
By bjaspan on
Executive Summary

In mid-December, eight Drupal developers held a code sprint at the Acquia offices in Andover, MA with the goal of “implementing Fields in Drupal core.” The attendees were Dries Buytaert, Yves Chedemois, Florian Loretan, Barry Jaspan, Károly Négyesi, David Rothstein, Karen Stevenson, David Strauss, and Moshe Weitzman.
During the sprint, we hashed out some major architectural breakthroughs, wrote lots of code (including unit tests to make sure the code keeps working!), and organized ourselves to help push through the remaining items which were not able to be completed during the sprint. We achieved our major goal: implement a "Field API" in core that cleanly allows attaching fields to both nodes and users and, by extension, any other entity type that wants them. The rest of the post contains more details about what we accomplished.
There is still plenty to do and we need your help! To jump in, visit our Drupal core improvements: Field API page.
We would like to give a huge thanks to the Drupal community and all of our contributors that made this sprint possible. This experience has proven how important sprints are and how effective they can be, and we hope that each of you will consider donating to see further sprints happen, such as the forthcoming Drupal.org Redesign sprints.
Background
The Fields in Core sprint was only possible because of a lot of thought, discussion, and design work completed previously.
The Drupal community has been discussing “comments as nodes,” “users as nodes,” and “CCK (content construction kit) in core” for years. Eventually we agreed that we needed some kind of unified “Data API” to organize operations on these and other types of entities. A single “Data API” has not yet been created, but particularly starting with Drupal 6, many different aspects of Drupal have moved towards a more unified and regular approach. For example, Drupal 6’s Schema API provides a consistent way to manage database tables; Drupal 6’s new menu (“callback router”) system provides a unified way to load objects of any type based on URL components and provide the objects to callbacks; Drupal 7 is moving towards a more organized method for rendering content from multiple object types into multiple output formats (such as XHTML, XML, JSON, …).
In February 2008, the Data Architecture Design Sprint (DADS) took place in Chicago. Starting (as always) with an unrealistically large to-do list, DADS clarified the idea that Drupal’s strategic advantage in the marketplace is an architecture that allows adding value to content, concluded that supporting Fields (a la CCK) on local and remote data directly in Drupal core would enhance that advantage, and specified how CCK could be re-factored to achieve Fields in core with minimum effort.
Throughout 2008, Barry began implementing the Field API for core and presented progress at Drupalcon Boston and Drupalcon Szeged. At the same time, Karen and Yves were working feverishly on CCK 2.0 for Drupal 6, leaving them no time specifically for Fields in Core (though much of the CCK 2.0 work they did prove extremely useful for the Field API later). The end result is that the Field API and CCK 2.0 diverged, leading to all the expected problems with forked and fragmented code.
Finally, everyone agreed that getting Fields in Core done absolutely required getting the Field API and CCK development to be synchronized, and that the best way to accomplish that was to get at least Karen, Yves, and Barry in the same room to bang it out. Thus the Fields in Core code sprint was declared.
The Field API follows the designs decided on at DADS remarkably closely, and the DADS Final Report is therefore a good introduction and explanation to the concepts involved. The Field API does not directly implemented either Content Model 1 nor 2, though it is probably closer to 2; that part of the DADS results were the least well understood and are probably worth ignoring.
Goals of the Sprint
As always, we started with an unrealistically large list of desired goals. We quickly reduced it to a single hard requirement: by the end of week, implement a "Field API" in core that cleanly allows attaching fields to both nodes and users and, by extension, any other entity type that wants them. After a seemingly slow start, we achieved this goal and, it turns out, several others.
Define Field API Architecture
The Fields in Core sprint was mostly about implementing the Field API. Documentation for the API is under development; see Current status and how to help. This section provides a brief introduction to the Field API so the rest of the document makes sense.
The Field API has three components and therefore three separate focuses of functionality (note that the names for these API sub-groups are still under discussion):
- Field CRUD (Create/Read/Update/Delete). Functions used by modules to create content types and/or fields for themselves or other modules to use. For example, the Image module might define a node type called Image that contains a single image field. Generally, this occurs inside module install hooks. Also, the CCK UI uses the Field API CRUD functions for its major functionality. This part of the API first appeared in CCK D6, but gets massively redesigned for 'Fields in D7'.
- Field types. Hooks that let modules define field types (text, image, nodereference...) and their 'plugins' (form widgets, display formatters). The Field module controls the database schema, storing and loading data, generating Form API data structure, etc. based on the behavior of these hooks. This is currently implemented in the field modules via hook_field and friends. This part of the API has been "the" CCK API from the early D4.7 releases up to D6, and sees a few adjustments and Developer Experience enhancements but no fundamental change.
- Field attachment. Functions used by modules that implement object types that want to support having fields attached, like Node and User. For example, node_load() passes the node object under construction to the Field API Attachment functions to retrieve all fields for that node (based on its content type, node id (nid), and node version id (vid)). user_load() can do the same thing. This part of the API is brand new for 'Fields in D7'.
Developer experience design goals
The Field API is intended to meet a number of developer experience (DX) goals, hopefully as part of a trend to meet these goals throughout all of Drupal. Any failure to meet these goals represents a bug to be fixed in the Field API:
- Well-defined data structures with a unique public representation.
- Eliminate all $op hook parameters, putting them into the hook function name instead.
- No Form API assumptions; drupal_execute() is never required.
- Maintain intra-process API integrity; no static caches that require manual clearing.
- Use defined constants instead of literal constants for arguments; e.g. FIELD_FOO_ENABLED or FIELD_FOO_DISABLED instead of TRUE or FALSE.
- Full support for command-line or daemon processes. Do not assume the Field API is being used from within a page request.
- Use exceptions instead of return values for error conditions. Drupal is one big failure to check return values.
Accomplishments
During the sprint, we accomplished goals in three categories: design discussions and decisions, code written, and developer/community engagement.
Design Decisions
Everyone came to the sprint wanting to get straight to writing code but we found ourselves having a lot of “before we can get started…” discussions. Some of these came from not everyone being familiar with all the background, some were re-hashing of previous discussions, and others were genuinely new topics. We ended up spending about two days in total in non-coding design discussions. Topics included:
- Split between core Field and contrib CCK.
- Terminology: Field vs Instance; Field CRUD/Definition/Attachment API; “Content type” versus “Bundle”
- What properties are per Field vs. per Instance
- Required vs. optional attributes for creating fields and instances
- Field CRUD API creation paradigm
- Field object representation: Array vs class stdClass vs class Field
- Field Attach is pull (e.g. called from node_load) vs. hooked
- Field display, core vs. contrib. (will need a separate core patch to cleanup the notion of 'context / build mode')
- All per-field storage tables (see below for more details)
- Integer ID keys vs. varchar for entity types in field data tables
- Field data tables keyed by entity type and ID (e.g. node/vid or user/uid). Bundle names are also stored for delete as a special case.
- Revisions in a separate table
- Batch deletes and the "deleted" column
- Materialized views
- Test methodology
The sprint team thought it was crazy to have spent two of our five days talking instead of coding until we made a list of everything we covered and realized how much ground it covered. We intend to document each of the discussions and decisions in a set of handbook pages on drupal.org for future reference.
Field storage
The most contentious and long-standing design debate surrounding Field API is the way field data is stored in the local SQL database.
CCK uses a hybrid database schema. All fields that are single-valued and not shared between multiple content types are stored in a single wide "per-content-type" table for the one content type they are assigned to. All fields that are multiple-valued and/or shared between multiple content types are stored in separate "per-field" tables. For example, suppose you have two text fields, A and B. If they are both single-valued and assigned only to the Story content type, we get one database table:
| Table: content_type_story | |||
|---|---|---|---|
| nid | vid | A_value | B_value |
| 12 | 12 | Hello | world |
On the other hand, if fields A and B are both multiple-valued, we get two database tables:
| Table: content_field_A | |||
|---|---|---|---|
| nid | vid | delta | A_value |
| 12 | 12 | 0 | Hello |
| Table: content_field_B | |||
|---|---|---|---|
| nid | vid | 0 | B_value |
| 12 | 12 | 0 | world |
The advantage of per-content-type tables is that many fields can be loaded and saved with a single query, whereas with per-field tables every field requires a separate load or save query. The advantage of the CCK's hybrid storage model is that automatically it uses this more efficient form of storage when possible and falls back to per-field storage when necessary.
Some of the disadvantages of the hybrid storage are:
- It requires complex, fragile, and difficult to maintain code.
- Changing a field's cardinality or sharedness, a fairly frequent operation on live sites, requires changing the database schema. Particularly for large tables, it is difficult or impossible to make these changes safely without risking race conditions, lost data, PHP page request timeouts, and other problems. The CCK maintainers (Yves and Karen) who have the most experience working with this code say that it is a nightmare.
The advantage of per-field storage is simplicitly. All the tables have the same basic layout, so the code to generate and use them is simple. Changing a field's cardinality or sharedness is trivial. Fundamentally, it is possible to implement per-field storage correctly and reliably, whereas with the hybrid model it may not be.
The disadvantage of all per-field storage is increased performance costs. Field operations involving N fields always requires N queries, even if the fields are single-value and not shared. For object load operations (such as node_load()) this is not a big deal because loaded fields are cached per-object, though custom queries (either manually written or from Views) can end up requiring a lot more joins. For object save operations, the additional write queries are unavoidable, though particularly busy write-heavy sites can mitigate the problem with master/slave database servers.
The Field API's default storage module, field_sql_storage.module, uses all per-field storage. The code sprint team debated the issue at length and the final vote was not unanimous, but a decision had to be made and we opted for the approach that we knew would work and could be implemented efficiently.
The default field storage module is not the last word, however. Three alternatives exist:
- A contrib module, Per-Bundle Storage (PBS), re-introduces the hybrid storage model by automatically maintaining redundant per-bundle (the equivalent of per-content-type) tables for all limited-value fields. PBS tables actually contain fixed-multiple-value fields (e.g. 3 values, but not unlimited values) as well as shared fields, and thus allow more field data to be loaded in a single query even than CCK used to. PBS completely eliminates all read-time performance penalties, though it does leave the write-time performance penalty in place.
- Another optional module, Materialized Views, provides an even more powerful and flexible method of denormalized data storage that improves read performance not just for field data but for any of Drupal's tables. See Introducing Materialized Views for more details.
- The Field API uses a pluggable storage engine. While the default storage engine uses all per-field storage, it is probably possible to write an optional field storage engine that re-introduces directly hybrid field storage.
Code Implementation
Code implemented includes:
- Most of the Field CRUD API
- Most of the Field Attach API
- Most of the Field Types API
- A great deal of supporting code such as the Field Info API which collates information about the fields, instances, widgets, formatters, and bundles in the system.
- Doxygen documentation for most of the above.
- Changes to node.module and user.module to use the Field Attach API, thus “field-enabling” node and users.
- Unit tests for all of the above that pass, though they are by no means complete.
- Updated the CCK UI contrib module to use the Field API to provide the same kind of field management functionality available in D6 CCK but now for nodes and well as users.
We’re proud of the decisions we made and code we wrote. However, we believe our most important accomplishment is getting eight major Drupal developers, including both CCK maintainers, fully engaged in the Fields in Core process and synchronized with each other. Only so much can be accomplished in one week, particularly with such a complex topic, but we did enough and built enough momentum to get the project done in time for Drupal 7.
Sample code
As a quick introduction, here is sample module install file that uses the new Field API to create a new text field and assign it to “article” nodes and all users:
function demofield_install() {
// Create a text field.
$field_name = 'demofield';
$field = array('field_name' => $field_name, 'type' => 'text');
field_create_field($field);
// Create a field instance structure.
$instance = array(
'field_name' => $field_name,
'label' => 'Demofield Demo',
'description' => 'This is a demonstration text field.'
);
$instance['widget'] = array(
'type' => 'text_textfield',
);
$instance['display'] = array(
'full' => array(
'label' => 'above',
'type' => 'text_default',
)
);
// Attach the field to all users (because user.module does not
// define multiple "content types").
$instance['bundle'] = 'user';
field_create_instance($instance);
// Attach the field to "articles" (a name defined by node.module).
$instance['bundle'] = 'article';
field_create_instance($instance);
}
Screen shots
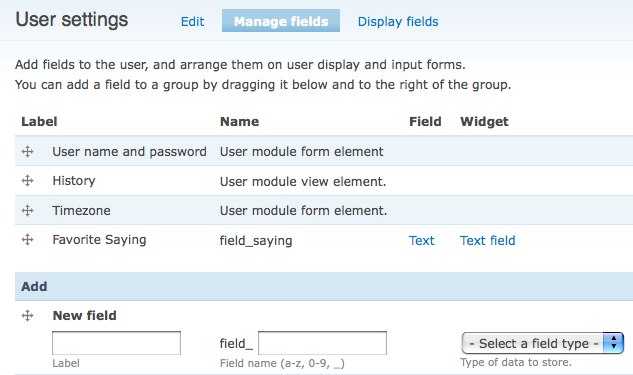
This screen shot shows the page to manage and add new fields to users, with the custom field "Favorite Saying" already added:
Once a field is defined, it appears on the user edit form and profile display page:
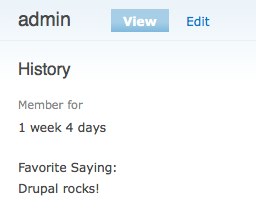
Of course, there is still plenty of user interface and theme work to be done here.
Current status and How to Help
The initial Field API patch has been submitted to d.o. You can find this and all other Field API patches at http://drupal.org/project/issues?projects=3060&components=field%20system.
To help with Field API, please visit http://drupal.org/node/361849.
Code Sprint Best (?) Practices
Many of the participants in this code sprint also attended the DADS sprint and we benefited greatly by following all of the Lessons Learned listed in the DADS sprint final report. However, that was a design sprint. This was a code sprint and we developed some additional practices that we recommend for future core code sprints:
- We had 6-7 developers working on a large core patch simultaneously. We needed to be able to share our incremental changes constantly and there is no way we could have gotten patches committed to Drupal HEAD in a timely fashion (especially early on when the changes had syntax errors!). We set up our own separate HEAD repository so that we could all make frequent commits. We used Bazaar but other version-control systems would have worked as well. However, CVS really sucks for everything.
- We spent the time to break up our to-do list into a number of small tasks (we used the Scrum model of User Stories and Tasks). Using the d.o issue queue for all these small tasks would have had too much overhead, so we used a Google Spreadsheet to track them all. This made it very easy for each developer to grab individual tasks to work on without worrying about duplicating someone else's work.
- When the sprint was over and the initial rapid pace of change declined, we began posting patches for review against HEAD to the d.o issue queue for community review. However, during the review process before the initial patch was committed, we kept using the Bazaar repository for development because it is just impractical to have multiple developers working on a large patch file simultaneously.
- At the same time we posted the initial patch for review, we migrated our to-do list from the Google Spreadsheet to the d.o issue queue. This made it much easier for the rest of Drupal community to contribute because it is the issue tracking system they are familiar with.
- Finally, we realized that for a large and complicated core patch, it is very difficult for many developers to take the time to understand and review it. However, it is much easier to read and review API documentation, and by reviewing the documentation they would implicitly be reviewing the design and code. Therefore, we wrote Doxygen API documentation, posted it on a publicly accessible site (using the API Module), and created a separate d.o issue for reviewing the documentation.
Sprint Contributors
Many individuals and businesses came together to make the fields in core sprint a success. Most notable were Yves, Karen, and Moshe, who donated a week of unpaid personal time. Achieve Internet, Acquia, Four Kitchens, and NowPublic all donated a week of an employee’s time. Acquia allowed us to camp out in their offices for a week (secretly, we know they loved having everyone there!). We also received over $5,600 in donations from 146 sponsors throughout the community. We and everyone in the Drupal community deeply appreciate all this support to benefit the future of Drupal. We will provide a financial report of how the money was spent once all the details and receipts are in.
This code sprint generated an enormous return for a fairly small investment. Hiring these eight developers and bringing them together in one place to work for a week would easily cost over $50,000 USD. Instead, we spent barely one-tenth as much and accomplished a goal the Drupal community has sought for several years. There are several other key Drupal sprints coming up, and our experience with this one shows important and effective sponsoring them can be.








Comments
This is great contribution.
This is great contribution. Having discussion like this will certainly enhance the overall architecture of Drupal. Thanks for all the work.
Hope to start using these patches soon !!
Edit - Specially good are the part about auto creating the cck fields.
- Victor
Search Drupal.org | Lamingo | Tax India | Drupal Jobs | FPGA
!
Wow! Looks fun! If only I had those kind of skills ;]
One day I dream of custom
One day I dream of custom comment fields.... I know, I know, database overload :)
You folks are great!
You folks are great!
Go Massachusetts.
I think I love you!
This will be a great addition to Drupal. Thanks for all the effort.
I think I cried a little
I think I cried a little while reading this
awesome work! kudo's beyond kudo's
Looks great, really exciting
Looks great, really exciting stuff. Very interested to see how fields will work with users, will it do away with the need for content_profile?
Views next...? http://millwoodonline.co.uk
Good work guys!:)
Good work guys!:)
Good job
Thank you for all the hard work.
you are great men,drupal is
you are great men,drupal is great work! good for you and drupal.
---------------------------------------------------------------------------
Drupaluser.org----Sea water droplets together
_
You did see that one of the attendees and a maintainer of the cck module is Karen Stevenson, right? ;-)
===
"Give a man a fish and you feed him for a day. Teach a man to fish and you feed him for a lifetime." - Lao Tzu
"God helps those who help themselves." - Ben Franklin
"Search is your best friend." - Worldfallz
word prolly just an
word
prolly just an oversight, but still, good to point out...
Would have been nice
... to get Karen in a photo. Drupal is a male dominated field and it any women working with Drupal should get props.
Karen was actually in the
Karen was actually in the room when the picture was taken. She is to outside the left edge of the frame. It is indeed to bad that she isn't visible.
Sweet
LAN party!
Great, absolutely
Great, absolutely great!!
It's nice to see how Drupal is growing more and more. Especially I'd like to say THANK YOU for thinking about all the existing Drupal-Code and how to make it better and easier to use for any purpose.
Even if there are those great CCK-Modules, ... you take the time to make it a tick better!
thanks!!!
http://www.DROWL.de || Professionelle Drupal Lösungen aus Ostwestfalen-Lippe (OWL)
http://www.webks.de || webks: websolutions kept simple - Webbasierte Lösungen die einfach überzeugen!
http://www.drupal-theming.com || Individuelle Responsive Themes
God bless Drupal!
I never see a CMS with the super spirit like Drupal.
I hope the Drupal super team not only focus on the API but also a user friendly system, like:
- able to install module without FTP/CPanel
- not only show us the available updates for module but also can update them like "automatic update in Windows"
Again, God bless Drupal!
The ability to search for,
The ability to search for, install, and upgrade modules from within Drupal with a new module page is being discussed at http://groups.drupal.org/node/10919 and http://groups.drupal.org/node/17765
CCK Fields in Core upgrade path
I'm just wondering what the upgrade path will be like, lets say you've used the core profile module in Drupal 6 to add fields will they then become CCK Fields in Drupal 7?
I guess the original profile fields will have to be mapped to a corresponding CCK field. But that leaves me a concern, if you created a "single-line textfield" in Drupal 6 and labeled it "Country" in Drupal 7 you'd want this to be a CCK Location field but I can't see an easy way of doing it even though it would be really handy.
Upgrade path
We have not even started writing or thinking about an upgrade path. Everyone agrees that there will be one. However, I do not think there is a precedent for such a substantial migration of database-related functionality from contrib to core, so I'm not sure how it will work.
My first thought is that there is no reason the upgrade path has to be in core. This isn't an upgrade from D6 core to D7 core, it is a migration of data from contrib to D7 core. Do we really want to encode knowledge of past contrib modules into core? It seems a bit ugly to me, with no real gain. That said, whether the upgrade path from CCK to Field API is in core or not does not much affect the actual code that has to be written. There is a pretty clear mapping from CCK to Field API, so it shouldn't be that tough.
It isn't clear that we even want a fixed upgrade path from profile.module to Field API. They do not conflict so profile.module can survive into D7. Also, as you point out, there is not necessarily one correct way to do the conversion. A "Convert Profile to Field API" contrib module could provide a UI to let you do things like assign the Country profile field to a Location field type, whereas a fixed upgrade path could not.
node import
Maybe a combination of a D7 node import plus a new "node export" module would give users the flexibility to i/o their CCK content into Field API?
I'm curious to see how all those CCK modules like Emfield and Link will plug in down the road.
This is not any easier or
This is not any easier or harder than the upgrade path from the current CCK to the new fields in core. Yves and I have been jotting down notes about all the things that will need to be done, and it's a huge long list. The upgrade path will be quite challenging. I'm not sure it's even possible that an upgrade path from profile module could be any more difficult than the CCK upgrade will be, they will both be challenging.
We're not even going to start thinking about upgrade paths until the core API is stabilized, then we will have quite a project (one which I hope others will jump in and assist with). But our early thoughts were that we would handle the upgrade in the Content module install file. Once everything is updated, Content module will go away, because in the D7 code our new module for the non-core part of this will be the 'CCK' module rather than the 'Content' module. That gives us a clean start for the new API, gets rid of all the old crufty legacy update code, and gives us a namespace that matches the file location.
Drupal development using Bazaar?!
...I think I may have just wet myself.
The Fields API work itself is outstanding, but I am even more stoked to see a mature, powerful DVCS being used for Drupal development, particularly bzr. Here's hoping it's a sign of changes to come for the project as a whole!
LOL
and then ROFL and then IWM (I wet myself)
-----------------------------------------
Joep
CompuBase, Drupal, websites and webdesign
-----------------------------------------
Joep
CompuBase, Dutch Drupal full service agency
bzr isn't a new thing
There has been a bzr mirror of Drupal CVS for a few years now, and it has been used for projects like this before (maybe not of this scale though?).
http://drupal.org/node/45368
https://launchpad.net/drupal/+branches
It doesn't mean the drupal.org will be shifting off CVS anytime soon though.
--
Anton
I know it's not a new thing;
I know it's not a new thing; I've been using it for years! Mirrors aside, Drupal still has a CVS-oriented development process. A shift is exactly what I was expressing hope for.
MySQL has moved entirely to Bazaar; GNOME has moved from CVS to Subversion and is evaluating DVCS for another switch.
Regardless of how reliable or familiar CVS is, newer generations of SCM tools provide undeniable benefits which these huge, thriving projects are wisely taking advantage of. I would be thrilled to see the core devs realize how much Drupal stands to gain from a similar move.
Why CVS?
See Why is Drupal still using CVS and how can I help change that?. And please, let's not discuss that in this issue :)
--
The Manual | Troubleshooting FAQ | Tips for posting | How to report a security issue.
Great effort
Just great to read all the work that has been done.
The whole concept of having the community pay for these kinds of complicated core additions is the way to go imho! Now we can make big steps forward.
I think it is an excellent way of funding development in an open source environment:
Community funded development
Keep up the good work!
-----------------------------------------
Joep
CompuBase, Drupal, websites and webdesign
-----------------------------------------
Joep
CompuBase, Dutch Drupal full service agency
Business buzzword BS
And with that turn of phrase created, and all the developers' eyes rolled in disgust at it, so ended the business guy's ability to contribute anything to Drupal for that day.
Everything else, though, is absolutely awesome. I've been waiting for this for years.