Problem/Motivation
If there is no translation for a text string Drupal displays the untranslated string, or the text string from another fallback language. In both situations the text is in another language and so we need for wcag2 a language attribute in the html element around the text.
The problem with trying to implement this is that when t() or format_plural() is invoked, we don't know if HTML is generated. We cannot just output HTML wrapped text if what's generated is for an email or an XML format like RSS. We don't have that information, so we'd risk breaking all emails and RSS feeds generated by the site if we'd do.
Several solutions were discussed:
1. Handle every untranslated string as an error.
2. Make a smarter t()-function, that can accept html=true/false and/or that return an array (translated yes/no, plain/html, language)
3. add invisible unicode characters to the untranslated string and replace that while html rendering with language code
Ad 1: Not a solution anymore as we now also have language fallback for t() in core
Ad 2: this is proposed by Mike in #9, Gabors answered in #10 that this is hard or impossible to tell for module developers.
Proposed resolution
There are language tags in unicode, but they are depreciated (but not forbidden). No browser and text-to-speech-software will handle this unicode characters. However, we could use this unicode character as an helper and replace it for real language tags during rendering.
The English language tag in Unicode characters would be: U+E0001, U+E0065, U+E006E
End the end tag would be: U+E007F. During html rendering we could replace them with lang="en".
Remaining tasks
- unicode language tag characters are 4-byte, and Drupal can't handle 4-byte unicode yet
- test if we can replace the unicode characters with javascript to html
- test if the language tags don't break email, rss, etc
- check if we should filter the unicode characters away in certain functions
User interface changes
None
API changes
We will get extra invisible unicode characters in many places. From email to RSS. Some text functions might need adjustments.
---
See also the discussion in the accessibility group http://groups.drupal.org/node/145894



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
mgiffordShould it be in English or in the default language chosen by the user?
Comment #2
hanno commentedIt assumes that text strings of Drupalmodules are in the English language, as that is a Drupal localization rule (http://drupal.org/node/322729)
If the site is for example in Dutch, and there is no translation available for the original string 'Post new comment', it should be written with the language attribute. Something like
Note that best practice for accessibility is off course to translate all strings.
Comment #3
gábor hojtsyThe fundamental problem with trying to implement this is that when t() or format_plural() is invoked, we don't know if HTML is generated. We cannot just output HTML wrapped text if what's generated is for an email or an XML format like RSS. We don't have that information, so we'd risk breaking all emails and RSS feeds generated by the site if we'd do. The localization client module has the same issue over at #218021: Make it possible to translate by clicking on elements.
Comment #4
hanno commentedHmm, that's a fundamental problem indeed. The only (somewhat radical) solution to implement this is to add a parameter to t()?
Comment #5
hanno commentedHmmm, a fundamental problem indeed. The only, somewhat radical, solution for this is adding a parameter to t()?
Comment #6
gábor hojtsyYes, to implement this, we'd either need to return a structure from t() instead of a string, so people can use just the string or the whole markup or alternatively we could pass in some information to t() that adding markup is ok (or rather that it is not ok, since that is less common).
Comment #7
gábor hojtsyConsider this as well:
Now which of the four t()'s would be safe to return something like:
<span class="untranslated" lang="en">....</span>To me it seems like only the first. The other three are option values, that are escaped for inclusion in the select box, so the select box would literally include the span tag. It seems to me like although we can add an extra argument to t(), this is not something I'd consider easy developer experience as they need to track how the strings are used in obscure places like this...
Well, not nice. I don't really have better ideas, since as you can see the kind of ways we use the output of t() can be very different from line to line.
Comment #8
gábor hojtsyYou can try this for yourself easily. Just apply this simple patch and see how your Drupal site looks:
Comment #9
mgiffordOk, so it would be adding an $option to the array passed to t():
t($string, array $args = array(), array $options = array())
Currently this supports the following elements:
- 'langcode' (defaults to the current language): The language code to translate to a language other than what is used to display the page.
- 'context' (defaults to the empty context): The context the source string belongs to.
The best case described so far is to add a 'nomarkup' element to this which would check to see that no SPAN tags have been added or run the output through PHP's strip_tags() to yank out the HTML.
Comment #10
gábor hojtsyWell, while that sounds technically true I doubt this would generally be accepted as a trade-off. It puts lots of burden on the developer to figure out where the output of t() will be used eventually. Sometimes it is pretty impossible to tell if you are in a generic API function.
Comment #11
mgiffordIs there a way that this could be perhaps handled by a contrib module? I'm just trying to see if there is any way to address this.
Comment #12
gábor hojtsy@mgifford: I don't think there is a contrib way. I'd love to be able to solve this issue, and mark all separate language items proper on the page but we need to consider the developer experience closely. Let's consider you have an API function somewhere like this:
Since we don't know whether this data is going to be used in a form item (escaped), text email (looks ugly with markup) or straight on a webpage (would be ok with markup), we don't know if that t() is allowed to add markup or not. It is really an API responsibility question. We should not spice up all of our API functions with arguments to pass to t() for markup, so I can tell this function that the output should or should not contain markup, right?
I don't really see a good way to do this, even if we add a nomarkup option to t() which I think people would be freaked out about, that would still not give us the tools we need to solve this, since often we don't even know what to pass in that option.
I do agree it would be great to solve this, but I'm at a complete loss of ideas. If I'd have had an idea in the past four years (since the issue at #218021: Make it possible to translate by clicking on elements was submitted), I'd have done it for my l10n_client contrib module honestly. It would be a very powerful thing.
Comment #13
hanno commented@Gabor thanks for all this testing. There is indeed no easy solution. In the long term, we could probably work with html texts by default?
Mark this as postponed for now?
Comment #14
hanno commentedI have an idea. It is a kind of a dirty workaround, maybe more for #218021: Make it possible to translate by clicking on elements:
If untranslated, return the text enclosed with single quotation marks (‘’). So, if a text is untranslated you will get
‘Post new comment’instead ofPost new comment.We can then do a find a replace in html to substitute ‘ and ’ with special tags.
Comment #15
mgiffordInteresting option.. Could possibly play into modules like http://drupal.org/project/l10n_client
Comment #16
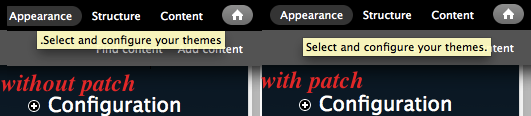
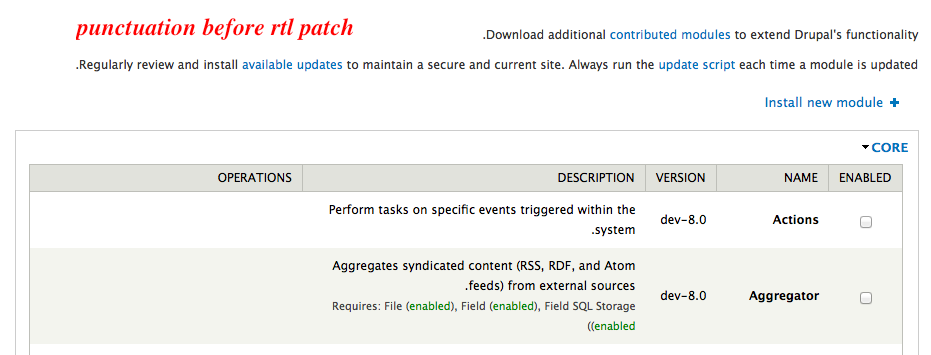
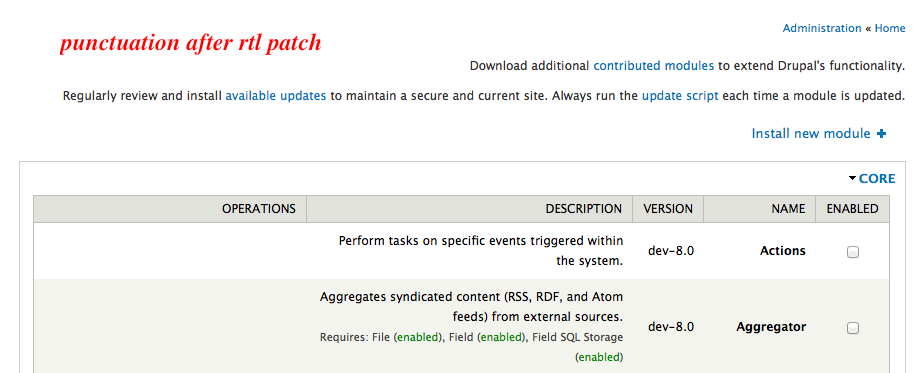
hanno commentedChanging title: while testing, found out that this issue is also relevant for RTL based websites. As there is no LTR attribute, Drupal prints the text with the punctuations (.!?()) in the wrong direction. Maybe minor issue, but good to take note.

Comment #17
gábor hojtsyWell, the punctuation would need to be there if the text is RTL, which is what the markup tells the browser. I agree it would be good to have these wrappers to mark up RTL/LTR differences too, that unfortunately does not get us any closer to a solution :|
Comment #18
mgiffordAs discussed at A11ySprint. So much of the world doesn't use Drupal in English.
Comment #19
gábor hojtsyAny good ideas?
Comment #20
mgiffordGuess we need to write up an issue to help assess whether or not it's returning HTML or not. Alternatively, do some tag sniffing as part of processing the string.
Comment #22
hanno commentedThis issue kept me thinking. As we can't differentiate between html, plain and xml output, I went looking for a solution to add an invisible symbol in the text that we could replace while rendering.
The good news is that unicode has special invisible characters for text direction information: http://www.w3.org/International/questions/qa-bidi-unicode-controls
I did a test in Drupal, and using this invisible characters, fixes the right-to-left punctuation problem of untranslated strings. Attached the patch.
- I used json_decode to add the special characters, probably there is a better method, but I couldn't find it).
- We could alternatively use the code U+202D to start LTR. Didn't test that code.
Comment #23
hanno commentedComment #25
Everett Zufelt commentedI think the problem is when should this markup be added (if required?
Perhaps an API function should return untranslated, but translatable, strings, and then at the point that these strings are being output, or added to a render array, they should be translated. This would require separation of translation into two calls. This is more easily understood, but still a extra burden on developers.
// Indicate a string is translatable.
translatable('Disabled');
// Translate a string.
translate($string);
Edit: Perhaps the second function could mean translatable and translate. The first function would declare a string translatable only, the second would declare a string translatable and perform the translation, so that literals can still be used and simple strings need only be passed into one function before output.
Obviously the function names used are for demonstration. In this case API functions would declare a string to be translatable, but the t() function could be used to translate non literal strings.
Another problem, which is exposed by Gábor above, is the need to set the lang and dir on specific render elements
$element['#lang'] = 'en';
$element['#dir' = 'ltr';
What if all fields on my form are in english, except one? Or, a more complicated case:
$element['#type'] = 'radios';
$element['#options'] = array(
array(0, 'English', array('#lang' => 'en', '#dir' => 'ltr')),
array(1, 'French', array('#lang' => 'fr', '#dir' => 'ltr')),
);
Comment #26
mgiffordGreat to see progress. Would be so neat if this patch could be brought in to address this on a more basic level.
@Hanno, you've added directionality via unicode, but not the language definition. I was quite hopeful to see this example here where they equated:
<Q lang="he" dir="rtl">...a Hebrew quotation...</Q>and
‫״...a Hebrew quotation...״‬Unfortunately I couldn't find a way to do that in English.
Having the untranslated string display in left to right I think would be an improvement for sighted users.
Ultimately we need to insert LTR & English around strings that haven't been translated. The unicode solution also won't work for XML I don't think.
Think we might have to go back to API function changes as per @Everett's note above.
Comment #27
hanno commented@Everett Well, there are different directions for a solution
1. Handle every untranslated string as an error. Especially for anonymous users, every string should be translated. So post an error message in the watchdog table that a translation string could not be found (similar as file not found).
2. Make a smarter t()-function, that can accept html=true/false and/or that return an array (translated yes/no, plain/html, language)
3. add invisible information to the untranslated string and replace that while html rendering with language code
Ad 1: Not that sure if every administrator is happy with that
Ad 2: this is proposed by Mike in #9, Gabors answered in #10 that this is hard or impossible to tell for module developers. I prefer this solution as well, but this needs patches and testing in core, and I doubt this can make it for Drupal 8
Ad 3: using unicode could be a solution that can eventually work, that doesn't break anything. Important issue is whether it is possible to replace unicode by 'lang=' and 'dir=' for html-rendering.
@Mike unicode text direction is possible in XML, but not preferred. It depends on the receiver if this is used or ignored and if markup is preferred.
Comment #28
hanno commented@Mike, There are indeed language tags in unicode, but they are depreciated. So, I suppose no browser and text-to-speech-software will handle this unicode characters. However, we could probably investigate if it is possible to use this unicode character as an helper and replace it for real language tags during rendering?
The English language tag in Unicode characters would be:
U+E0001, U+E0065, U+E006EEnd the end tag would be:
U+E007FDuring html rendering we could replace them with lang="en". Can we do this DOM manipulation at the end of building a page?
For detailed reading about the language tag: The Unicode Standard - Chaper 16 (p565)
Comment #29
mgiffordThanks @Hanno for your persistence on this issue. Language of parts is an important part of WCAG 2.0AA and one that isn't well supported anywhere.
http://www.w3.org/WAI/WCAG20/quickref/#qr-meaning-other-lang-id
It's too bad that the language tags in unicode have been depreciated. But yes, it's unlikely that AT will support it if they don't already..
Interesting the option of inserting the depreciated unicode and then swapping it with JS. It shouldn't cause a problem I would assume.
I like the idea of handling every untranslated string by an anonymous users as an error. I think that many sites would see it this way anyways.
I do wonder what the performance implications might be for any of these solutions.
Comment #30
hanno commentedWell, included a patch that, besides the official direction characters, also adds the depreciated language unicode characters. These characters can optionally get rendered in the right places to html attributes lang and dir. For sure by javascript, but probable also somewhere around Drupal_render.
The str_replace below works in a theme:
Three questions about this solution:
- Is this a valid solution?
- Is json encode the preferred way to include these unicode characters?
- Is there a way to manipulate the html dom, or do a smart replace somewhere before output, to add the lang attribute?
Comment #32
mgiffordadding tags.
Comment #33
gábor hojtsyWhy are you using json wrappers when the same chars can be represented in PHP strings just as well (and in much less CPU time :)? Also, are you envisioning all strings in themes be wrapped in this decoding code? How do you think this could be feasible to implement?
Comment #34
hanno commentedI tried to add these unicode characters directly with an escape code, but couldn't get it to work in php and followed this advice: http://stackoverflow.com/questions/6058394/unicode-character-in-php-string Would also prefer to have the characters there directly. Also tried to copy paste them directly, but that didn't work either. Using the htmlencoded variant worked, but had the problem that on several places this code was printed.
The str_replace in a theme is indeed not a workable solution, i added it as a proof of concept to see if the conversion was possible. I am hoping for a way we can do a general find and replace in the DOM-structure or when rendering HTML, somewhere added in a general theme output function. Is there a place where we can loop through the Drupal html output?
Comment #35
hanno commentedI tried to add these unicode characters directly with an escape code, but couldn't get it to work in php and followed this advice: http://stackoverflow.com/questions/6058394/unicode-character-in-php-string Would also prefer to have the characters there directly. Also tried to copy paste them directly, but that didn't work either. Using the htmlencoded variant worked, but had the problem that on several places this code was printed.
The str_replace in a theme is indeed not a workable solution, i added it as a proof of concept to see if the conversion was possible. I am hoping for a way we can do a general find and replace in the DOM-structure or when rendering HTML, somewhere added in a general theme output function. Is there a place where we can loop through the Drupal html output?
Comment #36
panchoAwesome that you're making some progress!
This is at least a task, so the feature freeze shouldn't stop you IMHO.
Comment #37
hanno commented@Pancho @Gabor, is it an idea to add a hook here for untranslated strings?
Or should we include the unicode characters and work on a conversion later?
If we have a hook for untranslated strings, we can create contributed modules for different solutions:
- to help the translation client module with inline translations
- to add a language negotiation fallback mechanism for t strings.
- to write errors to the log when a string appears untranslated
- to add unicode and rewrite the dom by javascript
Comment #38
hanno commentedPatch with the unicode characters directly encoded in valid utf-8 format.
Tested and resolves the direction issue for RTL languages.
Comment #40
mgiffordI had some problems applying the patch so just refreshed it.
In looking at the code though I want to confirm that from the source perspective like:
Actually, it seems I can't paste in the code here as the first character after the
title="It seems that this is being stripped out along with everything following it by the filters we're using.
Comment #42
hanno commentedThanks for this refreshed patch. Don't understand why it fails on the tests. Any clue?
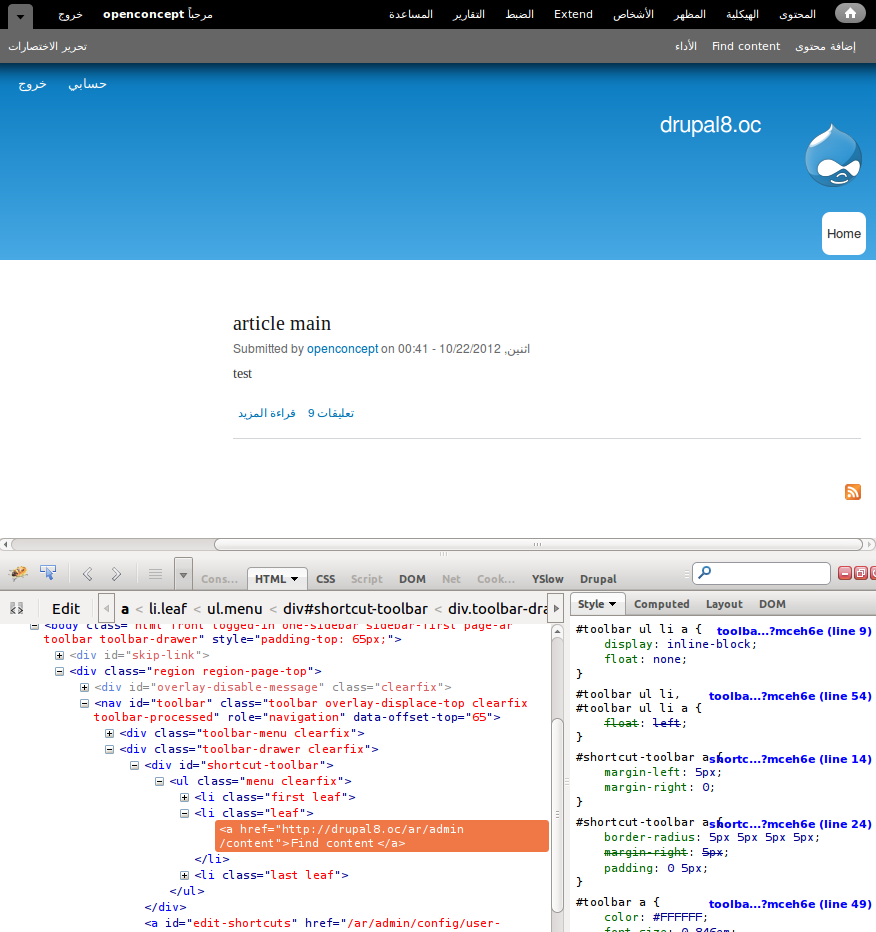
Here a screenshot of the title attribute. These characters aren't printed by webbrowsers, but they are send to the browser and not filtered by Drupal functions as check_plain afaik. Attached a screenshot of the title attribute of the menu correct with and incorrect without this patch (rtl language chosen, without translated strings).
Comment #43
hanno commentedProbably the tests fails due to SimpleXML parsing and these unicode characters?.
Comment #44
mgiffordI think the problem comes because the tests are looking for absolute strings, but the strings are different. Your patch appends characters which we can't see but that are there. I think the tests just need to be modified to allow for
"\xF3\xA0\x80\x81\xF3\xA0\x81\xA5\xF3\xA0\x81\xAE\xE2\x80\xAA" . $string . "\xE2\x80\xAC\xF3\xA0\x81\xBF"as right now it's looking for$stringin most cases.It's a brilliant approach I think. It's only going to be wrapped around untranslated strings when in another language so for most sites it isn't something anyone is going to know about.
It will make some things harder to troubleshoot, but really like the approach you've developed here.
Comment #45
mgiffordEDIT: There was a duplicate.
But thought I'd add here that I do believe that non-English sites seeking to meet WCAG 2.0 AA will need this. Will be useful to not have to hack core to be able to implement this. Not sure if there's any way to do this.
Comment #46
yesct commentedIs the next step here still:
more discussion to settle on an implementation?
Is there anyone we can ping that has not had a look at this yet that might be interested or have some expertise?
Comment #47
mgifford#40: no-translation-1165476-40.patch queued for re-testing.
Comment #48
mgiffordPartly I think it's a matter of getting the patch to pass the bot. I've just re-queued it so perhaps it will work.
There are also open concerns by Gábor Hojtsy that haven't been addressed. Updating the issue with a summary of the concerns and responses would be useful.
Comment #50
mgiffordComment #51
hanno commentedNot sure why this isn't working, is it the unicode characters that doesn't parse through the testbot? If so, does that probably mean this is too experimental to implement?
If we can't find the reason before the code freeze we can instead create a hook on the t-function. We could use that hook for a contrib module.
Comment #52
mgiffordI like that approach. Would probably be easier to get into core anyways. Any thoughts on how you're do that?
Comment #53
hanno commentedWell, same as the hook with the issue for the date_formats to support other calendars:
#1178342: Allow contributed modules to alter the format_date() function result.
so, patch needed. Contributors could also use that hook to look up a word in another preferred fall back language when it's not available in the requested language.
Comment #54
hanno commentedI researched why the patch failed.
It happens because the testbot fails to write to the simpletest table in the 'message' colom. (General error: 1366 Incorrect string value: '\xF3\xA0\x80\x81\xF3\xA0...' )
It fails because the supplied utf8 characters for the language change are four bytes. Mysql doesn't support the 4 byte section of utf8. As this is also an issue for other characters, this is all explained in this issue #1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols)
The solution for the language change in unicode can't be implemented before that issue is solved.
Comment #55
panchoSo postponing on #1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols)
Comment #56
panchoAlso recategorizing as a bug. The screenshots in #16 should be pretty convincing.
Even in a fully RTL translated scenario, it's practically impossible not to have a few untranslated strings left, if it is desired at all.
Comment #57
panchoNot sure if this really needed to be postponed.
The question ist: How far can we get without using the 4-byte characters?
It might be worth getting that part fixed and do a followup, whenever #1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols) lands, which is quite unclear atm.
Comment #58
heine commentedUnicode control characters are forbidden in phrasing content per the HTML 5 candidate:
Comment #59
hanno commentedThat's bad news. In an W3C article about bidi and html5 it seemed possible (http://www.w3.org/International/articles/inline-bidi-markup/#nomarkup):
Comment #60
heine commentedThe "control characters" are used somewhat ambiguously in normal speach, but the spec perhaps refers just to the "Control Codes". The Unicode glossary defines those as in the ranges U+0000..U+001F and U+007F..U+009F, which would make this approach at least non-forbidden.
Comment #61
hanno commented@Heine it's indeed really ambiguous mentioned in the W3C document, so a good catch, and in contrast with for example http://www.w3.org/International/docs/bp-html-bidi/ Probably these draft documents need some improvement as these chracters seems ok.
Comment #62
hanno commentedOk, here the patch that should solve the bug shown on #16.
- It adds the unicode characters for LTR and dir pop.
- unicode chracters as a const
- Added complexity to give untranslated plural strings properly LTR and dir pop
- Changed the test for plural strings as this test expects an untranslated string
Comment #64
hanno commentedComment #65
hanno commentedComment #66.0
(not verified) commentedAdding quick summary of the main roadblock from Gabor.
Comment #67
mgiffordNice to see progress in #1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols)
Comment #68
matsbla commentedStrings can fallback to other languages than English, e.g. Arabic (Egypt) can fallback to Arabic, thus it should have lang="ar" & dir="rtl" (so the writing direction need to respect the writing direction of the string language used)
Comment #69
hanno commented@matsbla, thanks to bring this to our attention. Now we have language fallback in t(), the writing direction and language attribute becomes even more important to meet wcag.
This issue hangs still on the 4-byte issue for the language code, but for writing direction it is already doable with the special unicode characters.
Comment #70
hanno commentedI think it's better to split rtl in a separate issue as that one is easier to fix as the language code.
#2336491: if t() string has fallback language in another text direction, bidi should be added
Comment #71
hanno commentedComment #72
hanno commentedComment #73
mgiffordComment #74
gábor hojtsyAmsterdam2014 is the master sprint tag for AMS :)
Comment #75
hanno commentedShouldn't we first focus in Amsterdam on #2336491: if t() string has fallback language in another text direction, bidi should be added, as that is much easier to implement? If that works, we can work with the same solution on language tags.
Comment #76
yesct commentedComment #77
hanno commented#1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols) has been fixed, so with latest version it should be possible to use 4 byte language characters in Drupal.
Comment #78
mgifford@Hanno, can you re-roll your patch in #64? It would be great if this could be brought into D8.
Comment #79
hanno commentedYes, back in time :) patch #64 was for bidi only, #34 involved the language changes.
Comment #80
mgiffordI'd like to get this in but might need to wait to 8.1.
Comment #81
mgiffordComment #84
mgiffordThat should be Needs Work. Hanno's patch is from 4 years ago...
Comment #97
dwwThis came up as a random triage target for the #bugsmash initiative. Seems like this is still a bug, and it's still a tricky problem. At the bare minimum, we need to re-roll this for modern core (probably target 10.1.x for now, worry about backports later). I haven't exhaustively read the whole history in here to know if there's more needed (although I also see it's tagged for "Needs tests" and the existing test coverage in here is both very spares (only changes 2 lines) and is changing existing coverage, not adding new coverage.
Comment #98
penyaskitoRead all comments. I was concerned too about what Gábor described in the first 12 comments, as t() misses the context for when something is rendered in html (and where) or other formats. But maybe now with delayed translation with TranslatableMarkup is worth a revisit. Still think this would be a DX issue and a big change only doable in a major release.
For the current attached patch, looks like that covers only what is described in #2336491: if t() string has fallback language in another text direction, bidi should be added, so probably that should be moved there.
Comment #99
penyaskitoAlso a concern: #1314214: MySQL driver does not support full UTF-8 (emojis, asian symbols, mathematical symbols) was closed, but not sure about the rest of engines we support (core and contrib).
Comment #100
penyaskitoAfter discussion in Slack with @dww and @Gábor Hojtsy, looks like there's agreement that this is a legitimate and important request, but cannot be realistically fixed unless a major re-architecture haul happens.