
Closed (fixed)
Project:
Feeds XPath Parser
Version:
6.x-1.x-dev
Component:
Code
Priority:
Normal
Category:
Support request
Assigned:
Reporter:
Created:
24 Jul 2010 at 19:02 UTC
Updated:
20 Feb 2011 at 21:20 UTC
Jump to comment: Most recent file

{kind=link}
Comments
Comment #1
brycesenz commentedI have a similar request. My assumption going in was that HTML would rely on XPath notation as well, but when I tried to use the module in this way, I received the following error message:
String could not be parsed as XML.
I assume that this is just a result of me using the tool incorrectly, but I would love to know how I'm actually supposed to be setting the parser up.
Comment #2
iantresman commentedYou'll find some documentation in this thread, and I'm sure there is more to come, once development work on the modules has been completed.
Comment #3
brycesenz commentedI sincerely appreciate the note, but I've been through that post and I'm still not sure how to solve my problem. My previous post was fairly vague, so let me clarify what I'm trying to do.
I have an HTML document that I would like to parse using XPath expressions. I don't know for sure if this is a supported way to parse an HTML document, and if it's not, then what the appropriate syntax is to actually parse HTML. However, I've played around with a few things I thought might work, and here are the results -
1. Selecting the parser as XML, and using XPath syntax. Result = hundreds of error messages.
2. Selecting the parser as HTML, and using XPath syntax. Result = error message ("String could not be parsed as XML") and failure to import.
3. Selecting the parser as HTML, and using HTML tags to try to select the relevant fields (e.g. ""). Result = error message ("warning: Invalid argument supplied for foreach() in ...\feeds_xpathparser\FeedsXPathParserHTML.inc on line 54.").
Any thoughts/suggestions?
Comment #4
twistor commented@brycesenz, #2 is indeed the correct approach. Is there any way you could give me the link to the page? Maybe a sample? Either way, some example xpath queries would be helpful.
Comment #5
brycesenz commented@twistor, sorry for the very delayed response; i'm out of the country at the moment. Anyway, good to know what the appropriate use case is. I'm currently testing valid XPath queries on a few different instances of HTML documents, trying to make some sense out of the fact that I sometimes get this error and sometimes do not. I'll report back when I have something meaningful to share, assuming that the problem still appears after upgrading to the latest version.
Comment #6
dman commentedApproach #2 is correct.
However, given the badness of HTML in the wild, there may be documents that the initial parser (even in HTML mode) can't make sense of.
If you try to validate the target document and get heaps of errors - then the source input isn't really HTML at all, just an approximation of it. This means you may be out of luck, using the available tools.
To really solve this, if it's even possible, something would need to be added to the pipeline to run the input through HTMLTidy first. I've done that before. It's currently not part of this modules feature set though.
Comment #7
iantresman commentedThere is an HTMLtidy module for Drupal, don't know whether it can be used.
Comment #8
brycesenz commented@dman,
Good call - the HTML does not validate. HTMLTidy makes sense; is there any reason why it should be out of scope for later stages of this module's development? I just can't see a logical reason why this functionality should be a separate module altogether. By the same token, I'm guessing that if I'm running into this problem then others will as well.
Comment #9
dman commentedReason 1 is the htmltidy module is larger than this one right now.
Even cut down to just the necessary moving parts, it's a tricky dependency as it relies on installation of code on the server. Not an obstacle we'd want to introduce.
An approach may be a Drupal-style 'hook' that allows a plugin module to optionally massage fetched content before parsing, but I don't see this as the job of the XPATH parser module itself. There exists some HTML that is so bad even htmlTidy can't fix it (Damn you paste-from-word!)
For horrible input, you may look instead at the (proposed) regex parser alternative.
Comment #10
twistor commentedhmmm...
Installing the tidy extension on Ubuntu is as simple as apt-get install php5-tidy. I've been running into this myself. I think we may be able to do a conditional form, with a subset of options, if the extension is found. I'm going to look into this.
Comment #11
twistor commentedOn second thought, I've got a module in the works called Feeds Tamper that will allow for data munging pre and post parsing. This would make more sense to go there. Should be up soon.
Putting the issue back in case there are more questions.
Comment #12
twistor commentedIf anyone desperately needs this functionality, they can install tidy with 'apt-get install php5-tidy'. Make sure you restart apache! I know it supposedly restarts during the install but you have to stop and start it.
Then change the parse function in FeedsXPathParserHTML.inc to:
No guarantees, but this has helped me quite a bit. You can check the options for that function at http://tidy.sourceforge.net/docs/quickref.html. They're a beast.
Comment #13
ckreutz commentedWith the 6.x-1.01 version I managed to parse nicely different HTML files. For example to extract values from a table I used xpath such as:
//tr/th[@class='style1'] or
//tr/th/strong.
Works like charm. However, when I tried the same with the dev version I encountered several problems and did not manage to parse the same pages. (It does not show me any error messages!) I wonder why the context is a necessity? For example in a HTML file I might want to parse values from different contexts and not only for example from a specific table. In that case I guess I need to set the context to //body?
By the way the module is awesome! Thanks a lot!
Comment #14
Kraftway commentedHi,
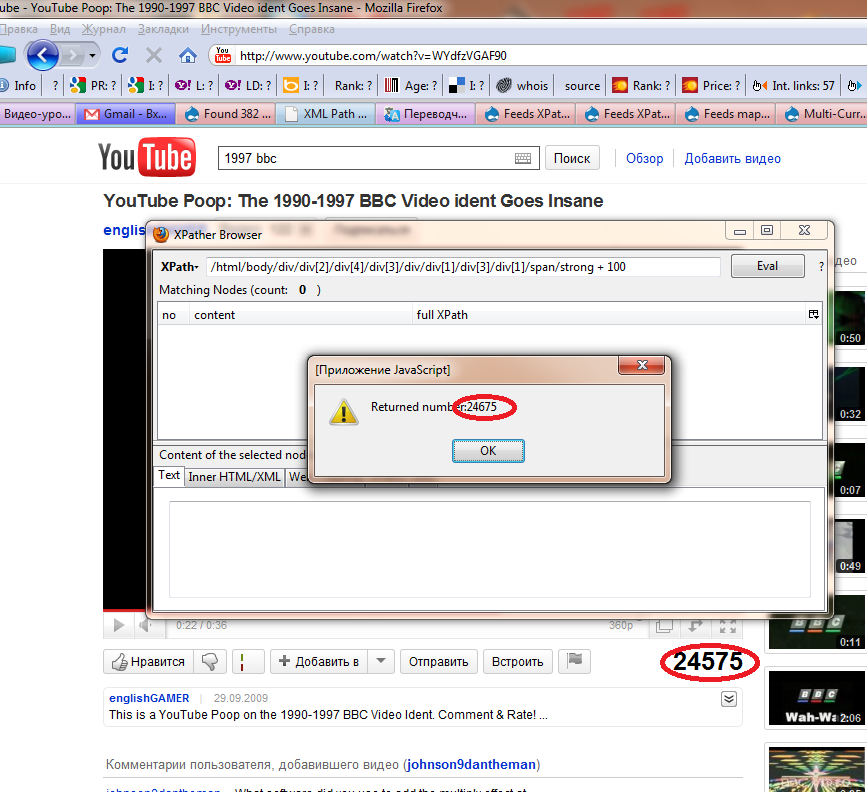
I tested this module and need to explain some questions about it. The first is how to use the math expressions in the query? XPath docs describes number expressions but i find no way to use it while Firefox XPather evaluates it successfuly (see attached screenshot). When i try to use this XPath query in the node import form, it returns nothing.
Many thanks for module again! )
Comment #15
twistor commentedThere was a problem with how SimpleXML handled functions in XPath. I've rewrote it to use the DOM instead. These should now work as expected. I could use some feedback on how it works. Thanks. You can find the new version in dev.
Comment #16
dman commented(Bravo for moving from SimpleXML to the real DOM!)
Comment #17
twistor commented(It put a few hairs on my chest.)