Spun off from #1447686: Allow importing and synchronizing configuration when files are updated. Come up with two or three standard workflows for deployment and sync of configuration, and ensure that the system actually meets those needs, with a focus on how config is gotten out of the sites in question.
Workflows
User has a single site installed via a one-click installer at a shared host.
- This user will not have any interaction with the configuration system. Even if they want to move to a new host, they will have a to take a database dump and this alone will serve their needs.
User with a live website and a local development environment, using ftp to transfer code (no version control)
- Developer iterates on their local environment.
- When a set of changes is ready for deployment, files are uploaded to prod server's config directory. This directory may have a different hash than the local environment, but it will still start with 'config_'.
- UI is used to import them.
Small team using version control as a deployment mechanism.
- When work is started, settings.php is configured so that all environments are using an identically named config directory.
- Developers work with a checkout of the current production config on their local machines.
- Developers can then iterate on their site and its config files with $VCS, and share changes between other devs in normal $VCS ways.
- When a set of changes is ready for deployment, prod server's config directory is $VCS updated.
- Drush import-all-the-things.
Possible solutions
1) Explicitly import/export configuration files
This is the system as it stands now. There has been feedback that this is confusing (users will expect their config files to always be present without explicitly exporting them) and it breaks some assumptions we have in CMI, like that missing files indicate deletion of configuration. Feedback and discussion around the present UI can be read at #1697256: Create a UI for importing new configuration.
2) Writethrough configuration to files as it is saved
Makes more sense to end users and is more intuitive, can cause race condition problems when configuration is deployed because config being changed on the live site will overwrite config changes that have been deployed. It has been suggested that this could be controlled with a setting that indicates whether writethrough should be on by default or not (with a default of on.) This would require a little knowledge of how the system works to configure sites with more complicated deployment needs.
3) Writethrough changes to a separate directory
The same as above, but writethrough is written to an 'export' directory. When deployed to another server, it is deployed to an 'import' directory where it is imported. This avoids the race condition issues described above, however it also makes vcs-based deployment somewhat more complicated. You would want to setup every site instance (dev, stage, prod, whatever_other_instance) declaring in its settings.php in which directory it writes, and from which directory it imports - only as defaults, with the UI and drush commands for explicit import / export letting you pick a different one amongst the folders present under files/config_xxx.
E.g :
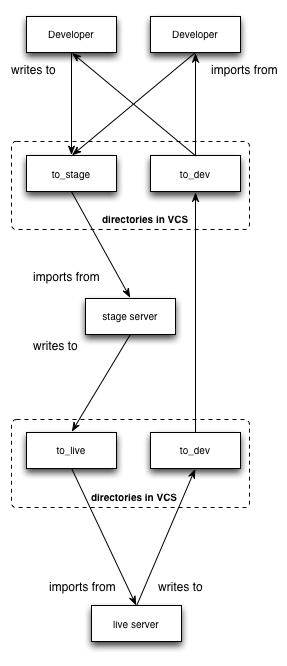
'prod' writes to /prod and imports from /stage
'stage' writes to /stage and imports from /dev_shared
'dev writes to /dev_local and imports from /dev_shared
/dev_shared, /stage and /prod are all pushed in VCS, changes made in local dev environments are made by diffing / merging changes from /dev_local to /dev_shared and committing.
There are some more details and a potential workflow diagram at http://drupal.org/node/1703168#comment-6344116
Related
#1831818: Document git config import workflow


{kind=link}
{kind=link}
{kind=link}
Comments
Comment #0.0
gddUpdated issue summary.
Comment #1
sunPlease note the elaborate analysis about "re-enabling write-through" and its compatibility with concurrent proposals in #1626584-83: Combine configuration system changes to verify they are compatible (and following)
Comment #2
Anonymous (not verified) commentedsmall team using $VCS
- developers work with a checkout of the current production config on their local machines
- developers work with a setting in CMI that writes changes to their development site config directly to the folder with current prod config
- developers can then iterate on their site with $VCS, and share changes between other devs in normal $VCS ways
- when a set of changes is ready for deployment, prod server's import directory is $VCS updated, and drush import-all-the-things
assumptions
- config system has the ability to write-through changes to an arbitrary directory
- config system can import changes from an arbitrary directory
- config system can export current config tree to a directory / tar ball
User with a live website and a local development environment, using ftp to transfer code (no version control)
- development environment setup with write-through to folder with current prod config, which is downloaded from the prod site
- developer iterates on dev env
- when a set of changes is ready for deployment, files are uploaded to prod server's import directory, then UI used to clicky-clicky import them
Comment #2.0
Anonymous (not verified) commentedUpdated issue summary.
Comment #2.1
gddUpdated issue summary
Comment #2.2
gddUpdate issue summary
Comment #2.3
gddUpdated issue summary.
Comment #2.4
gddUpdated issue summary.
Comment #2.5
gddUpdated issue summary.
Comment #2.6
gddUpdated issue summary.
Comment #3
gddI've taken beejeebus' comments, fleshed them out, and added some potential solutions in the issue summary. If people want to add more potential solutions, please put them in the issue summary.
Personally, I have always wanted option 2 - Writethrough is on by default, and on production sites you turn it off.
For workflow 2, this would 'just work' and would be a very natural process.
For workflow 3, this would probably work in conjunction with #1515312: Add snapshots of last loaded config for tracking whether config has changed so that users can tell when the production environment has been overridden. We would also still offer an explicit export option so that you can get your config when writethrough is turned off. So I guess in actuality, workflow 3 would involve option 1 for the production site and option 2 for the dev sites.
I don't think that solution 3 is realistic because of the difficulties in vcs-based deployment.
If we went this route, we would need to resolve removing the StorageDispatcher, writing the multi-server storage component, and adding support for optional writethrough in the UI. Sorry I'm about to get on a plane so I can't dig those issues up right now.
Comment #4
yched commentedRe-stating what I wrote in #1447686-179: Allow importing and synchronizing configuration when files are updated :
Solution 3) ("writethrough changes to a separate directory") seems doable if every site instance (dev, stage, prod, whatever_other_instance) can declare in its settings.php in which directory it writes, and from which directory it imports - only as defaults, with the UI and drush commands for explicit import / export letting you pick a different one amongst the folders present under files/config_xxx.
E.g :
'prod' writes to /prod and imports from /stage
'stage' writes to /stage and imports from /dev_shared
'dev writes to /dev_local and imports from /dev_shared
/dev_shared, /stage and /prod are all pushed in VCS, changes made in local dev environments are made by diffing / merging changes from /dev_local to /dev_shared and committing.
Comment #5
Anonymous (not verified) commented"Personally, I have always wanted option 2 - Writethrough is on by default, and on production sites you turn it off."
imo, that exemplifies the wtf way we treat files in this system ("files are canonical. except when they're not, lolz").
but, i can live with it, and i think i'm the person who has most insisted writethrough is completely stupid, so maybe it's time i moved on. turning writethrough off on prod systems eliminates any of the issues re. races etc, and i can continue to ignore people who still want to insist files are canonical.
so, lets put the writethrough question to bed, and just make it a toggle.
Comment #5.0
Anonymous (not verified) commentedUpdated issue summary.
Comment #6
gddI've added yched's suggestions to the issue summary.
As far as the canonicality of files, merlin pointed out over the weekend that it is almost impossible to make files truly canonical as long as we have a layer in between that acts as anything more than a cache, which the active store does. For instance, it will verify the data it is importing before saving it which no caching layer ever does. However the active store is never truly canonical either, right now it can be overridden by $conf, and in the future it will be overridden by the context layer proposed by Jose. In the past I have always said that I files are canonical, but honestly the reality is we have nothing that is 'truly' canonical.
So basically, while admitting that, I'd also like to retain the functionality of an easy-to-use system that makes deployment as simple and intuitive as possible while still allowing more advanced use-cases. yched's suggestion above does this, but it also is a bit more complicated to setup. However I like it better than option 1 because it still maintains the writethrough which I continue to believe is the best way to handle this.
Comment #7
Anonymous (not verified) commentededit - removed snarky off topic comment.
Comment #8
sunI've added a CachedFileStorage controller; using files as canonical storage and another "active store" as cache in
#1626584-92: Combine configuration system changes to verify they are compatible
Comment #9
swentel commentedNot sure if it's related for this discussion: the possibility to lock a configuration, although this can be solved in a way if yched's scenario is possible. Where it might help:
I'll try to think about some more things and some possible use cases whether this might be interesting or not. This feature could easily live in contrib I guess.
Comment #10
gdd@swentel I think that is separate from this question, but I added a new issue to discuss it. #1714396: Offer ability to 'lock' config changes I always wanted this feature anyways so thanks for the reminder.
Comment #11
xen commentedI'll add in another possibility:
Some contrib module/drush command interfaces with the configuration system and does all the hard thinking.
Then workflows like "local and live communicate directly" is possible, as demonstrated in https://github.com/xendk/cim , or whatever people might think up in the future.
All that's really needed for that mode of operation is that the config system doesn't make odd assumptions per default, and allows for getting and setting the configuration programatically, just as it does now.
Comment #12
gddYes, while this is not something we're going to be supporting by default in core, I don't think we're doing anything that blocks it right now (and we shouldn't)
Comment #13
sunSo... based on this thread...
FWIW, I added a CacheStorage to leverage the existing Cache subsystem as cache for the FileStorage in:
#1626584-94: Combine configuration system changes to verify they are compatible
(which means that the
{config}database table is not used at all with that)I've to say, this immediately made a lot of sense. Apparently this design, of using files as canonical storage and (optionally) the database (or any other key/value store) as a cache for performance reasons, is used by many other applications in the wild. I like it.
I'm also very positively impressed by our new architectural design (#1605324: Configuration system cleanup and rearchitecture), which essentially allows anyone to implement new storage controllers for the config system to achieve a completely different behavior, without having to touch or hack anything else in the system. :)
However. The idea of doing this particular idea of a canonical file store + cache completely breaks the assumptions of the import/export mechanism. That is, because the "active store" is the file system already, whereas the import/export mechanism assumes that it is not but rather a "passive store" that's essentially supposed to hold the last exported "snapshot" and/or new/updated configuration that is supposed to get imported.
This could be remedied by using a different directory for importing/exporting configuration. However, as we already discussed here, doing so would inherently break the idea of this workflow:
This doesn't work anymore, because the moment you pull the new config into your staging/production site, it is immediately in the active store and thus the actively used configuration — which will break tons of things, because especially dynamic/configurable thingies (like image styles, node types, fields, etc) have to be imported, so the system is able to update and create dependent things like database tables and so on...
Anyway, at least for me, that would be the most common and expected workflow with regard to exporting/importing/staging configuration.
The idea of a canonical file storage + cache sounds very appealing to me, especially after testing and seeing it in action. But honestly, I have no idea how we could resolve the export/import/staging problem... :-/
At least the ideas that have been suggested so far (e.g., using a separate directory for export/import) do not make much sense to me, since that would technically result in duplicate versioned data, which essentially are snapshots (tags in git-speak) of the actual, canonical config. Furthermore, you'd have to explicitly add the actual canonical config directory to your
.gitignorefile, so as to ensure it won't end up in the repo and won't be staged to anywhere else.OTOH, of course, we could as well punt on that problem entirely and just simply say:
At least, that stance would limit the remaining problem space to figuring out how we could retain a snapshot/backup of the "last known" config - which the import mechanism requires in order to determine whether a config object is new, updated, or has been deleted.
What do you think? :)
Comment #14
gddThere is already an issue for this discussion at #1515312: Add snapshots of last loaded config for tracking whether config has changed. Merlin has also told me he considers this critical to Views in core.
I also always assumed we would put sites into maintenance mode during import, I'm not sure how we avoid it and it should be fine if we can keep imports to a minimum amount of time.
Talked about this some in IRC today with sun, merlinofchaos, chx, and beejeebus. One of the things I have always valued about the active store is that it is more than a cache, it is known-good data. If we attempt to import a malformed YAML file, the parser breaks and the active store is safe. If we attempt to import a malformed view (where the YAML is good but some code makes it an invalid data structure for views) then a validate procedure nukes it before it is written. I would like to keep that in any future iterations of the system (and which is gone in the CacheStorage implementation above.)
That said one thing I love about the StorageCache idea is that it removes the database from the equation entirely, meaning we can access config at any bootstrap level. +1000 to that.EDIT: No the StorageCache still uses the db as implemented above, nevermind.Sun is right about the import problems outlined above. I don't see how we solve them without a separate import directory. We could in theory have a system like
import dir -> config files -> cache for reads
An advantage here is that the files truly become canonical which is not true in the current system. In the current system the active store is canonical because it is known good, the files could be garbage theoretically and the system still works (as long as it installed properly at least once.)
I might try and put together some graffles of these scenarios along with the pain points and gotchas in each, because I know it gets hard to follow why things do and don't work.
Comment #15
sunFurther discussion on this issue and in particular #13 triggered a rather radical idea. Let me explain:
Problem
Goal
Details
The essential underlying problem space is that any kind of import mechanism requires two representations of the same data in order to calculate differences.
By separating the currently and actively used configuration data from a second set of configuration data, we are able to determine the differences between them. In essence, the second, "exported" data is a snapshot of the active configuration data, at a certain point in time.
This snapshot is local to a particular site. It is not necessarily the latest, current, active configuration. As such, the snapshot is rather the last known state of the configuration data.
Proposed solution
Tagline: Reverse it. Make active actual. Turn state into local state. KISS.
(
FileStorage)(
CachedFileStorage = CacheStorage + FileStorage)Notes
- #1671080: Remove StorageDispatcher to simplify configuration system
- No issue yet: Fix to handle uninstallation of module config correctly.
Comment #16
sunComment #18
dries commentedCommitted #1671080: Remove StorageDispatcher to simplify configuration system on which this patch was blocked on.
Comment #19
gddI don't see how this solves some of our fundamental workflow problems though. Can you elaborate on that? It seems to we, with this proposal, we are still going to need a second area to stage from to prevent race conditions on import.
Comment #20
damien tournoud commentedIn most cases, you *cannot* change the configuration under the feet of the system running without bad consequences. Configuration is not something static... if the system went from configuration A to configuration B, the last state is as much important as the way you got to it. In other words, we should stage configuration *changes*, not configuration states.
The typical example of that is changing data model (entities or fields) or database schema: the changes themselves have impact on the data that the initial and final states cannot fully capture. Two typical examples:
varchar(16)tointthen tovarchar(32); this is not the same as changing a column fromvarchar(16)tovarchar(32)Staging configuration changes instead of full configuration would allow all the side effects of the configuration changes to applies orderly (but it does result in one interesting challenge in how to deal with cascading effects of a configuration change during the replay).
Comment #21
yched commented@damien : the 1st case would typically be addressed in current CMI by having $field hold a uuid -> delete + recreate <> update
Comment #22
damien tournoud commentedThose were just two textbook examples. Any moderately complex will have a lot of side effects triggered by configuration changes. It is critical to respect the order of those side effects.
Comment #23
yched commentedRe @sun #15 :
I'm confused after reading the propsed patch.
"import" operation reads from 'state', which is a db table ? So, er, you need to push a db dump to bring some config over to a site ?
Comment #24
sunHere's another summary — I suggest we discuss this topic in our CMI conf call on Monday (and also at DrupalCon, of course):
Frankly, I'm no longer sure what I did there. For some reason it worked in manual testing, and even passed the config import tests, but I agree it doesn't really make sense.
@Damien makes an excellent point. The actual storage does not matter at all for the topic of staging. (You can "stage" the {variable} database table in D7 already and wrongly believe that you solved the configuration staging problem...)
At the same time, he basically suggests to ditch the two-snapshots-diff approach and implement a record-replay mechanism instead, so as to be able to properly account for intermediary configuration change steps in between.
The record-replay approach would basically be the only way to properly replay configuration changes (in particular targeting configurable thingies, such as fields). That is, unless we'd enforce any module/API that may have such changes to implement and perform a fully-fledged delete + prune + recreate workflow like Field API does — which I do not see as very practical (since that's a shittone of code, which cannot be easily generalized/abstracted for other use-cases).
Quite interesting tidbit: If we'd be able to rely on a VCS, then we'd get the entire record-replay functionality for free. E.g., a
GitStoragecontroller automatically commits every configuration change that is saved. "Importing" configuration would then mean to read the git log starting from the last known git commit/hash, and replaying those changes in the new/other environment...OTOH, there seems to be a quite heavy difference in requirements for essentially three "types" of configuration objects:
Static, simple configuration (settings).
No module/API callbacks involved. No special import/staging mechanism required, since no dependent hooks/callbacks/functions are invoked. These settings are just simply written to the new environment and immediately take effect after import. (Technically, they wouldn't even need an import/staging mechanism.)
Example:
system.site.ymlDynamic Configurable Thingies™.
I.e., 0-N incarnations of configuration objects that follow a certain schema/class/interface. Involving module/API callbacks in the import mechanism. However, intermediary changes are irrelevant — the plain before/after snapshot diff is entirely sufficient to properly perform/"replay" the configuration changes and perform the required actions to update other parts of the system (as well as other configuration) accordingly.
Example:
image.style.thumbnail.ymlExample:
node.type.article.ymlStorage-Altering Advanced Dynamic Configurable Thingies™.
Essentially the same as the previous type, but with additional, nasty dependencies and actions being performed on certain configuration changes; e.g., creation/deletion of database tables, database table schema changes, etc. (The essential difference seems to be the entity/field storage/schema-futzing.)
Example:
field.instance.body.ymlThe advanced record-replay staging mechanism is technically only required for the last type. But as @Damien pointed out, for this type, it is pretty much essential to track and know the intermediate changes.
One interesting conclusion of this is that the actual storage for configuration doesn't really matter. I'd therefore love to at least move forward with the
CachedFileStorageas proposed in #15 (without the "state" part), since having the actual/current configuration in the filesystem turned out to make incredibly more sense.Unless someone disagrees, that could potentially be done in a separate issue, so we can keep on focusing on the staging problem space in this issue. (Though we'd still have to resolve the problem of finding a "new" space for the config that is to be imported.)
Comment #25
david strauss@Damien
I've long supported a "declarative with hinting" model for solving this issue where configuration changes, say, the name of a field.
In the case of a field rename, the "hint" in the configuration would be an array of former names. This would allow matching the new name with the old. Once such a configuration is deployed everywhere, the hints are disposable, though that would be a manual process. It's like a tombstone record in a distributed database. I agree that solving this case is essential because of data loss risk.
In the case where a field gets deleted and then recreated with the same name, I'm okay with the system either attempting to migrate the existing data or, if that fails, throwing an error and requiring a purge of the field's data to continue. This isn't an extremely common case in site building, and the failure case isn't dangerous. It's also possible to identify this case with "hint" style data like the creation time stamp on a field, though we'd have to warn the user if the system even *thinks* it needs to purge a field's data.
Finally, if a subsystem needs guaranteed tracking of deletions, creations, and renames, it's always welcome to use UUIDs. UUIDs can co-exist with machine names in a subsystem if necessary.
A declarative model is nearly essential to supporting a branch-based development workflow for site-building unless you're proposing a scheme that either (1) has no facility to handle changes in any way that isn't a git-style fast-forward with changes cleanly stacked, or (2) approximates DARCS-style theory of patches/SQL-style transaction serialization -- and then we'd have to build the merging tools.
The declarative model is also essential for auditable configuration. In the alternative, a transaction-log approach, it's never clear if one site slowly diverges its configuration from the canonical one.
Comment #26
swentel commentedThis one is also problematic if you already have data in tables that needs to be converted. I had a recent use case where we had a list field where the keys where strings ('man' and 'woman') where we decided to change this to numeric keys. The only way to solve this was with an update hook keeping the old values in memory, changing the table and then re-inserting them.
Comment #27
sun@David Strauss:
One of the essential goals of #1668820: Concept, base class, and interface for Configurables (e.g., node types, image styles, vocabularies, views, etc) is to force-implant UUIDs into every Configurable (dynamic config objects), which should help to resolve the case of renamed Configurables (e.g., fields, but really everything).
The conclusion on leveraging UUIDs stems from #1609418: Configuration objects are not unique (and also #1508872-30: Image effects duplicate on edit)
Btw, in there I also asked the fundamental question of whether config object names really have to be human-readable (e.g.,
image.style.thumbnail), or whether we can't (or actually shouldn't) use the UUIDs as-is in config object names (e.g.,image.style.4bd1c937-f530-456f-a218-241d7bfd40b8). The latter obviously ensures that every config object we're dealing with is actually the intended config object. Simplifying staging, simplifying config import, and everything else.Comment #28
gddI couldn't find it in any of the linked issues, so I'll say it here. Changing the config names to uuids would be an enormous loss of UX. Lets say I want to deploy one view. How do I know which one it is? Lets say I have five pieces of config showing as changed in git status, but i only expected to see four. How do I sort that out? Non-readable config names is a total non-starter as far as I'm concerned.
Comment #29
xjmI think that having the UUID in the config object name will reduce the config system's usability significantly.
I'm not immediately opposed to having it embedded somewhere to help manage the rename problem, though.
Comment #30
sunerm, say, by looking into the file...? ;)
Comment #31
gddIn my opinion that is an excessive amount to ask of users. This system is actually supposed to help moderately non-technical users deploy stuff, asking them to open every view until they find the one they want to push does not help.
Comment #32
eaton commentedUsing the UUIDs in the filenames instead of user-controllable machine names would also make diffing a bit of a beast: most diff review tools allow us to skim through a set of changes to a particular file, but naming the files after the UUIDs would ensure that we'd have to open each one (or memorize UUIDs) to know which config files we're really patching.
Comment #33
xjmThe UUIDs would also be way more problematic for #1186034: Length of configuration object name can be too small.
Comment #34
gdd@damz I'm not sure this is something we necessarily have to worry about is it? We have already punted on these types of changes in the field system, where you actually can't change datatypes or make other complex data-affecting changes at all (I'm not completely clear on what is and isn't allowed.) If you're talking about actual schema changes for modules and the like, then that is really the module developer's problem. I don't consider actual database schema to be config in the sense of what the system is currently covering. The delete/rename issue has several solutions outlined above. I mean, I understand the problem in principle, I'm just looking for actual implementations in Drupal that the config system is meant to cover and not coming up with a lot. Some real world examples would be helpful.
Comment #35
sunHeh, alright, understood. ;) I won't argue on UUIDs in config names any further in following comments on this issue.
I will only amend that the idea of just naturally leveraging them inherently resolves a full stack of foreseeable config import/staging problems that are neither covered in HEAD, nor filed in any issues, and not leveraging them will keep us busy (as in: busy) for several months. Given the current state of the system, it is quite predictable that we'll run into the major bugs and flaws being caused by not leveraging UUIDs only after releasing D8, so in turn, we'll very potentially fail to deliver the goal of a rock solid configuration system that supports to move configuration across systems. There is no "grep" mechanism in the configuration storage controller design (nor in any generalized/abstracted key/value store concepts), so baking UUIDs as keys/properties into config objects doesn't really help with the essential problem space of lookups.
I will go even one step further and say that the entire idea of asking humans to "enter a machine name" in administrative UIs is utter nonsense to begin with, and we're going to let a unique chance pass to eliminate that WTF.
But of course, human readability of config objects/files is a "compromise" to make, and I fully understand the concerns, but I wanted to make sure to point out the architectural problem space. ;)
EDIT: The architectural impact of this goes way beyond the configuration system. Machine names are only used for Configurable Thingies™. Eliminating them means to eliminate (most of) this entire queue of issues. — All of that vs. human-readable config file names. Compromise? WTF? ;)
Comment #36
damienmckennaSeeing as we're onto bikeshed / brainstorming territory, could it default to UUID for all "machine name"-type fields, but allow those values to be manually overridden? Or is there a better place to take this idea?
Comment #37
Grayside commentedSpeaking as someone who lives inside "features module generated infrastructure" driven development, uuids everywhere would be an extraordinary problem for collaboration, troubleshooting and deployment optimization because these are situations where quickly understandable labels are key for rapid understanding, issue queue discussion, and sane configuration sharing across distributions.
Comment #38
gddI'd like to get back to the topic of how we stage things, as opposed to the problem of actually importing them which is IMO separate.
Recent discussions have demonstrated that there is a lot of interest in returning the system to the functionality of changes automatically writing through to files on saves. However this opens up several problems (which are the reasons why we removed it in the first place.)
1) Importing from the same place you're saving can cause race conditions and data getting overwritten
2) It sends a mixed message to users (these files are the representation of your current config ... oh except when you're importing, then they aren't.)
One solution is to add a switch that turns off writethrough on sites you push to. This resolves problem 1 but not problem 2. It also means that if you ever want to synch config back from that site, you have to do an explicit export, which adds confusion to the process (sometimes you have to explicitly export but sometimes not and sometimes the files are canonical and sometimes not.)
Yched proposed a solution wherein we import and export from separate places. This solves the above problems but can make the deployment process more complicated (see issue summary for details.) This also makes things more complicated for non-technical users, where it was nice that they could just ftp push their config directory, reload on the remote site, and be done with it (now they would have to copy from the 'live' directory on localhost to the 'import' directory on the remote site.)
I like the separated directory solution. The separation of concerns is more clean and it clears up a lot of technical issues we have with sharing the same directory right now. I believe that yched's explanation of how a more advanced vcs-based deployment workflow would work makes some sense too. It took me a while to follow and I think that naming causes some of those problems. Think instead of a dev site with two directories - dev_to_stage ('active' on dev and 'import' on stage) and stage_to_dev ('active' on stage and 'import' on dev) - and suddenly it becomes a lot more clear what is going where.
So instead of specifying a config directory in settings.php, we would specify a 'live' directory and an 'import' directory. If we wish to make things simpler for less advanced users and keep parity with the functionality we have now, we can simply do exactly what we're doing now in the default installer, and just specify the randomly-named directory as both the 'live' and 'import' directory in settings.php. This will change nothing functionally from what we have today, except it allows more advanced deployments to hand-craft settings for their own situations (which they almost certainly are anyways.)
Here is how this would look in a textbook dev/stage/live scenario.
This would be the standard workflow for a dev shop type of scenario. If you really need to go straight from dev to live you still can, since all these directories are still in VCS. You will just have to jump through some extra hoops to do so. This is exactly as it should be.
I like this solution and I would like to hear discussion around it so we can move forward and start getting the UI done. The changes needed would be
1) Change settings.php to hold two config directories instead of one
2) Change the installer to acknowledge this (either using the current random directory as both, or by creating default import/live directories.)
3) Writing and committing #1702080: Introduce canonical FileStorage + (regular) cache
4) Implementing #3
Discuss
Comment #39
gddNote that this won't work if #1703168-15: [Meta] Ensure that configuration system functionality matches expected workflows for users and devs happens. This solution would require a separate directory for import. However that should be considered a followup after we hash out whether this whole two-directory system works at all.
Comment #39.0
gddUpdated issue summary.
Comment #40
moshe weitzman commentedIMO the two directory solution is quite elegant.
Also, I think we can expect users to have both dirs and not try to kludge in a single directory solution for crippled environments.
Comment #41
sunI have prepared the implementation for the proposed change in:
#1626584-105: Combine configuration system changes to verify they are compatible (and following; #112 contains working patch; linking to where I started, since I ran into lots of problems, particularly in the installer)
However, please do not comment on the code in here or in that issue — the patch + implementation will be moved into:
#1702080: Introduce canonical FileStorage + (regular) cache
Sorry for that confusing amount of issues, but we want to 1) keep this issue as a pure meta/arch issue, 2) focus on the pure implementation in a separate issue, and 3) I wanted to implement it already and see whether it is possible and compatible with other changes.
Comment #42
sunAdditionally, I've incorporated the rather heavy considerations on machine names and UUIDs into:
#1609418: Configuration objects are not unique
Comment #43
gddWe have consensus here on the two directory solution, but none on the FileStorage + Cache, so I would like to see these be separate patches otherwise we're going to get bogged down in discussion on FileStorage + Cache which is a major architectural change. The faster we can get two-directory in the faster we can move on to working through UI issues.
Comment #44
Anonymous (not verified) commentedis this the place to start a patch for the two-directory code? or should i create another issue?
Comment #45
Anonymous (not verified) commentedcouldn't find an existing issue, so i created #1741804: Implement a config import/staging directory with a first cut patch.
Comment #46
tim.plunkettTagging.
Comment #47
sunIn #1741804-32: Implement a config import/staging directory the question arose what a proper directory name (as well as config storage DIC service name) for the new import/staging/state directory could be:
The patch introduces two constants, CONFIG_ACTIVE_DIRECTORY and CONFIG_STAGING_DIRECTORY, which essentially point to 'active' and 'staging' string identifiers, and by default to corresponding config directory names; e.g.,
files/config_activeandfiles/config_staging."import" doesn't really fly either, because the directory is also used to export configuration.
This is essentially why I chose to go with the name "state" in and since the early implementation in here (see explanation in #15) — however, that term is not ideal either, since we're going to have a "state" storage for persistent non-configuration data later on (#1175054: Add a storage (API) for persistent non-configuration state), so "state" will be ambiguous.
In terms of internal DIC service identifiers, I think that
config.storage.activeandconfig.storage.stagingwould make sense.However, that doesn't really seem to address @yched's concerns I quoted above. Anyone any good suggestions? :)
Comment #48
moshe weitzman commentedI'd love it if someone could update the summary to reflect how we are doing on our workflows. We have made a ton of progress.
Comment #49
owen barton commentedI agree "staging" is going to lead to some potentially confusing conversations ("copy staging from live up to staging on dev, but leave staging as it is for now!").
What about "transfer" or some similar word, indicating that this is for configuration "on the move" (i.e. import or export).
An alternative idea is to just call it "passive" since that is the opposite of "active" and described the main point that it is functionally not in use.
Comment #50
Anonymous (not verified) commentedor, don't allow exports into this dir, just make it imports - that was my original wish for this. each dir does one thing only. i can dream, can't i?
Comment #51
mojzis commentedWith the process described in #38, how do we share settings between 2 developers before putting them on the live server ?
(dev A creates a view, pushes to stage server, dev B should have the same automatically upon pulling from stage server )
I guess i would end up linking the second dir to the first on the dev machine ... but i am not sure that is how it was meant :)
naming suggestion : last / actual
Comment #52
gddThe workflows have largely been solved by the FileStorage + two directory patches, therefore I'm downgrading this back to normal for the cleanup patches.
Comment #53
webchickFWIW, having just come from http://drupal.org/node/1697256, I can say that while the two-directory situation satisfies my requirements for a site like Drupal.org where multiple people are working on it at any given time and the prospect of conflicts is high, it does not do so for a site like webchick.net, where I'm a sole admin.
I purposely went into #1697256-73: Create a UI for importing new configuration blind, ignoring the posted instructions there, in order to simulate a new user of Drupal 8 who's not been privvy to all of the various discussions leading up to this would do naturally. As you can see from comments #73 - #80, I cloned my dev site to production the way I clone every dev site to production in any other application; simply copying over the code files and db. The net effect this had was that both dev and prod were pointing to the same active directory name, and so when I changed settings on dev and committed those, they'd show up on prod upon pull. And that's exactly the workflow I want when I'm in a webchick.net situation, as are probably 80%+ of our users.
I was informed, however, that I was wrong to do this. That what I should've done is set up two completely different sites, with two completely different directory names, and manually copied over from the active directory on dev to the staging directory on prod, then used the import UI. That the way I outlined couldn't possibly work because of the chance of race conditions, and that it's dangerous to call import on cache clear because of dependencies like field. I'm quite sure that's true. I'm also quite sure I won't be the only one to go into Drupal 8 not understanding this, not having read docs, and attempting to deal with Drupal the way I deal with any other application with a DB and files. And I also think that not supporting this workflow, even if we need to put all kinds of nasty disclaimers around it to cover our asses, is a big mistake, and I'd really prefer to sort it out before we get 100K users for D8. :\
However, it's very possible that I'm just an oddball, and my previous experience is clouding my eyeballs. I'm more than willing to accept that is a strong possibility. What might be best is to get some actual "user testing" data, by having people testing CMI who haven't been part of the D8 process and see how they fare. Maybe something like that can be done at PNWDS/BADCamp?
Comment #54
Anonymous (not verified) commentedEDIT - removed unhelpful comment.
Comment #55
carwin commentedI think webchick has made a good point regarding the fact that most end-users won't take the time to read documentation. Let's be honest, most people will come into d8 with the mindset of, "Oh hey I built d7 sites this'll be cake. It has a database and files what's so different?" They'll wait to read the docs until they run into problems. That's just how general users are -- they don't always recognize the implications of what they're doing. Really, without having lurked on IRC chats or read through comments here it wouldn't really have clicked why copying my stuff like normal was a bad idea until it became a problem.
So maybe the question at hand should be, "How do we make it painfully obvious that this is not cool?"
I'm not really sold on the fact that we should support the copying at all, but I do like the part of webchick's suggestion that
Comment #56
swentel commentedI followed the process a little last night as an advanced Drupal developer on IRC yesterday and I was a little surprised by the outcome, but that's because I'm also biased since I've been experimenting already a lot with the configuration system. I'm going to try and share my thoughts here.
I understand that workflow, because in the Drupal world as we know today, there's basically no other option anyway. I do think in the way you deployed your changes, there's some irony here because
dsm()or inspect a database table for its columns or a PHP export in a file (in D7 take any ctools/feature exportable). Thanks to this setup I - as a developer - already found storage bugs in some contrib modules I started porting already. This is a nice side effect of the current system imo.The 2 directories system that is in place protects from breaking your site in severe ways. You basically got lucky at this time :) Let me try to explain by using the analogy with Features. The module allows you to put a lot (nowadays almost everything) in code. That's great. The only way to get your new (or updated) configuration is to take actions by going to the UI and clicking buttons and checkboxes and so on, then downloading etc and then you either commit or upload. This last step is where features has flaws:
Now features also has a 'rebuild' button (or 'drush fu') that simply reverts or rebuilds changes it detects that might now be overridden in case you made changes on the live site too. Only by doing this action, you're sure your changes will be completely active (because it's going to clear caches, create storage tables for fields etc etc).
I absolutely like the way this is setup now. I personally think the CMI architecture right now is already quite solid too. While working on the Field CMI conversion, the process of simply converting to YAML is not complex at all, and writing the hook_import_* functionality is actually ridiculously easy and doesn't involve a lot of code. Having two directory stores might seem confusing, but imho, it is just a matter of having it done once. After that I'm confident people will know how it works.
Having to support it again from the active store is a huge -1 from me, also because I've been following the discussions quite closely and this is simply extremely complex to solve on technical level without having to simply rewrite drupal from scratch. Is this the holy grail and will it work flawlessly ? Maybe not, but it's quite close and I find it a superior solution to anything I've seen popping up in contrib.
Now, how can we help so we inform people about this workflow or even make sure they don't use the active store as their primary source to move changes from one site to another?
CMI. Deploy. Like a boss.
That's about it for now I think. I hope I don't step on anyones toes here, because that's absolutely not my intention at all. I wish English was my mother tongue so I could express it all more better and in detail, I hope it does a bit already though :)
- edit - added the 'update.php' suggestion.
Comment #57
gddThen I don't really understand what the requirements are for a site like webchick.net, other than 'I want a safe way to move configuration between two sites', which the two directory system does in fact support. Is it slightly more complicated than we would prefer? Sure. However in the two years we have been working on this system, this architecture is the only one that has a) received consensus from the people working on CMI and b) actually has an implementation which works.
Also, while the two directory solution is newish, the concept of an external function to import (ui, drush, whatever) has been in place since the very first code sprint. I'm not sure where the idea that you could move config without running an external function came from.
I would argue that the 80% of users you're talking about wouldn't be using version control at all, and would simply be copying files around. If you do want to use version control in this situation and just want to be able to git pull and import, there is a simple tweak you can make to settings.php which enables it. We will of course document all these things (and I don't argue with the fact that the docs are currently lacking) but on the other hand we can't document what doesn't exist.
I think this is a terrible idea. We are basically telling people to use a workflow that will, eventually, *completely destroy their site*. This is irresponsible, no matter how many flashing handwaving disclaimers we put in place. One of the first things that a new Drupal user is going to do is create content types and add fields to existing content types, and this is the single most dangerous operation for the transfer-straight-to-live-with-no-import-button workflow (because Drupal will then try and deal with fields and content types for which tables have not had a chance to be created.) The same goes for enabling/disabling modules, another function that brand new users will be doing a lot of. I would rather have a single set of instructions, that always works, than have two sets of instructions which say 'This set of instructions has two extra steps but always works, and this other one doesn't but 10% of the time your site will be irreparably borked.'
I may be under-estimating the amount of confusion this will cause, but I really don't think it is very bad. I am happy to do some user testing around this, as long as such testing is focused around how we can more clearly communicate a supported workflow to users (and +1 to swentel's suggestions that we focus on this problem instead.) And honestly? I would rather deal with 100K support requests saying "I can't make this work" than 100K support requests saying "My site is hosed, please fix it"
Comment #58
damienmckennaCould @webchick's UX problem be resolved using in-file documentation / or on-screen help that explains the intended development workflow?
Comment #59
webchickI guess what I'm thinking is you don't really have a choice but to support this workflow in some fashion, even if it's just damage control.
As documented in #1697256-73: Create a UI for importing new configuration, this is how I set up my dev / prod environment for the test:
I'm going to wager this is how 99.9% of people do a dev => prod clone. This is how existing dev/prod clones are already going to be set up. Ignore the use of Git; it's irrelevant. What's relevant here is it's a two-step process of:
And heck, Git is the least of your problems. Tools like Dreamweaver, FTP clients, etc. are usually configured to auto-sync files from localhost to production as soon as they're saved.
Drupal doesn't know that both the prod and dev site are writing to the same active directory name. It just knows it has an active directory name and it will write to it and read from it, blissfully unaware of the consequences. And, as far as I can tell, there is nothing you can do to warn someone who has this setup (which is the same workflow as every other PHP application on the planet, so all the docs in the world aren't going stop it from happening) of impending site screwage.
So what I'm trying (and apparently, failing) to do here is be a "canary in the coal mine" for the 100K users who are going to do exactly this when Drupal 8.0 comes out and end up *completely destroying their sites*, as you so bluntly put it. I tried to be extremely meticulous about documenting all of the steps I did and my thought processes, so you can see exactly where they mis-matched your expectations as the system engineer. I'm trying to help, here, and I wouldn't have spent 3+ hours on that review if that wasn't the case. :( (And if this is how 3+ hour reviews get treated, I'll make sure I don't do any in the future, either. :P~)
My findings from that experience were that I strongly believe CMI probably needs at least the following in order to cover our asses here:
1) A validation layer around the active directory, which rejects invalid YAML from being used. (Perhaps that means a rollback mechanism? Not sure.) This would have protected against #1697256-80: Create a UI for importing new configuration, so the case of file conflicts and/or badly manually edited files. (Btw, swentel, I didn't hand-edit anything. The files automatically get updated when you save something in the interface, by design. There is no Export anymore.)
2) An import hook that runs during (or before?) cache clear, which would've picked up the added image effects at #1697256-77: Create a UI for importing new configuration and #1697256-79: Create a UI for importing new configuration. I understand that this runs into huge problems with dependencies, and don't have an immediate answer for it.
Why I suggested user testing (and by that I don't mean "coaching someone one-on-one how to do it properly and then tweaking the docs," I mean real user testing, where you sit someone who's never seen D8 before down in front of it and ask them to perform a task and observe how/where they fail) is because I don't know if my experience is an anomaly; if my brain is just wired really strangely and if my claims of what 99% of people do are wildly off base. But I'm very concerned that I might be the first non-CMI developer to do a thorough front-to-back test of the system. I think we probably want to get that UI patch in sooner than later and then start turning people loose on it at BADCamp and see what happens.
Comment #60
swentel commentedYou're right, apart when fixing the conflict in #80. Sorry about not being clear enough here. The conflict resolution would have never happened though if you used the staging directory :)
Also, I extremely value your testing (!), but I also strongly believe in the two directory structure, we just need to make sure we make this more clear in the future, that's why I also added some suggestions/ideas already to my comment (apart then with the meme), and I actually have another one.
Maybe use the Drupal php storage for active store? By default these directories can't be read from command line or even in finder, so there's no way to copy these files by accident. It's just an idea. See screenshots (these come from testing with the twig patches). Just throwing out ideas here.
Comment #61
decafdennis commentedI think I understand webchick's concern and I think I also understand the advantage of having a staging config directory separate from the active config directory. Therefore, let's explore some solutions that address webchick's findings and do not involve going to a single directory.
I want to propose a solution that's actually already in this issue's summary: have not two, but three directories: staging, development and production. If the system, somehow, knows whether it's on development or production, it can use one of these directories as the active config directory. If you then copy the whole files directory from
development to production, nothing disastrous would happen, because it would use a different active config directory in the production environment.
Off-topic, but related: there may be more use cases for distinguishing development and production, such as development/production-specific configuration, the same way we can do language-specific configuration. Also see #1537198-18: Add a Production/Development toggle
Comment #62
sunJust a quick update from my side:
I thought extensively about this problem space, and there's no mechanism to prevent bad things from happening.
The only remotely available measure would be HTTP_HOST (i.e., replacing
files/config/active_[garbage]withfiles/config/[host]), but 1) there is no host on CLI, 2) requiring one would make Drush very unhappy, 3) HTTP_HOST is not reliable in the first place; e.g., considering multi-site/multi-domain setups.PHP does not provide a unique identifier for the host/server it is running on. All available variables are bound to and inherently dependent on external setup and configuration, so a change in there would cause a false-difference in PHP. File creation/modification times do not help either.
The problem is hardened by the fact that 1) a site is typically initiated and developed on a local host first, and only later on 2) staged to a staging or production server. That process typically involves to mirror the entire application from A to B.
The mirror could only be avoided, if you were able to 1) install Drupal from pre-existing config, and 2) import any possibly existing content from any kind of source, whereas the source might not be reachable over the wire.
1) should be easily achievable, see #1613424: [META] Allow a site to be installed from existing configuration
2) is unlikely to happen for D8, given the current state of affairs of WSCCI and Migrate efforts.
So scratch that and get back to the mirror problem space:
Now let's solve that.
Comment #63
gddI'm not a big fan of building environment-handling into core. If we build it with two specified environments, someone will want three. If three, four. The only thing I can see being useful is 'Allow someone to specify a unique key for environment handling' but I wouldn't want to build said environment handling into the config system itself. If someone wants that, they can build a context handler around the unique keys to do overrides and the like. I really believe the config system has to function without being environment-aware. The state of #1697256: Create a UI for importing new configuration is such that we are actually very close to a solution, and I had a long discussion with webchick about some ways to mitigate her concerns from her review. Many of these already have followup issues as specified in #1697256-94: Create a UI for importing new configuration.
Comment #64
gddActually, you can *already* implement the solution presented in #61 with the system as it is. That is pretty much exactly what I outlined in the chart in #38. Three directories in git, which one is 'active' or 'staging' is set dependent on your settings.php. It takes a little setup, but I did it earlier today to test the UI patch in like ten minutes.
Comment #65
decafdennis commented@#64: Can we take that and somehow build it into the system? Or is it too system/environment/situation-dependent?
Comment #66
gddI think its a mistake to build those kinds of assumptions into the system. I've seen a lot of deployment setups and the one thing they all share in common is nothing. Anyone settings up a three-server deployment can figure out how to change their settings.php pretty easily. This isn't rocket science and the basics of how to do it will probably be built into the comments. Keep things flexible and let people build the system they need.
Comment #67
effulgentsia commentedIf I'm understanding #59 correctly (including the part about ignoring git), then I think the requirements are something like:
- If I'm not using version control, then I want to be able to copy "sites/default/files" in its entirety from prod to dev without blowing away my dev site's configuration. If I then want to update my dev site's configuration to match prod, I want to click an Import button to do it.
- If I'm not using version control, then I want to be able to copy "sites/default/files" in its entirety from dev to prod without blowing away my prod site's configuration. If I then want to update my prod site's configuration to match dev, I want to click an Import button to do it.
- For both of the above, if I have to manually copy files from sites/default/files/config_X/active_Y to sites/default/files/config_Z/staging_W before clicking Import, so be it (would be better not to, but no big deal).
Seems like the above requires that $config_directories in dev's settings.php NOT BE THE SAME as $config_directories in prod's settings.php. Which I think is fine, but the question is, can we do anything to help guide them towards not being the same in a situation where someone creates their prod site by cloning their dev site given the limitations in #62?
I think in most (but perhaps not all) cloning situations, $databases is made different on prod than on dev (either different database name or different table prefix or different password). I don't know if that helps us at all.
Comment #68
owen barton commentedAs much as I like having dev/staging/live named directories that match your actual environments, that feels way way more confusing (to me at least) since those 3 sites would potentially be in 3 different locations, giving you 9 directories, only 3 of which are actually active, and where "dev on dev" can potentially be different from "dev on staging" or "dev on live".
Having active/staging gives you 6 directories and the naming "active on live", "active on dev" etc sounds pretty intuative (to me at least). "Staging" is still a bit confusing - see #49.
Of course there is still the "copy everything from dev to prod" workflow issue webchick found that I think is a serious one and deserves some kind of safeguard. I can think of a couple of options:
Comment #69
andypostSuppose we need raise the priority here to major to make sure core got a proper staging and welcome for eyes here
Comment #70
xjmAgreed @andypost. A lot of the discussion in here is useful, but also predates the CMI UI actually being committed. However, let's repurpose as a meta? It has two child issues I know of, #1831818: Document git config import workflow and #1831798: Update hook_help() for config manager module .
What's really going to crack this nut once we improve the documentation a bit is some serious user testing. (I've talked to @heyrocker and others about this.) Basically, we really need to complete #1735118: Convert Field API to CMI first.
Comment #71
xjmAnd I didn't actually bump the priority.
Comment #72
gddThe biggest thing preventing serious user testing right now is waiting for #1735118: Convert Field API to CMI and #111715: Convert node/content types into configuration. Without those we can't really do any meaningful user testing of anything approaching a real life situation.
Comment #73
webchickOk, let's do this then.
Comment #74
webchickAnd both of those linked issues are now criticals themselves, since they block this one.
Comment #75
moshe weitzman commentedalmost 3 months later, we have #1735118: Convert Field API to CMI but not #111715: Convert node/content types into configuration. Code freeze is imminent. I think we need to proceed with our best guess, and let user testing influence later changes. Thoughts?
Comment #76
gddI feel a lot better about user testing since DrupalCon and the introduction of #1998576: Make the config import process use full config trees again. It will still be hard to do realistic user testing because of the various things not implemented, but I'm not going to stop anyone from starting on it. Big stuff that still isn't in place:
#111715: Convert node/content types into configuration
#1740378: Implement renames in the import cycle
#1808248: Add a separate module install/uninstall step to the config import process
Comment #77
webchickSo now that #1969698: ConfigEntity::save() should disallow saving ID/UUID conflicts (Field UUID changes can badly corrupt field data) is in, I literally have no idea how one sets up a dev/prod server anymore for testing. The instructions in https://drupal.org/documentation/administer/config are no longer accurate, and need to be updated.
Comment #78
catchBoth the issues that were originally blocking this one were fixed.
Comment #79
jstollerI was involved in several conversations at DrupalCon Portland, and again at DrupalCamp LA, about how the new configuration management would work with version control and deployment, which led to this post on Drupal Answers, which led me here.
The specific use case I'm considering is a small group of developers collaborating on a Drupal site and using git for version control and deployment. Assume each developer has one or more local development environments where they do their actual work. Assume there are also at least two installations of the site on a central server—one dev and one production—each pulling from a separate branch of the repository. My expectation is that there will be an easy way to add configuration to the repository and share it between all of these environments. In most cases, I would expect this to be as simple as running
git pull, followed bydrush updb, or something along those lines.Based on my admittedly limited understanding of the inner workings of this system, here is what I think would be needed in order to facilitate this:
For the use case in question, I would then include /files/config_xyz/staging/ in my git repository and enable both of these options in settings.php. That way every time there is a configuration change in my development environment, the change will automatically show up in git, allowing me to immediately see what I did and commit the change, if appropriate. Then, when these commits are pulled down to any of the other site installations, Drupal will recognize the configuration changes in staging and allow me to import them, updating the site.
Does this make sense?
Comment #80
joachim commented> Developers can then iterate on their site and its config files with $VCS, and share changes between other devs in normal $VCS ways.
I'm confused about how this step works.
AFAICT, the config files are in sites/default/files/configHASH.
But sites/default/files is typically excluded from $VCS, with a .gitignore for instance.
So how are config files to be committed to $VCS?
Comment #81
swentel commentedsettings.php allows you to put config directories anywhere, even rename the default.
Comment #82
jstoller@joachim, I don't think there's any rule saying git must ignore everything in the files directory. The ignore directives can be changed. That said, I also am having trouble understanding exactly what we're expected to commit and how.
@swentel, yes, but I'm afraid it isn't enough to just rename the directories. At least, that won't address my use case in #79.
Comment #83
joachim commentedIt's fairly standard procedure to have a .gitignore in your project's root which has:
sites/*/settings*.php
sites/*/files
Having the config folder inside the files means you can't just have that any more -- you'd need to specifically ignore each subfolder in files, *and* make sure that no part of Drupal is writing files direct to that folder without a subfolder.
I can see how I can change the config folder location by setting $config_directories in settings.php. But then that's a fiddly set-up step that a developer using workflow 3 has to do for every new site. That's not terribly good DX for workflow 3 -- and I thought that was the best practice workflow for Drupal.
Comment #84
jstoller@joachim, you could still exclude the contents of the file directory in general, but then specify specific files within it to include. The .gitignore file would be something like:
Of course, this still doesn't solve the problem at hand, unless that staging directory actually contains all the latest configuration files. And right now I don't think it does.
Comment #85
alanburke commented@jstoller Some good thoughts in #79
I like the idea of writing any config changes to the staging directory automatically - As a dev I can then see what changes I have made using git tools, and can choose to commit part or all of what I've done.
Right now the staging directory isn't cleared out post import - but copying the active directory into staging is required to know whether changes need adding to git
Perhaps a first step would be a drush command to match 'drush config-import', which copies all in active to staging.
How are you managing the issue of installing a site locally, putting config in git, pushing that to another instance of same site, and importing it there.
I'm hitting issues with 'UUID errors' - 'Drupal\field\FieldException: Attempt to create an instance of unknown field ' but I'm not sure whether my workflow is to blame.
I do a clean install on both instances, then work on one instance, add to git, and then try to import on second instance.
Comment #86
Grayside commentedI'm trying to wrap my head around how distribution maintenance and update paths will work with CMI. Hit list for context:
User downloads a new release of the Win Distribution.
I've done some googling and extensive issue queue reading, but I can't quite find anything like a goal for the technical interactions around CMI or the process a developer will go through to write update hooks, use drush, or what have you to make these things happen.
Some of this is tangled with the concept of reverts, but I'm reading a trending negative perspective in #1497268: Add revert functionality to Config entities without details on what would be used instead.
Comment #87
webchickAfter much gnashing of teeth, I think I finally have some working instructions for setting up a dev and prod site based off a git repo:
https://github.com/webchickenator/drupal8-demo/blob/master/cmi.sh
Not 100% working yet, but hopefully a start at ensuring I don't horribly embarrass myself in a demo ever again. ;)
Comment #88
alanburke commented@webchick
Looks good, but with a curious step involving copying of the database.
Is that necessary?
Can the dev site not be reproduced solely from the config files?
In D7, we use a custom install profile to let all users create their own instance of the site,
and then use features to share config from then on.
I was hoping we could avoid that step by letting users just install using the minimal profile,
and then use drush cim to import all the config, but I've hit errors as mentioned above.
Either way - thanks for the script - might use it for a demo session myself!
Comment #89
webchickThe config is stored in files, but there's still the matter of content (nodes, users, taxonomy, etc.) which are stored in the DB.
At one point awhile back I'd tried it the "install two sites" way, since that's also my preferred approach, but the UUIDs in config entities (fields, views, etc.) crapped all over that. It's possible that this would be fixed now that we hard-code UUIDs to not be unique universally :P~ as of a couple weeks ago. But this approach also gets tricky when trying to keep track of which config_JHAGSHJKGAHSJGAJKS belongs to dev and which to prod, but there's likely a workaround for that.
Comment #90
alanburke commentedI'm not too worried about the content, as that will never be in version control.
[We usually use a migrate script to import content as part of a build script.
All going well, that will be available for D8 from the very start]
With the minimal profile, the problem of conflicting UUIDs in two different installs is almost sorted.
Only 3 files generate unique new uuids on each new install.
But maybe I should look at at different issue for that.
Comment #91
catchWe might want to say that the minimal profile shouldn't create any default configuration at all?
However that'd still mean that uuid conficts happen with any other install profile - at least until we've resolved that issue.
Comment #92
alanburke commented@catch - I think the minimal profile generating config files is fine.
The trick would be that the config generated using that install profile would be the 'exact' same each time.
That way, there would be no need to share a DB between 2 devs working independently.
Dev 1
Installs using minimal profile
create content types, configure site etc
config active to staging
commit staging to repo
Dev 2 / Staging server
Installs using minimal profile
imports config from staging
That would work for me - no need to share DB at all
Of course, if we could do the same with the standard profile, even better.
[of course we still have to share content and files at some point, but that's outside the realm of CMI I guess]
Comment #92.0
alanburke commentedstatus
Comment #93
alanburke commented@jstoller - For 79 - point 2
The issue of writing to the staging directory when the active directory is updated, can be handled with a Grunt watch task.
https://github.com/gruntjs/grunt-contrib-watch
Comment #94
jstoller@alanburk — I know of Grunt and have been meaning to look into it for quite some time now, but have not had the chance. That said, I don't think "use Grunt" should be our answer to this problem. That expects a significantly higher level of technical expertise from people who are just starting to figure out git. It's too high a barrier to entry. IMHO we need a simple Drupal based solution to the problem and I don't think what I proposed is too much to ask from the system.
Comment #94.0
jstollerAdded related issue
Comment #95
fagorelated: #2130441: Properly document backup workflow that includes database + configuration
Comment #96
sunre: @alanburke + @catch in #91:
Instead of hacking any kind of installation profile, that was the whole point of:
#1613424: [META] Allow a site to be installed from existing configuration
But the issue was preemptively closed.
Comment #97
alexpottDowngrading since there is no actionable work here. Tagging with revisit before release to ensure that we have any required documentation in place. Unpostponing #1831818: Document git config import workflow as a documentation task.
Comment #98
xjmComment #99
alexpottClosing because this because the workflow discussed is not longer the way CMI works and people are using CMI successfully today.
Comment #100
alexpott