
Closed (fixed)
Project:
Feeds XML Parser
Component:
Code
Priority:
Normal
Category:
Feature request
Assigned:
Unassigned
Issue tags:
Reporter:
Created:
12 Nov 2009 at 18:06 UTC
Updated:
2 Apr 2013 at 19:39 UTC
Jump to comment: Most recent file

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
chrism2671 commentedCould use this!
http://www.php.net/manual/en/simplexml.examples-basic.php
Comment #2
velosol commentedchrism2671 : I agree this would be a great feature, however... After writing my own parser for the custom XML I needed to consume, I do not relish the idea of trying to make it extensible in such a way that non-developer types could use. I've posted a generalized version of my code below in case anyone else wants to use it as a starting point. It is far from clean and includes lots of old debugging code.
Some starting ideas:
Make the xpath queries variables that can be set in a configuration form,
Make the various parts (item, title, description) equal to variables of the form parent_object->child,
Make the whole set of code a bit more OOP so attribute elements and other elements can be added without bound.
This code is mostly lifted from other places around the d.o issue queue (or Feeds) and the php SimpleXML examples - original credit goes to them which are more than I can remember at this point.
Comment #3
chrism2671 commentedIt's unfortunate that this is quite fiddly! Will have a go and report back!
Comment #4
alex_b commentedWith mapping on import implemented, we could rely (as in FeedAPI Mapper) on analyzing the feed before offering mapping sources #651478: Mapping on import.
Comment #5
alex_b commentedFor a demo project I have written a rule based parser called RParser.
In its documentation you can see how RParser allows for a definition of parsing rules with XPaths:
What's missing are namespace declarations and some simple fallbacks (what if the title does not yield a result?). This approach could get us very far. People who are looking for parsing XML documents with uncommon namespaces could easily add these with a simple hook implementation.
Further, if we were to write a 'magic parser' that allows a site builder to enter xpaths through a site UI, this is the infrastructure we'd want to have running underneath it.
Comment #6
mottolini commentedLinks to RParser and its documentation are not working.
I'm really interested in RParser and willing to add a useful UI to it.
Comment #7
alex_b commented#6: fixed.
Comment #8
whatdoesitwant commentedI forget to say that rparser looks clean and smart, as does the new feeds: amazing work. As a sitebuilder/themer I welcome the idea of opening this functionality up to the drupal ui.
For my 2 cts I think it better to work towards a general add-on that does open up the (feed)source specific (xml)data - as an extra array entry within the parsed php-array, along with the default fields - to the drupal ui.
This would mean that a setup as in your primary feeds tutorial vid would have to serve as a base on which more specific mapping can take place when the (feed)source's (xml)data is available.
If extensible parser does just that, i am sorry, but as a non-developer i never got it (which is my ish with that entire module). I'd much rather use something like exhaustive parser.
This approach is not as bad as it sounds because a three step configuration for specific (feed)sources is already necessary on the processing side (You have to create target fields based on the (feed)source's (xml)data, after creating a preliminary feed ct instance.)
Comment #9
SeanBannister commentedMight be worth looking at phpQuery and QueryPath which also has a module. I'm currently evaluating both for easy screen scrapping. They allow you to use jQuery style syntax to select XHTML elements.
Comment #10
netentropy commentedhow does one actually use Rparser?
Comment #11
JayCally commentedI need to import a custom XML file and have been trying to come up with a way to do it using Feeds. I downloaded Rparser but it is dependent on the feedsapi not feeds. Can this be used with feeds?
Comment #12
Thoor commentedSorry - this is maybe not the right Place to ask, but can anybody tell me ... is it possible to handle a XML File like shown under:
http://wiki.zanox.com/en/Product_Data_Download#Example_XML_file and create nodes from it? And if yes - do I have o use the OPML IMPORT, or FEED for it?
Beg your pardon - I read the documentation, watched the three videos and asked already in the regular forum without any answers ... THX
Comment #13
JayCally commentedYou would need a custom XML parser.
Comment #14
Thoor commented@ JayCally
THX a lot for your answer ... so I dont have to "try and error" anymore :) ... so I will use the CSV Import ... this is working so far.
Comment #15
JayCally commentedI'm creating a custom parser to pull in my custom XML file and used common_syndication_parser as a starting point. I have it set up and can select it in the parser section of feed importers. I can map the source to the target but am getting an error when importing. The error is: Invalid argument supplied for foreach() in FeedsNodeProcessor.inc line 22. I'm not sure what's wrong. I've attached a zip file with the custom parser and example XML file. Could someone take a look and see what I may have forgotten or screwed up?
Comment #16
netentropy commentedhow do you use the custom parser once you write it?
Comment #17
JayCally commentedAdd the below to feeds.plugin.inc. so you can select it as the parser to use in feed importers. You can also create a plugin for it to set up the mapping options.
$info['YourCustomParser'] = array(
'name' => 'Custom parser',
'description' => 'Parse custom XML files.',
'handler' => array(
'parent' => 'FeedsParser',
'class' => 'FeedsCustomParser',
'file' => 'FeedsCustomParser.inc',
'path' => $path,
),
);
I have it all working except the parser. I used common_syndication_parser as a base but I think I left some things out. So I'm redoing it and hopefully I can get it working soon.
Comment #18
JayCally commentedOK. Have trouble getting the custom parser to work. I used common_syndication_parser as a starting point, removed anything that I didn't need. I tested it on a normal feed and it works. But when I go into to add the custom fields I get an error message "feeds/plugins/FeedsNodeProcessor.inc on line 22" and I can't figure it out. :( Just as an example my custom feed doesn't have title for an item but "ADID". When I change title to this common_syndication_parser I get the error message.
Can anyone help me out with this?
Comment #19
JayCally commentedWas able to get the custom parser to work. I can now import my custom feeds. Wish this was a standard feature of feeds. News companies and other sites that need to import data from their in-house databases get their content exported as a custom XML file. I work for a small newspaper publisher and all of our vendors have changed their product to export content as XML. This would be a very helpful feature to have standard with Feeds.
Comment #20
netentropy commentedehaustive parser for FeedAPI works nicely for FeedAPI, i will talk to the maintainer about porting it
Comment #21
velosol commentedJayCally, I'm sorry I didn't get back to you sooner. I'm glad you were able to get the custom parser working. Since I posted the first code blocks, I've had a chance to refine what I used for my custom parser; unfortunately my work has moved away from Feeds for the time being and I haven't been trawling the issue queue recently.
I'm posting the files I used (which is a custom module that uses Feeds hooks so that I don't have to modify Feeds' core files) in such a way that if you, or another developer needs a custom parser, you'll have a fairly good starting point/skeleton.
I would like to note that this is not in line with #4/#5 and should really only be a stopgap until rparser and mapping on import come to fruition. Also, it doesn't support namespaces as written, but in customizing for your files it should be easy to add. It could also use some additional OOP updates if you're planning on consuming really complex files.
The module says that it requires Feeds - for full functionality as written it also needs location_cck - this support is easily taken out by commenting the block relating to it (as mentioned in the files); especially useful if you don't have location data.
I hope this helps you, or someone else until a better solution is found.
Comment #22
JayCally commentedThanks velosol. I was able to get my custom parser working and added a patch to Feeds to allow mapping to image fields. It took me a while but was a good learning experience. I am now looking for away to map location cck fields, email field and website field. I can probably just use text fields for email/web and make them linkable in content template but location will be the big one to get done.
Comment #23
velosol commentedJayCally - I have lat/lon location CCK support in the module I posted in #21. It's definitely not robust, but could serve as a starting point for you.
Comment #24
JayCally commentedThanks velosol! I pulled the section of code I need from your module and used that as a base. I had to make some changes and additions but I have it working now.
Comment #25
rjbrown99 commentedvelosol - for what it's worth, your module was fantastically helpful in allowing me to create a custom XML parser. Great stuff and well commented. Thanks!
Comment #26
gregag commentedI get:
* user notice: customxml_parser_parse received bad XML, beginning: in C:\SERVER\htdocs\sites\testnadrupal.com\modules\cleandata\customxml_parser.inc on line 40.
* warning: Invalid argument supplied for foreach() in C:\SERVER\htdocs\sites\testnadrupal.com\modules\feeds\plugins\FeedsNodeProcessor.inc on line 22.
from code I inserted:
// Got a malformed XML.
if ($xml === FALSE || is_null($xml)) {
trigger_error("customxml_parser_parse received bad XML, beginning:" . substr($string, 0, 20));
return FALSE;
}
$parsed_source = array();
//@todo: Add formatted time string to title.
$parsed_source['title'] = '//html/body/form/table[2]/tbody/tr/td[1]/table'; //(string)current($xml->xpath('//Some/appropriate/path')); ////
$parsed_source['description'] = 'Webpart'; ////
$parsed_source['items'] = array();
// @todo: (alex_b) Make xpath case insensitive.
$customItems = $xml->xpath('//http://www.kjekupim.si/si/vroca_ponudba.wlgt'); ////
foreach ($customItems as $cItem) { ////
$item = array();
//Set the guid of the
$item['guid'] = (string)$cItem->Level1->Level2; ////
/**
* Skip those items without a guid - if you want this functionality
if( $item['guid'] == NULL) {
//We don't want it if it doesn't have an id.
continue;
}
*/
What did I do wrong?
help me please...
Comment #27
gregag commentedI would like to feed from table. Attached picture for easier understanding what I want...
Comment #28
gregag commentedSorry for previous post, here is example
Comment #29
gregag commentedsome help how to write appropriate path in line $todo would be seriously big THANKS from me
Comment #30
geerlingguy commentedSubscribe... would love an in-the-gui option, as I have a few news sites where we change the mappings from time to time, and maintaining a plugin/module is always a burden.
Should this be marked as a duplicate? Or vice-versa?
#651478: Mapping on import
Here's the feed I'm trying to import (a few custom xml siblings have been removed, for brevity.
I can get everything to move to the site except for the "summary" - I want to move that into a CCK 'Byline' field...
Comment #31
paganwinter commentedSubscribing...
Comment #32
jay-dee-ess commentedsubscribing
Comment #33
jay-dee-ess commentedI'm trying to use velosol's cleandata module and am getting the following error when I try to use the Custom XML Parser:
I haven't made any changes to the code and am a noob...any help would be much appreciated.
Comment #34
sutch commentedsubscribing
Comment #35
drewish commentedsubscribing
Comment #36
TimG1 commentedsubscribing.
And if there is any developers for hire out there who can write a custom parser for my feed please get in touch via my contact form.
Thanks!
-Tim
Comment #37
reglogge commentedsubscribing
Comment #38
pvhee commentedIt would be great to have out-of-the box support for XML import in Feeds. What are the blockers to get this done?
Comment #39
pvhee commentedBuilding on the efforts on XML Parser, I created a Feeds plugin that can deal with (simple) XML, much like is being dealt with CSV at the moment.
You can find the module at http://github.com/pvhee/feeds_xmlparser. Note that this is only tested in my sandbox.
I'd be glad to receive any feedback on this, and hope we can tackle the problem of XML import using Feeds.
Comment #40
funkmasterjones commentedInstall the feeds_xmlparser module
The patch is mostly to give a parsing example in the mapping section, I can't recall if feeds_xmlparser needs it to run, but I would recommend it anyways
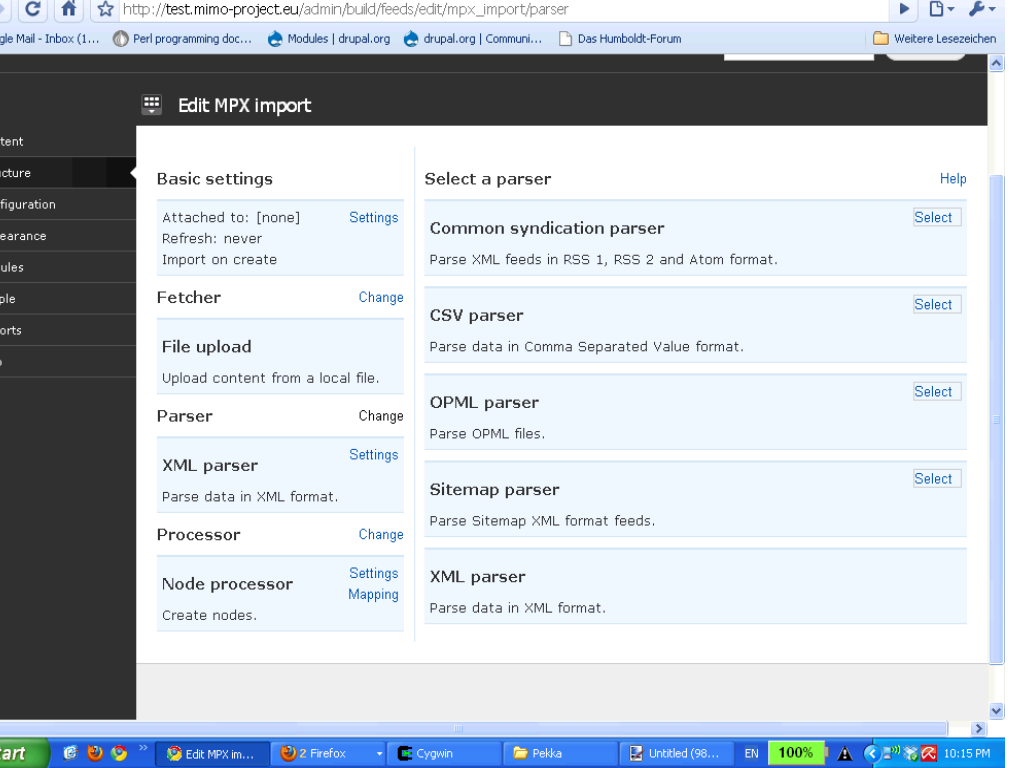
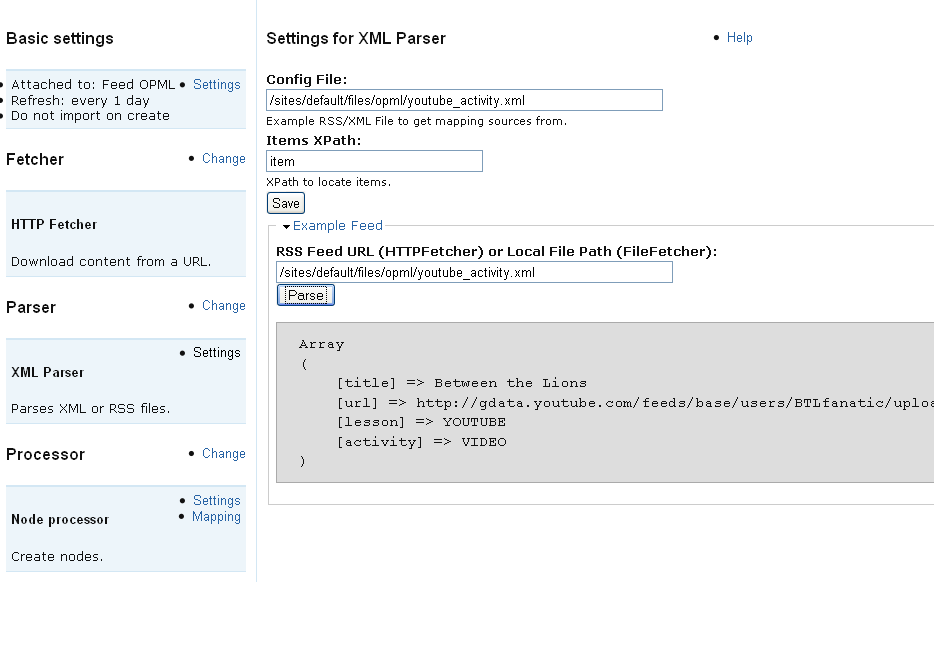
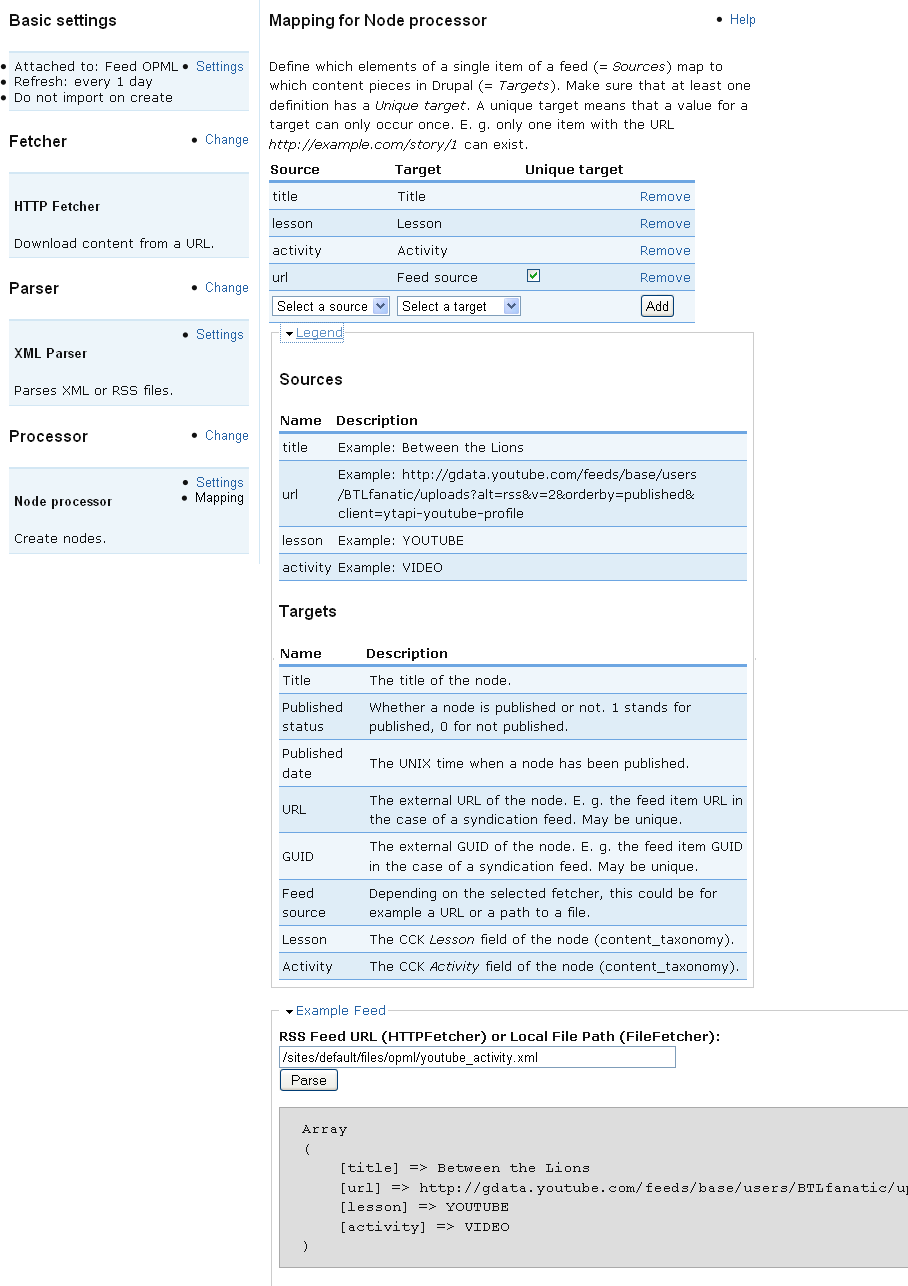
Features:
- parse any type of xml file finding items specified by XPath (see parser_settings.png)
- preview the parsed data
- gets mapping source targets dynamically (see mapping.png)
- groups alike single values and array structures together for easier data access (Advanced)
Cons:
- must specify an xml template file (normally just the file you want to import) in the importer settings
(this is the only way you can generate source targets)
Note: in the screenshots I use a relative url, this is a different patch of mine, Feeds only supports absolute urls
Comment #41
pvhee commentedWould there be a possibility to merge both projects (your Feeds XML Parser and the one I posted in the previous comment)? Note that I created a temporary Drupal project for this at http://drupal.org/project/feeds_xmlparser. However, I'd be more than happy to have it included into the Feeds module once the code is more or less finalized.
Comment #42
CheezItMan commentedInteresting, I'm trying to write a parser for an Apple Podcast Producer ATOM Feed. Seems like this could do the job perfectly.
However with Alpha12, when I try to Feed Imports-->Edit the feed of my choice and then select the parser, I get a whitescreen of death. Pretty much the same error I get on a parser selection.
Comment #43
serbanghita commentedOMG i'm subscribing to this and testing #40
Comment #44
minus commentedtested #40 with version 6.x-1.0-alpha12 and got a whitescreen of death as well - i'm trying to write a custom parser but have a hard time doing it :-/
Comment #45
pvhee commented@serbanghita @minus: did you try #41?
the module can be downloaded directly from github as eg zip file: http://github.com/pvhee/feeds_xmlparser/zipball/master. The XML parser is fully functional and does not require any feeds patches.
Comment #46
minus commentedthank you pvhee! didn't know it was updated, i had a version from feb.13 :-) will try this version right now :-)
Comment #47
minus commentedhmm, i'm trying to import the data from a xml test file which contains two fields, a description and an url. When i add these two fields using the XML Parser it gives me a error message saying
I'm really new to this and i guess this has something to do with either the person behind the computer or the xml file he uses :-/ If you have the time i could send you the url to the feed i'm using.
Comment #48
webwriter commentedSubscribing
Comment #49
serbanghita commented@pvhee actually #41 inspired me to create a custom module that extends Feeds and parse and maps Twitter search feed (eg. http://search.twitter.com/search.atom?q=starcraft2). Twitter search feed is not like a standard feed so it needs custom mapping.
I haven't tested the class inside #41. Will do in the next days.
Meanwhile i finally understand the approach of #40. Please correct me i'm wrong:
We need a parser that "knows" the
<item>fields we are about to parse, so we can select them from the dropdown and map them to our already created CCK fields. The approach of #40, with a sample file, seems to be the only logical solution. Will test #40 and post comments.Comment #50
alex_b commentedFYI - for some of you here maybe interesting #706984: Allow extension of FeedsSimplePieParser parsing
Comment #51
gaele commentedsubscribing
Comment #52
reglogge commentedI am using the module and patch from #40 and get a very curious behavior: Importing works just fine but there is only ever the last item from an xml-file imported. So on each import I get just one new node, even if there are many more in the feed
Any ideas?
Comment #53
Monkey Master commentedMy compact version of FeedsXMLParser (#39) with no need of external module (XML Parser) and with xpath setting (#40):
Comment #54
minus commentedhow can this be used :$
Best regards
minus aka Noob
Comment #55
Monkey Master commentedThis is alternative FeedsXMLParser.inc for feeds_xmlparser module (post #39) which uses SimleXML php extension instead of external xml_parser module
Comment #56
alex_b commented#53: You should be able to use xpath on the mapping UI easily.
Implement a
getSourceElement($item, $element_key)method:On execution, $item will be one of the simple XML items yielded by
$this->config['xpath']. $element_key will be a xpath entered by the site builder on the mapping UI.Comment #57
AntiNSA commentedsubscribe
Comment #58
Monkey Master commentedI implemented getSourceElement():
It returns the first string found at specified xpath since arrays are not accepted (lots of warnings, I tried)
Working module is attached.
Comment #59
Monkey Master commented#58 fails if number of items greater than 50.
SimpleXMLObject has big problems with unserialize() and FeedsSource->load() cannot restore batch object after first iteration.
Comment #60
Monkey Master commentedI don't see a simple way to fix SimpleXMLObject serialization...
So here's version without getSourceElement() with good old arrays.
Successfully tested on importing 9500 ubercart products with cck and filefield.
Comment #61
AntiNSA commentedIs that the best final solution?
Comment #62
AntiNSA commentedWhen I install and select this as the processor, only the bottom right has a drop down feild to select where to map things to. The left side field is a text entry fields,,, not a drop down list with options to select mappiingg sources from......
Is this how it is intended to work?
Comment #63
Monkey Master commentedYes, like csv-parser - just open xml file and copy field names to mapper settings.
When we configure mappings no xml file is loaded yet - nowhere to get field names from.
Comment #64
alex_b commentedVery interesting - the limitation is that it can only detect elements one hierarchy level deep in what's returned by config['xpath'] - correct?
Setting this to non-critical as we're keeping track of changes to upcoming release alpha 13 with 'critical'.
Comment #65
Monkey Master commentedyes, one level deep. Fits both of my projects I have at this moment - import uc_products from external program.
Version with getSourceElement() doesn't have this limitation.
Does anyone have a solution for SimpleXMLObject serialization problem?
Comment #66
srobert72 commentedSubscribing
Comment #67
blasthaus commentedsubscribing
Comment #68
Monkey Master commentedNew version of #58 with a workaround for SimpleXMLElement serialization problem: Items added to batch as XML strings and then parsed again individually in getSourceElement().
It supports xpath on the mapping UI.
Comment #69
xcusso commentedFresh install of #68 fail with this error Drupal: "error HTTP 500 /batch?id=53&op=do" in apache server log: "PHP Fatal error: Call to a member function asXML() on a non-object in /sites/my_site/modules/feeds_xmlparser/FeedsXMLParser.inc on line 24". Any ideas?
Thanks.
Comment #70
Monkey Master commented@xcusso: did you set correct xpath in XML parser settings?
An example of XML that causes this error would be helpful
Comment #71
hampshire commentedWhat else needs to be installed along with the files in #68 as I have tried every combination on this page it seems and I still have been unable to get this parser to show up on the select a parser page.
Thank you and sorry for the dumb question.
Comment #72
milesw commentedsubscribing
Comment #73
reglogge commentedsubscribing
Comment #74
Monkey Master commented@hampshire: you just need to enable module - Feeds XML Parser
Comment #75
Monkey Master commentedNew version
added support of multiple value fields and more checks (e.g. for #69)
xpath in XML parser settings is obligatory, defaults to "item"
Comment #76
gdud commentedsubscribing
Comment #77
AntiNSA commentedI am trying to use this with this feed :
http://feeds.pheedo.com/OcwWeb/rss/new/mit-newarchivedcourses
I have mapped:
title Title Remove
dc:date Published date Remove
dc:subject Taxonomy: User Keyword Remove
URL URL Remove
GUID GUID Remove
Body Body Remove
HTTP Fetcher
Download content from a URL.
XML parser
Parse data in XML format.
Node processor
Create nodes from parsed content.
XPath:
item
XPath to locate items.---------------------- whats this?
I keep getting the message that no update available...... everytime I try to import..... If you could tell me what I am doing wrong I would really appreciate it!
Thanks for all your hard work-
Robert
Comment #78
AntiNSA commentedI should say that everything works with the simple pie parser... I really would like to use your custom xml parser though! thanks again
Comment #79
Monkey Master commentedThis XML uses namespaces - not supported at the moment.
The XPath query that is executed on loaded XML file to get an array of XML nodes.
Then XPath queries from mapping UI are executed on that XML nodes to get source values.
(i.e. "Name of source field" in mapping UI is actually XPath for this parser)
So it's better to learn XPath before working with this module...
Comment #80
dvbii commentedI have been trying the XPath expressions to map the fields, but can't get them to work.
Using http://eventful.com/atom/richmond/events as my feed, and I set the XML parser Xpath to: entry
Then trying to map start time from the feed as "//gd:when/@startTime". I get no entries..
Any advice?
dvbii
Comment #81
Monkey Master commented@dvbii: This XML also uses namespaces (as #77), not supported. Any advises are welcome.
BTW Feeds module already has RSS/Atom parser.
Here's what I found:
Comment #82
dvbii commentedthanks for the reply. If I use the atom parser, how do i map other fields?
Comment #83
clevername commentedNot showing up for me either despite module being enabled. Subscribing in hopes for an answer.
Comment #84
gordns commentedI had the same problem with the parser not showing. Worked after using the "flush all caches" menu in the admin_menu module.
Comment #85
hampshire commentedI deleted the database and started from scratch but mine was a test site and not important, I never tried flush all caches, did that work for you?
Comment #86
Dmxr100 commentedHi, this is exactly what I'm looking for, and is working really well apart from one bit that I can't work out.
I have an XML feed from a News service which is importing fine, apart from categories -> Taxonomy.
Here is how a news article appears in the XML:
I'm not sure how to map the "Category" values to taxonomy, because they are wrapped within "Categories". Is this possible? If so I would greatly appreciate some instruction.
If I remove the "Categories" wrap in a test XML upload, the mapping works fine, however as it is a feed provided by a third party, they will not change the structure.
Thanks in advance
Comment #87
tinem commentedsubscribing
Comment #88
clemens.tolboomCould you please add a patch file here :)
Comment #89
Monkey Master commentedYes, just use xpath in mapping UI - try "category"
It's a standalone module, nothing is changed in feeds.
Comment #90
Dmxr100 commentedHi Monkey Master
Thanks for your help with this. Turns out I wasn't using the correct XPath syntax. So having "Article" defined in the XPath UI imports the node correctly, and using "Categories//Category" in the mapping to taxonomy pulls in the nested "Category" element.
Success :-)
Comment #91
robbertnl commentedSubscribing.
I am also using #75 now, now finding out how to map nested xml's
Comment #92
Exploratus commentedThis module works great. I was able to import using the XML Parser. My only question now is how do we import the images referenced in the XML feed so we do not have to download manually...
Cheers
Edit: Never mind, got it working...
Comment #93
alex_b commentedMonkey Master: Very nice work. You are clearly very actively developing feeds_xmlparser. I don't want to stand in the way as gatekeeper of Feeds module - why don't you break out feeds_xmlparser into its own project on d. o. or on github? I see that pvhee's already got a version on github:
http://github.com/pvhee/feeds_xmlparser
Comment #94
chrisirhc commentedHi there, just to add on, I've incorporated the code from Monkey Master into my fork of the github (at http://github.com/chrisirhc/feeds_xmlparser) as well as made an amendment myself.
I have a question though on Monkey Master's code and my amendment though, how come this was used (1):
Instead of just (2):
If there are issues with what I am doing, please let me know, because I used (2) in my code. I made the change because the current code (1) does not support queries for attributes (results will be blank) e.g.
/post/@titleAlso, I noticed in my testing of XPath to my knowledge, (1) seems to behave unexpectedly in certain cases. If needed, I'll be happy to post some cases here if anyone needs an example. Just ask! :)
Comment #95
Monkey Master commentedchrisirhc: you've incorporated old version, latest is in post #75
Comment #96
mokko commentedI am just checking back to see what's the status of this very interesting importer. I am interested in namespace support,too. To me http://www.php.net/manual/en/intro.simplexml.php looks like it supports namespace. Where am I wrong?
Comment #97
chrisirhc commentedSorry about that. Incorporated your latest changes. :)
@mokko Regarding namespaces, what kind of support are we looking at? Providing another field so that you can specify a namespace URI? or? I'm interested in getting it to work too.
I'm currently using Feeds with YQL (Yahoo Query Language) to do some imports. Also looking into doing up a fetcher that respects paging and 'staggering' requests (not sure if that's what it's called). I'm not sure if someone else is working on that now.
Comment #98
mokko commentedIn the meantime I found out that you are using drupal.org/project/xml_parser and I am reading through that code. I haven't found out yet how it all works. I am new to feeds etc., so I wasn't able yet to test if it works. I just have xml files that I would like to digest (import to nodes) and they have namespaces. I don't need this urgently, so I guess I will play with it a little more.
Comment #99
chrisirhc commentedThe latest code I used from Monkey Master does not use xml_parser . It uses the native SimpleXML support in PHP.
I believe in order to retrieve the namespaced elements, you need to specify the namespace before retrieving it. This can be done by listing the namespaces in the Feeds XML Parser settings page. I might consider adding this. It should be just a few lines of code I think.
I dug up an example of SimpleXML with namespaced elements. You need PHP 5.2 and above to get it to work.
http://www.ibm.com/developerworks/library/x-simplexml.html
http://sg2.php.net/manual/en/simplexmlelement.registerXPathNamespace.php
It looks rather expensive but the following could be a simple fix to allow namespaced xpaths:
I'm committing and pushing to the git.
I can already think of a possible problem that might occur. While you might be able to get the namespaced elements out, after that, during mapping, there might still be other challenges.. If the namespace does not persist till the
getSourceElementmethod...(Night, I'm off to sleep.)
Comment #100
Exploratus commentedHi everyone.
Quick question. Is there a way to get the value inside the category, not just within the brackets.
this is what i mean:
i can get the value
whatever
but how do I get the value from within the brackets, like this:
How do I pull the venue ID "106543".
Thank you so much.
Comment #101
chrisirhc commentedPlease put everything that is code within the <code></code> tags when giving code examples here.
Anyways, I think you're talking about attributes (
<el someattribute="blah"/>) right?You have to use the @ symbol to refer to attributes.
Take a look at the following links for some information on XPath.
http://www.w3schools.com/xpath/xpath_syntax.asp
http://www.quackit.com/xml/tutorial/xpath_attributes.cfm
Queries on XPath should be somewhere else.. This is a thread on the issues regarding the parser.
Comment #102
Exploratus commentedSorry about that, that is exactly what I wanted. I didn't realize that the Drupal Forum took the codes out...
Comment #103
mokko commentedI have problems installing the feeds_xmlparser. A few more details here: http://drupal.org/node/800256. Any help appreciated.
Comment #104
ChaosD commentedsubscribed
this functionality would add a lot of value to the feeds module. how usable is it so far? do you need help with testing?
Comment #105
mkalisz commentedsubscribing
Comment #106
chrisirhc commentedHelp needed to test whether it works with namespaced XML documents (or any other documents).
You can download it from:
http://github.com/chrisirhc/feeds_xmlparser
Comment #107
Exploratus commentedI am using namespaces and it works fine...
Comment #108
sagar ramgade commentedHi,
I am using feed_xmlparser with xml_parser, I am not able to import data inside the subtags of xml file, however if i save the file and Remove those parent tags like media, media item, it is able to fetch data.
I want to fetch data inside the caption, mediaUrl, datePrefix etc.
The xml file which i am trying to import is attached. rename it .xml
Comment #109
ChaosD commentedread #90 - that helped for me
Comment #110
sagar ramgade commentedHere's my first item :
I tried //media//mediaItem//caption and //caption
Both of them didn't work.
Could you help please ?
Comment #111
ChaosD commenteddon´t forget to set your xpath in /settings/FeedsXMLParser to your "node identifier" (thats how i called it). in you case it would be "article". for the mapping you should use "media//mediaItem//caption"
Comment #112
sagar ramgade commentedThank you for you reply but i couldn't see that xpath setting anywhere, i am using httpfetcher and using a custom content type for importing.
Where do i find this setting, I might be acting dumb sorry for that however i couldn't find it anywhere.
Comment #113
sagar ramgade commentedHi,
Actually i was being dumb i didn't read the thread carefully, i was using this http://github.com/pvhee/feeds_xmlparser
instead of http://github.com/chrisirhc/feeds_xmlparser.
I could see that xpath setting now, however need to test it with the settings.
Will update here if successful.
Comment #114
sagar ramgade commentedHi,
It worked like a charm, I am using Feeds Image grabber module to fetch images too...
Thank you all who worked on this.
Cheers
Comment #115
tfranz commentedIm getting the example.xml of chrisirhc/feeds_xmlparser to work, but doesn't succeed with my own XML-file:
I tried master//customer//product and only product – as XPATH, but none of them worked ("There is no new content") ...
I need the following mapping:
tech//id => GUID
tech//name => Title
object//objecttyp//value@valuetyp => CCK-Textfield
Thank you for any help or hint,
Tobias
Comment #116
sagar ramgade commentedI think you need to set Xpath as //customer and then
product//object//objecttyp//value@valuetyp => CCK field
product//tech//id => GUID
product//tech//name => Title
Hope this helps.
Comment #117
Thoor commentedFirst of all - THX to all who worked on this Issue! Great Job!
The example.xml is working fine for me and my example from january in http://drupal.org/node/631104#comment-2437960 is almost working now, when I use the http://github.com/chrisirhc/feeds_xmlparser in addition to the FEEDS Module.
But I still have a problem I can´t solve. As you can see, there is a socalled XML SCHEMA in the Feed I want to use.
With this line in the feed i receive the message ("There is no new content") ... while importing.
When I change the line manually to
<products>... everything works fine and I can parse and map the XM Feed!Does anyone have a solution, how I can successfully handle the additional XML Schema in my Feed with FEEDS and the FEEDS_XMLPARSER?
Comment #118
srobert72 commented@thoor
Not a solution to your problem, but just a workaround.
With Zanox you could also use CSV export instead of XML.
Comment #119
chrisirhc commented@Thoor
Is that line proper XML? I notice there's a space in the URL and there are no quotes.
Should it be:
Will have to look into this issue if it persists even if it's proper validated XML.
Comment #120
Thoor commented@chrisirhc
The line is how it is in the feed. An example feed can be seen under: http://wiki.zanox.com/en/Product_Data_Download#Example_XML_file
I don´t know, if this is proper XML?
@srobert72
THX for your reply! I knew already, that CSV import works well with FEEDS. Also the "Classic XML Feed" from Zanox is working good! Because there it is possible to turn the XML Schema "off"! Without it, FEEDS with FEEDS_XMLPARSER is working without Problems!
Comment #121
TimG1 commentedHi Chris,
Huge thanks for your work on this!
I've been messing around testing this for a bit today. I have a feed full of namespace prefixes. Importing works fine for elements with no prefix, but for the elements with a prefix I get a page full of errors like this...
I have a bunch of elements such as
I can send you the feed I'm working with via your contact form if you would like to mess around with it.
Thanks again!
-Tim
Comment #122
tfranz commentedHi Sagar Ramgade, thanks for your reply!
I tried:
XPath: //customer
product//tech//id => GUID
product//tech//name => Title
At least it created one empty node, and i got the following error (3x):
Line 321 is return mysql_real_escape_string($text, $active_db);
Any idea?!
Comment #123
mokko commentedUsing chrisirhc's feeds_xmlparser I ran into the "mysql_real_escape_string()"-warning too. I looked into it a little bit.
In my case it comes up when my source xml has two title-elements while drupal has only one title. I can create a cck field title which allows multiple values, use xmlparser to map to the CCK field (instead of drupal's title) and then this warning disappears. Not sure this work around is what you want. At least then you should be able to import all your nodes.
Comment #124
mokko commented@Thoor: I also looked into using namespace with chrisirhc's feeds_xmlparser. My understanding is that currently default namespaces are a bit problematic with the module. I ended up naming my namespace. Something like:
In the xpath setting I use
//default:products
I compare this functionality to my xml editor (oxygen). If I remember correctly it has an option where it replaces no namespace with default namespace. If feeds_xmlparser would do this, you could use your original xml with your original xpath setting
//products
Hope it helps
mokko
Comment #125
tfranz commentedI tried the following:
Xpath: //customer//product
//tech//name => Title
//tech//id => GUID
... and it works! Thanks for your help!
Comment #126
alex_b commentedRepeating what I said in #93: Does anyone want to break out this module into its own Drupal project? Seems like there is a large enough user base to justify it - just the issue queue that comes with it would be a big help for maintaining it :-)
While I welcome feeds_xmlparser to the Feeds ecosystem, I am not planning on committing it (or a similar extension) to Feeds at the moment - it is an extension that requires high involvement with its user base and I am personally not dealing with its use cases.
Comment #127
steven jones commentedI think it's been done: http://drupal.org/project/feeds_xmlparser
Comment #128
mokko commentedI am probably repeating what everyone knows here already :
- it seems that pvhee created http://drupal.org/project/feeds_xmlparser and
- we were last talking about chrisirhc's fork of that code.
Both have a hosted their module on github (more than d.o), see e.g. http://github.com/chrisirhc/feeds_xmlparser.
Both have been quiet for at least a few days.
I am not very familiar with github. It seems for hosting the code it's fine. I miss drupal's issue queue and would prefer to use the http://drupal.org/project/feeds_xmlparser issue queue for chrisirhc's fork, but currently I think this would risk confusion. This would be somehow along the lines suggested by alex_b.
To me it seems the easiest would be if chrisirhc and or pvhee would say something. Any other suggestions?
Comment #129
podox commentedVery excited by this, especially the namespaces development. I'm having trouble importing the following feed:
http://rss.oucs.ox.ac.uk/oxitems/generatersstwo2.php?channel_name=classi...
The format is as follows
I've tried a combination of channel//item, item, //item //channel and many more as the Xpath setting, with //title as the sole mapping setting, but I get the error "Could not retrieve title from feed" on import.
Comment #130
mokko commentedWarning:I don't know much about RSS , so my wording might be strange.
Of course, you have two different titles: the channel title and the item title. I assume you want to map the item information. Correct xpath should be one of two
Then you should be able to map the title by entering "title" in the mapping. This should work definitely. With itunes namespace I am less sure. Try separately.
In the namespace tests I made successfully only my root element has a namespace.
You should be able to enter itunes:author in the mapping, but I am not at all sure this does work.
Of course you have to be using http://github.com/chrisirhc/feeds_xmlparser
What do the others think?
Comment #131
chrisirhc commentedHi there everyone, apologies for the disappearance, I have been watching this thread but did not realise that it was awaiting me or pvhee's input.
pvhee has contacted me about co-maintaining the module with him. I've responded that I'm interested but he has not since responded. I believe he is busy at the moment. He has plans to bring the module from git back into the CVS system to be downloadable from the module here.
Comment #132
podox commentedThanks mokko. I do want to map the item information to the feed item node, and /rss/channel/item works (for the item title, description, media file URl etc.) Not sure how to map the itunes info (itunes:author doesn't work but I'll keep trying).
The error message comes about from not entering a title in the *feed node* - you have to enter it manually with the XML parser, whereas with the common syndication parser, the feed node title is correctly generated automatically from the source feed.
Thanks for your help - looking forward to seeing this develop.
EDIT: See http://drupal.org/node/838172#comment-3134636 for working mapping settings, including a way to map itunes:author
Comment #133
arski commentedsub
Comment #134
arski commentedHey,
I just installed feeds_xmlparser on my site but when I create a new feed there seems to be no new "XML Parser" option or anything like that in the Parser section. Any ideas what's going on?
Thanks,
Martin
PS. I agree with the post above - please please move the code to d.o. CVS asap - that will make it so much easier for everyone to test/submit issues/comments.. you don't have to make a release until you're ready, but at least the code/issues will be all in one place :)
Comment #135
mokko commentedI think I had that problem at first, too, but I don't remember exactly what was the problem. Did you check the rights of feeds_xmlparser directory? I attach a screenshot of how it looks for me. Hope it helps.
Comment #136
arski commentedUmm yea that's what I expected to see too.. the rights seem to be the same as for any other directory, don't think that should be a problem.. you really don't remember what you did to fix this? :)
Comment #137
arski commentedGah.. got it.. I clicked on the "Download Source" button at the top of that github page and apparently I downloaded an old version of the module with basically empty code files.. great stuff :/
After I got the latest individual files manually - you still need to flush your cache for the XML Parser option to appear.
Just writing this down so that anyone else having the same trouble can read up :)
Other than that, let's try this out! :)
Comment #138
TamboWeb commented@arski
Have you tried clearing your cache? Go to administer>site configuration > performance at the bottom, clear all cache.
I am currently doing testing with namespaces I will be reporting my findings sometime tonight.
Sandro.
Comment #139
arski commentedHey, well yea, as my 2nd post (#137) says - there were 2 issues, including a cache one.
Having tested the thing out - hats off, works like a charm! :)
Comment #140
TamboWeb commentedI just imported 65 nodes from an xml file. I had to do a small change to the code to be able to import xml node elements within a namespace without prefixes. Other than that, it works great.
Comment #141
TamboWeb commentedIssue parsing xml file with namespaces.
Setup: Using chrisirhc code from http://github.com/chrisirhc/feeds_xmlparser,
This is just an observation as I am not much of a coder. I am not implying that this is a bug nor it is a fix. Somewhere in the posts above there is mention that namespaces are not supported. On the other hand some posts indicate successful results. For my particular application this is a workaround until I find a robust solution compatible with the module. I am not intending to hack the module.
It seems that the module is unable to import content if the XML file used as a source of content contains XML nodes elements with namespaces but without namespace prefixes. The module responds with no content found or with an error depending on the parser xpath setting.
Sample xml (truncated for simplicity sake):
When trying to parse the above code with xpath, the module responds with no new content found.
If I remove the namespace from the Listing element, then the module parses the code correctly. This however is not ideal since the xml file will be updated daily with cron. I am not sure I want to manipulate the xml file with a search and replace, nor I want to do it manually prior to parsing.
After reviewing the code in FeedsXMLParser.inc Line 29 through 35,
I realized that there are no prefixes in the namespace, so there is no reference to the Listing element. Hence no content is found.
I proceeded to experiment a little, by hardcoding the namespace and the prefix as follows:
and changed the “Settings for XML parser” xpath settings to //default:Residential.
Now all nodes are imported without errors. It seems that the Fetch all namespaces needs some revision to accommodate for namespaces without prefixes since a blank prefix cannot be registered.
Sandro.
Comment #142
mokko commentedyes, Sandro! This is similar to what I meant in #124. I didn't see that this has consequences for the import (updates). I don't get why is it not necessary to register the usual namespaces (via $xml->getNamespaces(true)). Shouldn't we just add default for default namespace?
Anyways, I guess we now need a generic way to access namespace without prefix. Apparently ->getNamespaces does not work. Then ->getDocNamespaces will also not work, will it?
At http://de3.php.net/manual/en/simplexmlelement.getDocNamespaces.php it says:
This doesn't sound good. It probably means we can access only one default namespace. That would be an improvement though. When I have some time, I can look into it tonight or so.
Comment #143
robbertnl commentedWhat about performance? i am using this, when importing a 8 mb XML file. It works but it eats a lot of memory ( about 1,5 gb) and several hours to complete.
Well i am doing some processing (creating users, content profiles, groups and importing small images), but i don't think it should take that long. I think it's an issue of XML Parser, but maybe also for this Extensible XML parser ?
Comment #144
TamboWeb commentedHi mokko,
Thanks for the input and the link. I will take a look at that information as well. Currently I have to pull away for some time to take care of another project but I will get back to this as soon as I can.
Comment #145
TamboWeb commentedrobbertnl
Regarding #143,
I am also concerned about performance. I have read somewhere that Xpath was slower than using the native php xml funcitons (i think). Eventually, my application will be doing some processing as well. So far this is a good start and proof of concept.
One feature that i need would be to be able to delete nodes referenced by another xml file. For example, import new content from xml file #1. then later, delete content specifed on XML file #2. So far the Feeds functionality allow you to delete content from the same feed only.
Another feature would be to be able to specify a feed import via cron. For instance run import of xml file #1 daily. and Run delete nodes as per xml file #2 every other day.
If anyone know who to do this I would be interested in hearing some pointers.
Thanks.
Comment #146
sagar ramgade commentedHi,
The xml feed which i am trying to fetch contains date as shown below
I tried to map with the my cck date field (date or datetime tried both ), it gives me an error message :
warning: DateTime::__construct() [datetime.--construct]: Failed to parse time string (18/06/2010) at position 0 (1): Unexpected character in /../sites/all/modules/feeds/plugins/FeedsParser.inc on line 388.
In my cck date field i have set the custom input format to d/m/Y which should ideally match with the date format in the xml file, however it doesn't import anything stops with the error message mentioned above.
Comment #147
rjbrown99 commentedIt seems like this issue has started to become a catch-all for any problems related to XML parsing. Since the issue was first created, we now have a Feeds XML Parser module and a dedicated issue queue for it.
Would it be too much to ask that we take any new issues, problems, or questions and break them out into separate items?
Comment #148
michellezeedru commentedPlowing through this, knowing next to nothing about feeds and RSS, I was able to follow leads from this thread and set up a successful importer for an XML feed. Thought I'd subscribe to keep aprised of progress and also share my scenario, in case it's helpful to anyone else.
Setup: Using chrisirhc code from http://github.com/chrisirhc/feeds_xmlparser
The feed I'm trying to import looks like this:
In my feed importer>XML Processor settings, I set X-Path to //item
In mappings, I set up the following sources to map to CCK fields:
And it works -- for the most part! The feed apparently contains no type of unique identifier, so updating is not working. I guess my next step is to work with the producer of this feed to include GUID in the feed?
Thanks for the work on this everyone.
Comment #149
ChaosD commentedyou could use the
<link>as guid because its most likely unique and wont give duplicates (assuming that each item has a own link on the original site) ... title might also work but personally i would not rely on that.Comment #150
meatbag commentedWhen i test chrisirhc's xml parser on the following feed, i always get the "no new content" message.
So i try to remove sth from the feed while keeping other settings untouched.
And it works this time! But i just can't figure out why it failed to parse the first one.
Any helps would be appreciated.
Comment #151
meatbag commentedOk i figure out that maybe namespace without prefix is the reason...
Comment #152
sagar ramgade commentedHi All,
I want to fetch the Home team, away team score, MATCHDETAIL attendance.
I am able to fetch the match id , home team name, away team name However not able to fetch home team score, away team score and attendance.
Can anyone help.
I had set the xpath as : //XML//DETAILS
//HOMETEAMNAME[@SNAME] => Title
//HOMETEAMNAME[@SNAME] => Home team term
//AWAYTEAMNAME[@SNAME] => Away team term
//MATCHSUMMARY[@ID] => GUID
//MATCHSUMMARY[@ID] => matchID
//MATCHSUMMARY//HOMETEAMSCORE//SCORE => home team score
//MATCHSUMMARY//AWAYTEAMSCORE//SCORE => away team score
//MATCHDETAIL[@ATTENDANCE] => attendance
Comment #153
mason@thecodingdesigner.com commented#75 works for me. Thanks Monkey Master!
Comment #154
ChaosD commentedis this related? http://drupal.org/project/feeds_xpathparser
Comment #155
twistor commentedIt is related to the problem at hand. Currently (if you check out from cvs) XPath, Regex, and QueryPath are supported. I think I solved the namespace issues that exist with SimpleXML. I was unaware of this thread when I started this project, but it seems that the amount of duplicated work is minimal.
Comment #156
ChaosD commentedmaybe you should consider merging your projects as an extensible parser for feeds
Comment #157
twistor commentedI'm not opposed to that. I've been thinking about breaking up the functionality of Feeds XPath Parser into different modules, however, I'd like to enable per-field query types. Such that you can use XPath for one field, regex for the second, and QueryPath for the third. The name is not so great for the functionality I do admit. The only thing about merging is that Feeds XML Parser configures the queries in the mapper and Feeds XPath Parser configures them at the endpoint. One allows for greater flexibility, one allows for more control of end users. I'm open to ideas.
Comment #158
ChaosD commentedmaybe you could call it feeds flexible parser as a collection of all those methods you mentioned. iam currently happy with the configuration in the mapper but i have to admit that iam not too familiar with XPath parser
Comment #159
meatbag commentedThe "entensible" XML parser supports only xpath
while the XML "Xpath" parser supports xpath, querypath and regex...
Really confusing...These two modules should swap their names...
Comment #160
blasthaus commentedare there any immediate plans to finally integrate namespace support? or any tips to get several different namespaces registered or even just hardcoded for now? lookin' fwd.
wil
Comment #161
mokko commentedAs mentioned frequently in this thread, Chrisirhc's version supports namespaces basically: http://github.com/chrisirhc/feeds_xmlparser
Did you already check out if this version meets your requirements? If I remember correctly it does handle multiple namespaces well, but has problems with default namespaces. Please be more specific.
Also: I haven't had a chance to look at the new http://drupal.org/project/feeds_xpathparser if this might be an alternative.
Comment #162
fereira commentedI am having some problems with namespaces as well.
The XML that I'm using defines several names spaces. Here is a small snippet of the code
<ags:resources
xmlns:ags="http://purl.org/agmes/1.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:agls="http://www.naa.gov.au/recordkeeping/gov_online/agls/1.2"
xmlns:dcterms="http://purl.org/dc/terms/">
<ags:resource ags:ARN="KE2009400905">
....
</ags:resource>
First of all when the the $namespaces = $xml->getNamespaces(true);
line gets executed it silently ignores the "agls" name space. I poked around a bit and found that the uri for that namespace doesn't appear to be valid anymore. If I change it to http://www.naa.gov.au/agls/ then the prefix and namespace showed up in the $namespaces array.
Secondly, I haven't been able to come up with some XPath yet that will parse the attribute of the each of the ags:resource elements. Even when I've hardcoded the registerXPathNamespace function calls with that correct list of namespaces I get the following errors:
warning: SimpleXMLElement::__construct() [simplexmlelement.--construct]: namespace error : Namespace prefix ags for ARN on resource is not defined in /www/html/feedsdev/sites/all/modules/feeds_xmlparser/FeedsXMLParser.inc on line 57.
That's failing when the $xml = new SimpleXMLElement($item); line is executed in the getSourceElement function.
The problem for me is that the attribute what I need to use for the unique GUID mapping.
I wonder if doing something like the evoc module is doing might work. It keeps a couple of database tables for rdf name spaces and uses a simple form element for adding the prefix and namespaces that are used by the rdfcck module for assigning rdf classes and properties.
Comment #163
mokko commentedFrom the xml snippet you are posting I would assume that you want to set xpath to ags:resources and
resource/@ARN as GUID (unique target).
(assuming that you do really have recourse tags inside resource tags as in the snippet).
I haven't used xmlparser with namespaces for attributes.
I don't know about your concrete problem with the agls namespace. Can you find something here http://www.php.net/manual/en/book.simplexml.php?
Comment #164
fereira commentedYes, each ags:resource element is a unique resource identified by the ags:ARN attribute in that tag and they are nested within an ags:resources element (that's resources, not resource). Sorry, I didn't provide the closing ags:resources tag. Here's a real example:
http://mayfly.mannlib.cornell.edu/agrisdata/agris.xml
That content is using a schema developed by FAO of the UN for identifying resources held in an Agriculture Information Systems and is in use by dozens of institutions worldwide.
There are other issues that seem to be causing problems with the module as well. I notice in the feeds_xpathparser module that for each field one can specify whether or not to show the raw content. When parsing this xml using that module I had to tell it *not* to show raw xml for any element that had content wrapped with a CDATA tag.
The dc:description element for at least one of the resources contains html entiies (‘, ’) and I'm seeing errors on those elements as well.
In any case, I think a handbook with lots of examples of XML content with more complex structures with examples of XPath for parsing them, will go a long way to demonstrating just how flexible the module can be and may require code changes to handle all the possible *valid* xml constructs.
Comment #165
fereira commentedForgot to comment on your suggestion about the simplexml book. I had looked at the site but it didn't really answer all my questions.
I'm not so concerned about the agls namespace as that can be corrected in the Agris documentation, though it would seem to me that the getNamespace function should produce an error (and return false) if one of the namespace uris doesn't resolve correctly rather than just excluding it from the list.
More concerning, to me, is that when it's instantiating the new SimpleXMLElement class that it generates a warning about the ags namespace. I didn't see anything in the simplexml book but can a new SimpleXMLElement be instantiated with contains namespaces?
Comment #166
blasthaus commentedi am using chrisirhc version and its not recognizing my media namespace, alas
maybe i'm not doing something right?!
thx-wil
Comment #167
meatbag commented#166
The urls are set as attribute of the tag, so they can't be parsed out.
You need to write a customized version to do that.
Comment #168
podox commented#166 Try...
...etc. Use /rss/channel/item as the Xpath setting
Comment #169
vaene commentedHaving same issues as #166, tried
but got this error for each attempted import:
it imported other non-namespaced tags in the item tag so my original Xpath setting is correct I am assuming.
Sorry if I missed this before in the chain but could you give us a hint as to how to go about writing a custom parser that would specifically work for capturing attributes of media namespaced tags?
Comment #170
Fidelix commentedOMG i want this badly. Is it working ATM ?
Comment #171
blasthaus commentedthx podox, i tried that and get this error
i assume this is where we need to be looking around line 28 of FeedsXMLParser.inc
question is how to get url attributes within a namespace tag, however it doesn't even look as if the namespace is getting recognized here.
thx-w
Comment #172
meatbag commentedTo deal with attributes and namespace better, i suggest using QueryPath as the parsing interface.
Here's an article by the QueryPath author which helps a lot.
http://www.ibm.com/developerworks/opensource/library/os-php-querypath/
Comment #173
podox commented#169 There is an asterisk before [name()='media:thumbnail']/@url - could you try again?
Comment #174
SeanBannister commented@meatbag QueryPath would be awesome, it's amazingly powerful and surprisingly much simpler.
Comment #175
twistor commentedNo to toot my own horn, the feeds_xpathparser module has tentative support for QueryPath in dev. I need people to test it out. All the features aren't currently implemented, but anything you can do with XPath should be accomplishable at this point. I agree that the syntax is much simpler plus it avoids having to learn yet another syntax.
Comment #176
arski commentedhmm, any chance of actually having this module on d.o. anytime soon? You don't have to make a stable release straight away, but it would be nice to have the code in a proper place..
also what goes for the issues - it would be really great if you could take a look at the other issues reported for this project in here, and also maybe we should start splitting them a bit more instead of continuing in this 175-reply thread :o
Looking forward to this module!
Cheers
Comment #177
meatbag commentedI modified the module to use QueryPath as parsing interface. It works perfectly for me.
Here's the code.
Note: This just serves as an example for those who want to know how QueryPath works.
You may need further modification before using it on your own server.
Comment #178
robbertnl commentedDoes this work with batch support as wel (see http://drupal.org/node/744660)?
Comment #179
fereira commentedI'll toot your horn for you. The latest version of the feeds_xpathparser works really well. It would probably worth going through this issue to see if there is anything that could be added to the xpath parser but as I see it, there isn't any reason to keep this (feeds_xmlparser) around as the feeds_xpathparser does about everything one would need, its' easy to use, and it's even fairly well documented.
Comment #180
twistor commentedCleaning old issues.