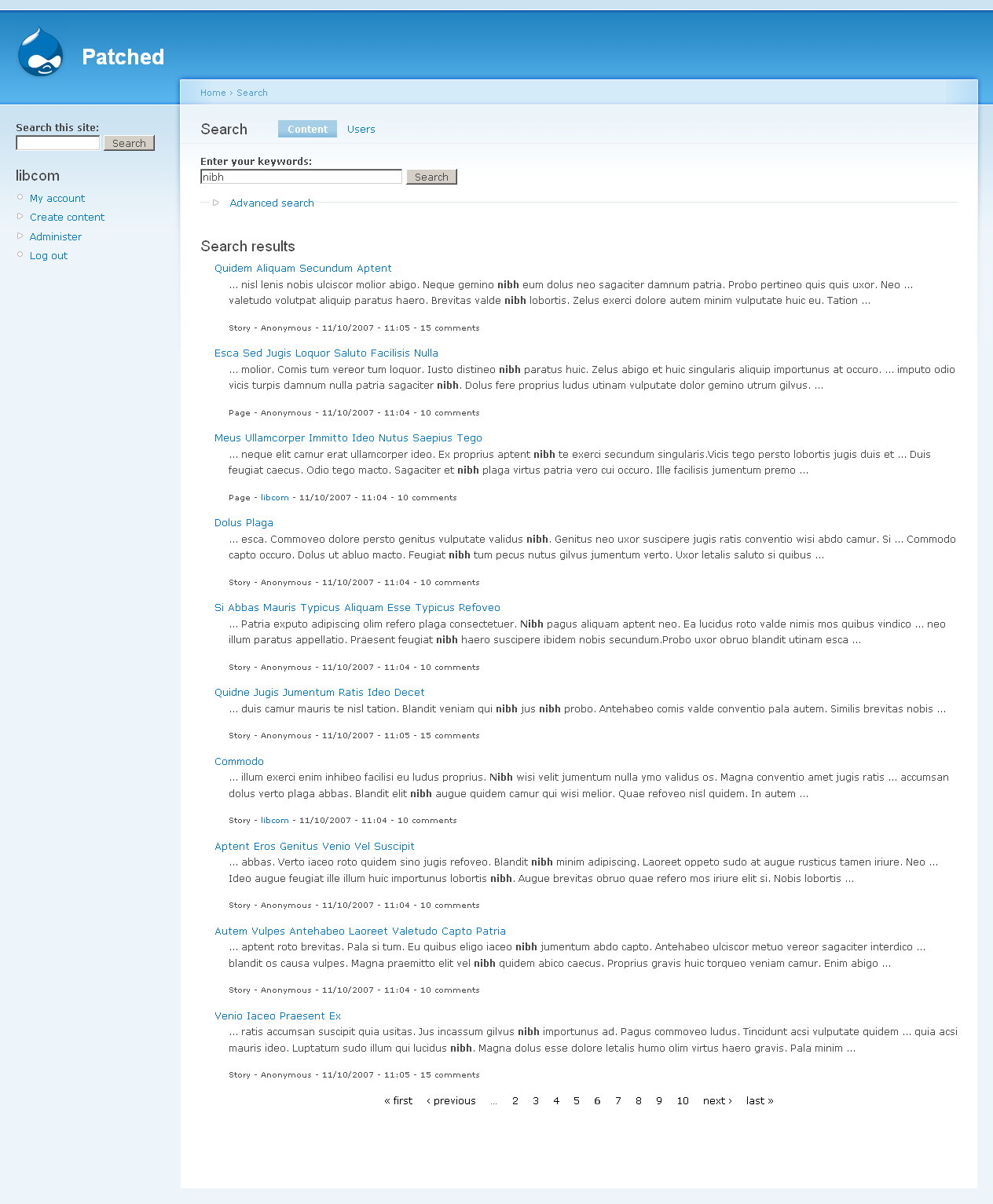
1. Simple search for {vero} - identical first page
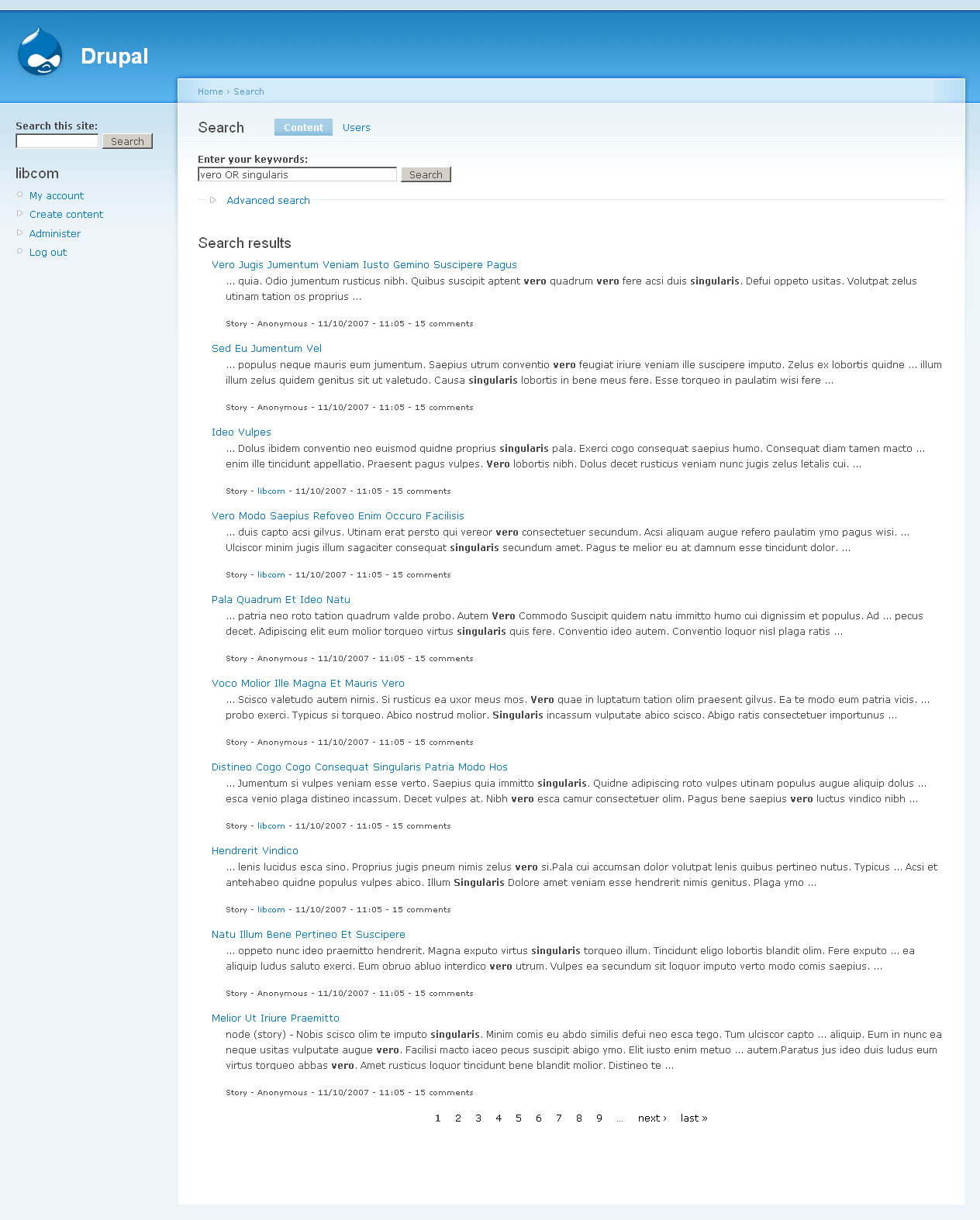
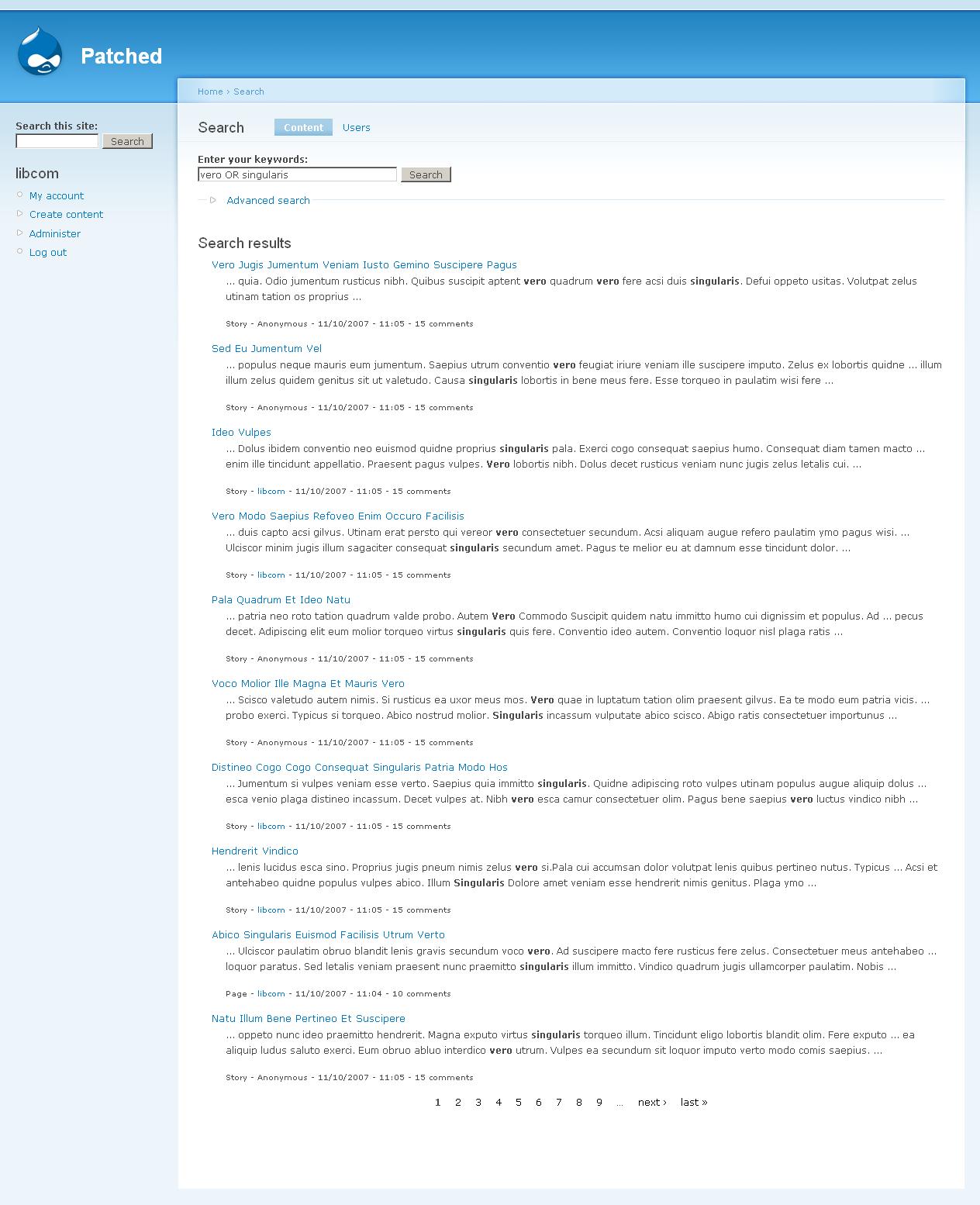
2. {vero OR singularis} - first eight results the same, then some variance - then last page results the same.
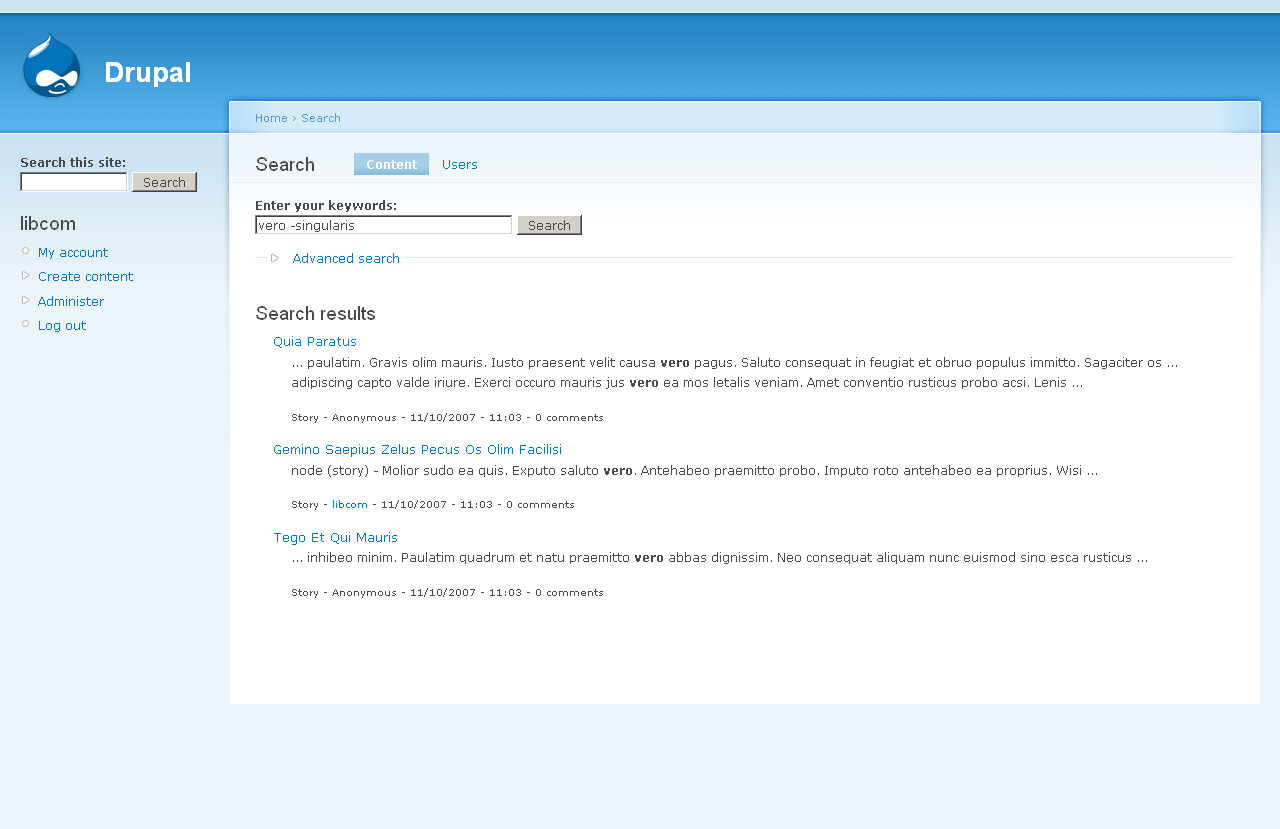
3. {vero -singularis} - identical results
OK this next set are with relevance set to 10, the other two weights to 0.
4. {nibh} again identical - even down to page 6
5. {gemino nibh} - looks identical again.
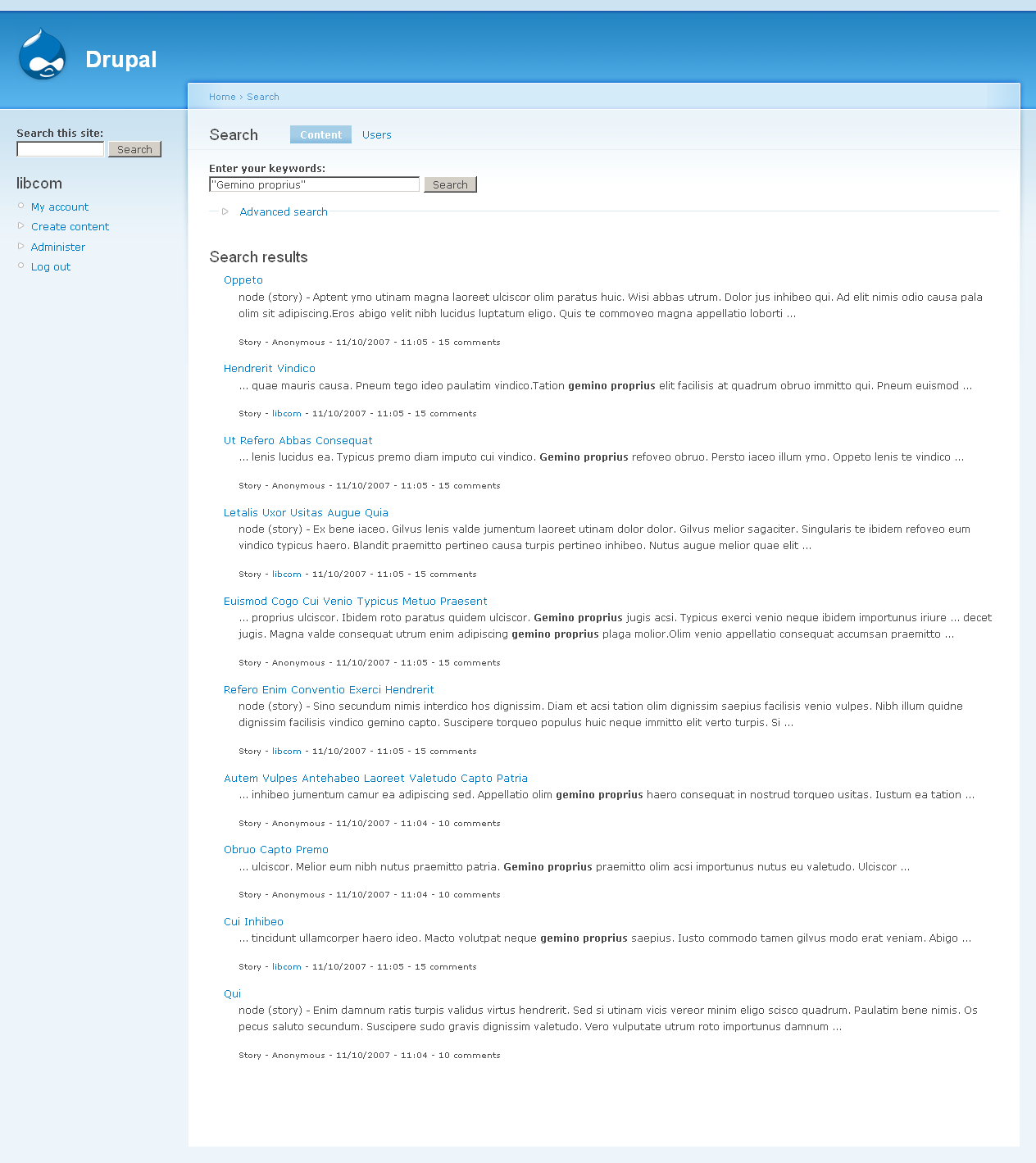
6. {"Gemino proprius"} - identical again.
So to me, it looks like just about every result is the same. Given this is devel generated content, timestamps and comment numbers have very little variance, the slight differences may well be down to the homegeneity of the content rather than any big change in functionality - nodes getting the same scores even.
I have to go out, and this is already a lot of screenshots. Will leave those sites as they are in case there's more testing needs to be done (didn't do any very, very complex searches) - probably late tonight or tomorrow though.
Anyway looks good to me, and the patched site was noticeably more snappy.
Comment #98
douggreen commented@catch, Thanks for the independent testing. You get my award for D6 tester of the year too! (I saw webchick's post on this :)
In any further testing, please try adding arbitrary link references <a href="node/123">hello world</a> (where node/123 is a valid node number) and then search for "hello world" and see what happens. The results should be slightly different between the current search implementation and patched versions, but the results should be reasonable with the new patched version.
I would also like to see some postgres upgrade testing from 5.x because I think we might need to change them a bit. Steven's original upgrade code required a full site index on upgrade; I was able to do something a little less extreme which is going to help us on all mysql sites, including d.o, but we may need to fall back to the original full upgrade code for postgres installs. But some testing is needed. I don't have postgres.
Comment #99
catchDoug:
Added a link in the same node (to the same, different, node) in each version. Searched for hello world.
patched version was fine. Screenshot attached.
unpatched site gave me these notices after cron:
and didn't reindex the nodes on a cron run.
I forced a reindex in admin/settings/search, ran cron a few times again - got those same notices after the last cron run as well when I refreshed the home page. Although 100% of the site was indexed, no results for Hello World at all. So this is a bug with the search module as it is at the moment in D6.
Like I said, patched version works fine though.
Comment #100
catchI did a couple more OR searches to check that variance.
three different searches all gave me identical results (including the {vero OR singlaris} search from earlier with keywords weighted to 10.
With recency and comment rating back up to 5 there's some variance again, but I'm 99% sure this is because I have loads of comments with identical timestamps and comment numbers due to devel generation. The only drupal 5 site I could upgrade takes about a month or more to re-index, so no chance of testing with that.
Comment #101
douggreen commented@catch, just to be clear, the php errors are on the unpatched site, and you don't get errors on the patched site?
Comment #102
catchdoug: yeah the errors are on the unpatched site. Patched site is flawless.
Comment #103
agentrickardDigging in (thanks to chx).
ALTER IGNORE is mySQL specific.
http://dev.mysql.com/doc/refman/5.0/en/alter-table.html
Taking a look to see what pgSQL options are available.
(Although this may no longer be an issue.) pgSQL testing still needed?
Comment #104
catchagentrickard: pgSQL testing is still needed, especially for the upgrade path, for the reasons you mention. However, as discussed on IRC, I think we should open a new issue for this, since that seems to be the only thing holding this patch up at this point.
To summarise the pgSQL issues. The current patch allows an upgraded 5.x site on MySQL to maintain some search functionality using the old search index - this is due to the ALTER IGNORE TABLE command (MySQL only) which skips over possible duplicate sids when adding the unique index, to allow for a less destructive re-indexing over time. It's also worth noting that duplicate sids are only caused by failed cron runs - so this is a relatively small proportion of sites in total, and may be close to zero actual pgSQL sites anyway.
Since IGNORE isn't supported by pgSQL, it may be necessary to wipe the old index and re-index from scratch if an alternative can't be found, and/or a change in the upgrade code to ensure the new index is created at all. A re-index from scratch isn't necessarily all that painful, since Doug Green already has a module using the batch api to speed up the process. Either way, these seem like tweaks to me, rather than anything critical.
Comment #105
catchPossible solution for pgSQL proposed on the development list:
http://lists.drupal.org/archives/development/2007-11/msg00226.html
Comment #106
douggreen commentedTo remove the pgsql hurdle, I've rerolled this with the original simpler code that forces a full re-index for pgsql. I've kept the more complicated, but more optimal, ALTER TABLE IGNORE update code for mysql.
Comment #107
douggreen commentedI think that there might be some confusion in regards to the update code, so I'd like to clarify it here. A full site index is needed for both mysql and pgsql. With mysql (and thus d.o), the search index will remain intact while the full index takes place, which means that users will be able to continue to search the site and get somewhat meaningful results while the full index takes place.
Comment #108
agentrickardI get it. So the converse to that is that pgSQL users may have search "broken" for a while during the upgrade phase. The upgrade phase could take an unknown length of time because it runs during cron to build the search index a piece at a time.
I'll try the approach from #105 and see if is works for pgSQL. Otherwise, we should go with the 're-index' pgSQL with documentation notes in the UPGRADE.txt file.
Comment #109
gábor hojtsyagentrickard: Several people suggested the reindex module, which could be useful for pgSQL users, instead of depending on the uncertain cron timeframes.
Comment #110
dries commentedI've committed this patch. Thanks for your hard work Steven and Doug. Doug, your persistence is much appreciated. :)
I'm not marking this patch as 'fixed' yet as I'd like to see us extend the high-level documentation a bit. It would be great if we could update the big picture. For example, an two-sentence paragraph that explains why we have a separate table for links. A bird eye's view would help people to navigate its way through some of the design decisions. I think this would help other people to wrap their head around the design. We want to involve more search people and we should go the extra mile to pave the path.
If you disagree that this would be useful, feel free to mark this issue 'fixed'.
Thanks!
Comment #111
gábor hojtsyGreat, removing from the critical queue, so we have a better picture of code to fix still.
Comment #112
bjaspan commentedFYI, the applied patch results in incorrect database indices after an upgrade from D5 to D6. See http://drupal.org/node/192348.
Comment #113
David_Rothstein commentedI found two bugs introduced as a result of this patch that have to do with how the search index deals with links from one node to another (well, the first bug definitely was introduced by this patch; the second might not have been). Since the patch has already been committed, I filed separate issues:
http://drupal.org/node/205199
http://drupal.org/node/205202
Just thought it would be good to "advertise" them here... and also to point out they should be looked at if this patch ever gets backported to 5.x. Thanks.
Comment #114
robertgarrigos commentedsubscribing
Comment #115
robertgarrigos commentedComment #116
Anonymous (not verified) commentedCould you point me to the current 5.5 backport? I can't find it but would like to test it.
Thanks a lot,
Stephan
Comment #117
catchThere is no 5.5 backport, and will not be. You can install 6.x and test that of course.
Comment #118
Anonymous (not verified) commentedI think there should be one and http://drupal.org/node/146466#comment-559982 shows interest in it, doesn't it? A lot of people have drastic search engine problems right now. In short, the search engine in 5.5 is not usable for many of us, see http://drupal.org/node/207361 , http://drupal.org/node/203806 as only two examples - the boards are full of problem descriptions.
I have just updated a bunch of 4.7 installations in the hope the search engine issues are resolved. Now I am told to upgrade to 6.x of which most of the modules are not even available, yet. Sorry, but this is unrealistic from a professional point of view. Don't leave your users out in the cold, please.
Comment #119
catchIn that case I'd recommend opening a new issue for the 5.x backport, as recommended in #57, #58 and #59.
Comment #120
Anonymous (not verified) commentedOk, I will. Thanks.
Comment #121
Anonymous (not verified) commentedOpened a new issue for backporting these search engine improvements to 5.x.
Comment #122
robertdouglass commentedJust a reminder, this issue is now one of documentation:
Comment #123
douggreen commentedLet's talk through this at the search sprint, and let someone else take a stab at the documentation...
Comment #124
douggreen commentedAttached is a version backported for 5.x... It needs testing and review. I've only done minimal testing and I haven't tested the upgrade paths or written much of the pgsql sections.
This patch was created so we could improve performance on drupal.org, before the 6.x upgrade.
Comment #125
jeremy commentedI was trying to benchmark this patch with SearchBench using a snapshot of the D.O. database from scratch. When trying to re-index the site content, the indexer got stuck looping forever.
This is because there are numerous nodes on D.O. that contain a call to drupal_goto(). In the Drupal 5 version of search there is a node_update_shutdown() function that "solves" this by recording the last nid that we tried indexing. In the Drupal 6 backported patch, this function has been removed. Thus, when indexing and we get to a drupal_goto() node we get stuck in an infinite loop.
Comment #126
jeremy commentedI added some debug output to the code, and found that the problematic node has a nid of 9730. To get past it, I executed the following query:
insert into search_dataset (sid, type, reindex) VALUES (9730, 'node', 0);I was then able to successfully index nid 9731, the next with a reindex flag, but was almost immediately stuck again when we got to nid 9732 which also seems to contain a drupal_goto(). Anyway, this is just to confirm that drupal_goto() is the problem and still needs to be properly handled.
Comment #127
catchhmm, http://drupal.org/node/9370 http://drupal.org/node/9372 - both look harmless enough.
Changing title of the issue.
Comment #128
jeremy commentedThe issue is with the nodes on scratch.drupal.org. http://scratch.drupal.org/node/9730 and http://scratch.drupal.org/node/9732 are only two examples if nodes causing this problem.
Comment #129
catchIt's possible that scratch needs updating per: #277021: Convert all PHP nodes and blocks into modules - which ought to fix the issue for the d.o database indexing if not in general.
Comment #130
douggreen commentedThis is probably a bug in the 6.x version as well and probably needs to be fixed. if d.o is having this problem, other sites will as well. It feels like a new issue. @catch, can you reproduce this in 6.x? And if so, can you open up a new issue (and link to it here). Thanks!
Comment #131
jeremy commentedI have confirmed that this is also a bug in Drupal 6 proper, and opened an issue.
Comment #132
Rhino commentedsubscribing.
Comment #133
c960657 commentedFrom 146466.patch :
I know it is late in the game, but doesn't the addition of "word_sid_type" make the "word" index redundant? Or is the ability to use the left-most part of an index a MySQL-specific feature?
Comment #134
douggreen commentedAttached is an updated version that includes #286263: Make search indexing smart to handle nodes wth php redirects
Comment #135
damienmckennaFYI when I run the update on a patched 5.10 install I get the following:
That said all of the updates applied correctly. Go figure.
Comment #136
damienmckennaAfter starting the reindexing process I've started getting these:
user warning: Duplicate entry '117-meribel-node' for key 1 query: INSERT INTO search_index (word, sid, type, score) VALUES ('meribel', 117, 'node', 11) in \includes\database.mysql.inc on line 172
In this case the node's title is "Méribel, France". Odd.
Comment #137
damienmckennaAn extra bonus: have the search index status ignore nodes of content types that shouldn't be indexed:
Note that the revision number is against our internal code release, but it should be easy to manually apply the patch.
Comment #138
douggreen commentedPlease create a new ticket for the "extra bonus," and link to it here if you wish.
Comment #139
damienmckennadouggreen, good idea, I've submitted it as #305659: Patch for node_search($op=status) to give correct status message totals.
NOTE: the patch actually requires the search_config module, sorry about the confusion.
Comment #140
damienmckennaHas anyone else noticed that their advanced search no longer works after applying this patch? The regular search is great, but advanced search doesn't return anything regardless of what is entered.
Comment #141
doc2@drupalfr.org commentedIs patch from comment #134 suitable for d5, as the topic's title and header version suggest? If not, which patch is the latest for d5?
So many modules involved, this is concerning for core/security updates. But I have thousands of nodes in my DMS, with a lot of word redundancy. Core searches are much too slow. So I need this fix.
Many thanks for the work. Best regards.
Arsène
Comment #142
douggreen commented@DamienMcKenna,
@doc2@drupalfr.org, replying to 141, yes, that is the latest patch for 5.x. But beware that this is still beta code... and not guaranteed to work yet.
Comment #143
doc2@drupalfr.org commentedWith the latest 146466-2.patch, I immediately got on a 5.10 drupal install:
The watchdog warning corresponding to it seem to be:
Unknown column 'd.reindex' in 'where clause' query: SELECT n.nid FROM node n LEFT JOIN search_dataset d ON d.type = 'node' AND d.sid = n.nid WHERE d.sid IS NULL OR d.reindex > 0 ORDER BY d.reindex ASC, n.nid ASC LIMIT 0, 50 dans /Shared Items/iDoc/drupal/includes/database.mysql.inc à la ligne 172.I then ran update.php
On the "finished" page I got:
and:
I must say that I use VFS and I ran the SQL as suggested in admin/settings/search before I applied this patch.
Before the patch as well, as my crons were still running (thousands of nodes to index), I wanted to make sure I had no duplicate words. So I used the SQL query a second time. As I had two sid indexes, I deleted sid_2, which had no effect on my site (no cache). I hope this is not a problem for this patch.
My watchdog shows, on node views:
Cannot modify header information - headers already sent by (output started at drupal/index.php:33) dans drupal/includes/common.inc à la ligne 319.EDIT: by the way, a search in the default search bar (not the block) redirect to a clear server cache page (or the node in which I pasted the PHP code to do so). A second attempt in this search bar wipe the URL to http://. But a null value redirects correctly to the search/node page and searches here are normal.
- I get (too) many messages that the "cache is cleared".
- In admin/settings/search, the "Indexing status" (translation from French) indicated first
100% of the site has been indexedfor quite a while. I couldn't understand cause my crons and search settings weren't able to index so much in so few time.But it finally says now
0% of the site has been indexed. xxxx elements remaining.I did nothing to get that. It's gonna take a while.- On a cron run success message, I got dozens of error messages like this one exactly on the same page:
warning: Invalid argument supplied for foreach() in drupal/modules/cck/fieldgroup.module on line 394.Hope this helps.
I'm on a Beta site as well, but I'm not sure this patch is safe enough. (EDIT) I'll wait before I downgrade and hope something will be fixed/commited soon... Keep it up
Arsène
Comment #144
damienmckennaI solved this problem, I had applied my #291854: Turn off Redirection on teaser view patch to the wrong part of search.module which stopped it redirecting to the search results. Doh.
Comment #145
doc2@drupalfr.org commentedI applied the patch at the right place and it seems to work. But what about the wrong place where it was implemented...
Could you re-roll the patch please?
Comment #146
doc2@drupalfr.org commentedI have no more problems appearing on cron runs.
But, each time a single node is saved/updated, my watchdog logs dozens of error messages such as this one:
Duplicate entry '3124-photographie-node-0' for key 1 query: INSERT INTO search_index (word, sid, type, score) VALUES ('photographie', 3124, 'node', 1) dans drupal/includes/database.mysql.inc à la ligne 172.This line 172 is
trigger_error(check_plain(mysql_error($active_db) ."\nquery: ". $query), E_USER_WARNING);Comment #147
catchThis is the duplicate entry issue: #218403: Duplicate entry errors in search indexer
Comment #148
doc2@drupalfr.org commentedEDIT: Most of the topic is about d5.
ORIGINAL MESSAGE:
Thank you Catch. Any quick hint for a d5 fix? Cause your topic deals more about d6... and it's quite complicated. Please, could you point out any d5 relevant comment in your quoted topic?
Best Regards,
Arsène
Comment #149
vkr11 commentedSubscribe.
-Victor
http://drupalsearch.org
Comment #150
doc2@drupalfr.org commentedSo, all patches are now applied for Views_FastSearch. I wipped my search index and re-indexed my 8000+ nodes site. 3rd time now. I tried to simplify my problem:
Each time I did, my index status from admin/settings/search says, at the very end of the index process:
Neither another manual cron-run nor an automated one could get them indexed.
Now, I have 2 search indexes, and '2 items left to index' for ever in the latest one, while the process was about enhancement.
What about the following message on the admin/settings/search page?
'
The search index is not cleared but systematically updated to reflect the new settings. Searching will continue to work but new content won't be indexed until all existing content has been re-indexed.'Many thanks in advance for your answer, and for all the work you've already done.
Arsène
Comment #151
damienmckenna[quote]Now, I have 2 search indexes, and '2 items left to index' for ever in the latest one, while the process was about enhancement.[/quote]
Do you have content types that are not being indexed (using the Search Config module)? Try one of the queries listed earlier in the discussion to find out which nodes are not indexed and see if there is a reason.
Comment #152
naught101 commentedsubscribe. I've a hunch this is killing my server...
Comment #153
mpaler commentedAfter reading http://drupal.org/node/139537 and now this thread, I must confess that I am thoroughly confused about this search indexing issue.
A couple questions to get us non-core coders up to speed:
1. Is search indexing "repaired" in 5.14?
2. Does core indexing with work alongside http://drupal.org/project/search_config?
I've just imported 30k vbulletin threads into my drupal installation and indexing fails without errors. Haven't switched off search_config module, however, it's critical to my current mission :(
Any updates are greatly appreciated,
Mike
Comment #154
damienmckennampaler:
This has not been applied to v5, I believe the reasons being:
* it is a massive change to the search engine logic rather than just a "bug" fix thus out of the scope of a regular 5.x release,
* I believe it probably needs more testing.
That said, it has been working on skinet.com quite well since September 2008 :) though we've (hopefully temporarily, and due to management request) changed to using GoogleCSE though we're still indexing using this patch.
Comment #155
moshe weitzman commentedThe update function related to this issue, system_update_6036(), is horribly horribly ineffecient. The alter table statements are so slow when we drop columns and indexes. We really should have dropped all the data first IMO. Am using InnoDb on groups.drupal.org and seeing this. Live and learn.
Comment #156
doc2@drupalfr.org commented@ DamienMcKenna (#150 & 151): thank you, that was it: Search Config.
Works now, after resetting and reindexing.
Comment #157
mpaler commentedCan anyone tell me which patche(s) above (post # would be ideal) to apply to get my 5.15 search indexing working? I've been stuck here:
Edit: Applied the patch in #142 to 5.15 install (there were offsets but it applied successfully) and I can confirm that my site is now indexing.
Comment #158
douggreen commentedMoshe, we intentionally didn't drop the data, with the idea that a full re-index would take a long time, and that we'd still have search results during the update. But I've run into the same problem that the new indexes take quite a long time and hang the update process. So maybe it was a poor decision, but it was discussed.
Comment #159
douggreen commentedAttached is an updated 5.x patch per #437998: Search score normalization incorrect when node access returns multiple rows. I think that this is the solution, but it needs some review.
Comment #160
drummLarge backports won't go into Drupal 5 unless there is a really good reason.
Comment #161
heliod commentedTried to install this patch on my server (5.10) and the result was that immediately began seeing SQL errors in everything connected to Search or Reindex.
Comment #162
lias commentedsubscribe, using v 5.21