So we've had Git deployed for about a year now, but largely still use conventional patch-based workflows when it comes to collaborating (particularly in core). There are a few brave trailblazers who are trying to use a more Github-like approach, where they do work off in a sandbox project away from the main queue until they have something worth looking at. The problem with that is the lack of visibility among other collaborators within the "parent" project, and this has been especially problematic in cases like Bartik (in which there were forks of forks of forks and no clear delineation as to whose fork had the latest stuff in it) and WSCCI (which is attempting to re-write large swaths of core without the benefit of large swaths of core developers who understand the subsystems they're touching having any idea what's going on).
However, it's pretty clear that in order to scale the community and our ability to collaborate with one another as we grow to our next 700K users, we really need to figure out how we can best use the distributed workflow that Git allows us, so that people can work "off the grid" until there's something to show, but core generalists/committers can keep an eye on things coming down the pipe before they're blasted in the face with an unreviewable 500K+ patch.
Mark Sonnabaum and I had a discussion tonight in #drupal-contribute about how we might better integrate sandboxes with their parent projects. Here's my interpretation on how this might work, encompassed with some late-night omnigraffling/skitching.
Show sandboxes on projects
We add a node reference field on projects that associates them with their "parent" projects, and then keep track of sandboxes for a given project on a tab. And of course, you could make sandboxes of sandboxes if you wanted to, since they're also just projects. (Normally, though, you'd just add more maintainers to the canonical sandbox).
This is basically what you do when you're kind of still figuring things out and shooting wild and crazy code around that people don't really need to look at yet.
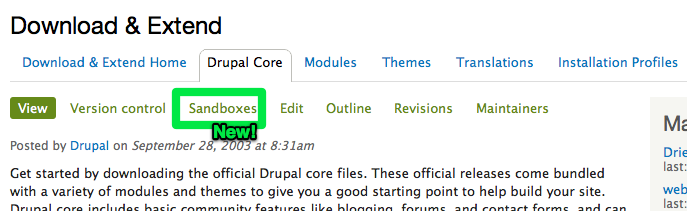

Have a view for associated sandbox issues
People like Dries, catch, sun, xjm, David_Rothstein, me, etc. who need to keep abreast of major happenings across all of core cannot realistically follow 300+ separate sandboxes. So for us, there's an alternate view of the core queue that pulls in issues from sandboxes with a node-reference to the current project.
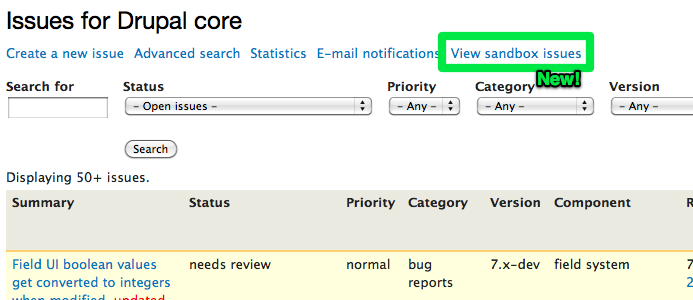
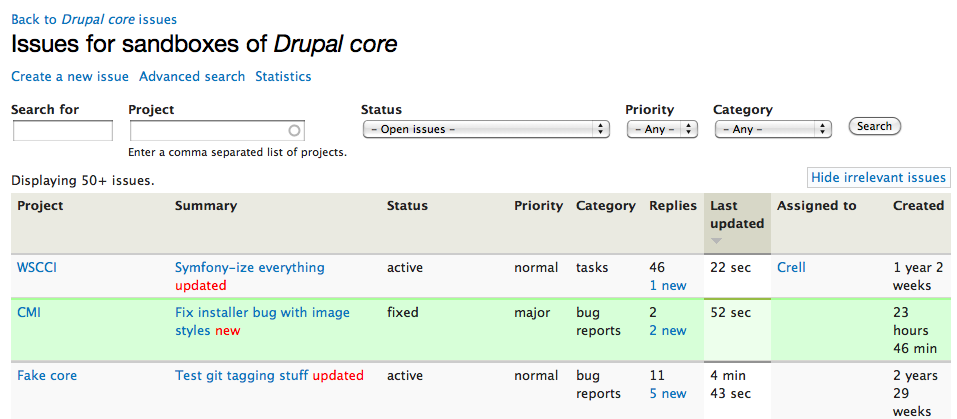
Pull requests
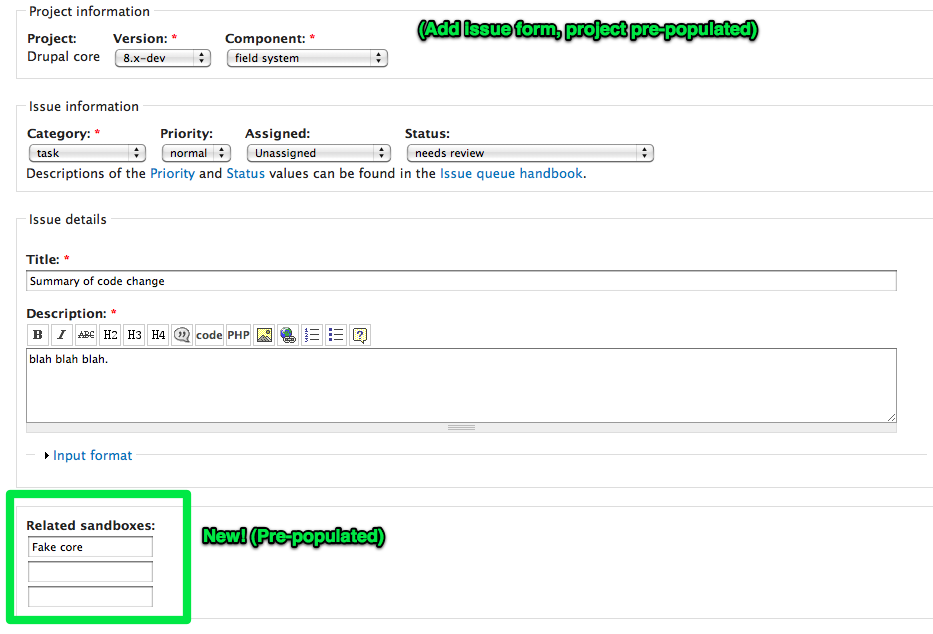
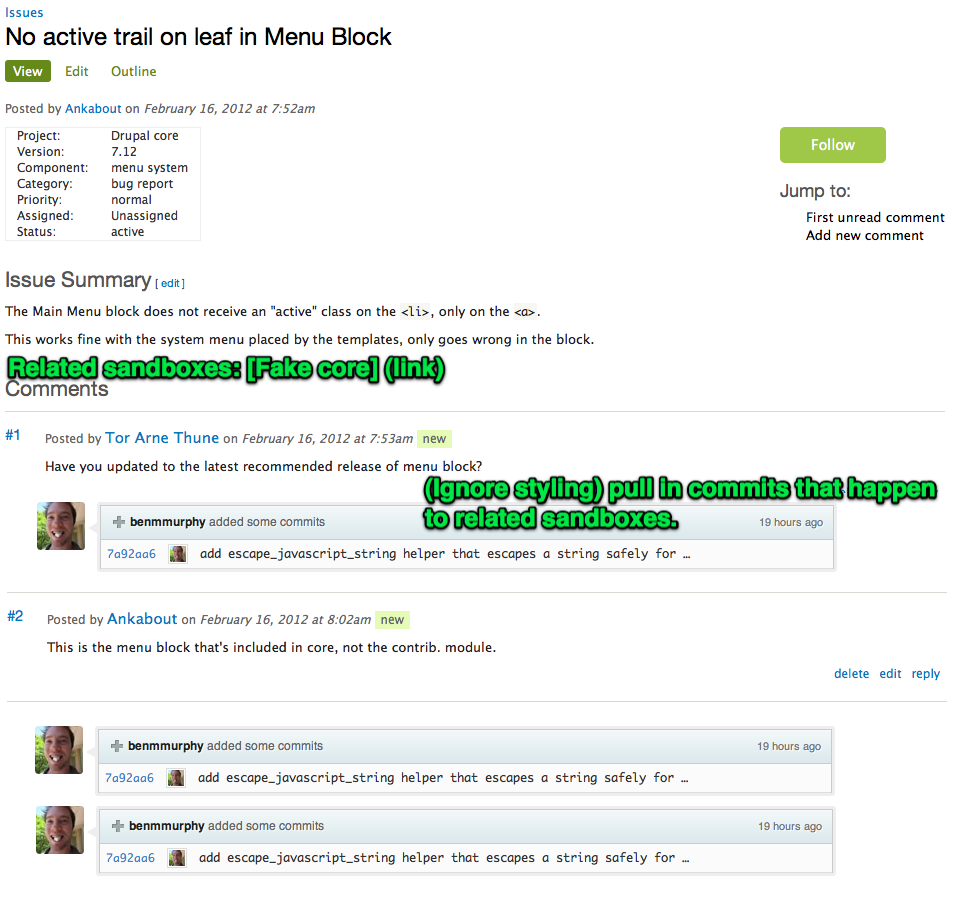
As a sandbox developer, once you get to a certain point you actually want to promote your work to the parent project's attention. This works by specifying a certain branch of code to promote to the parent project, then basically gives you a project add form, same as before. Except now, you can associate issues with one or more sandbox projects. If you do, then commits to those sandbox projects show up inline along with the comments on the issue.
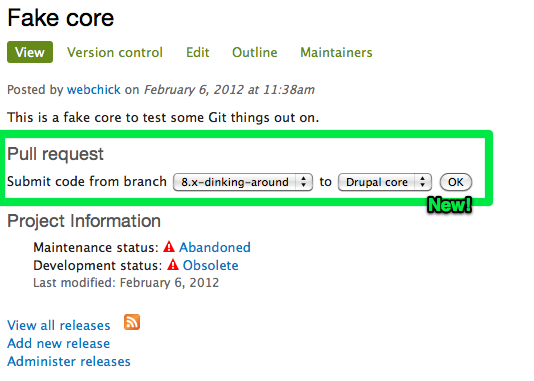
Wherefore art thou, per-issue repos?
Back when the Git work was first being specced out, we had talked about doing per-issue repositories to preserve the "swarm" effect that our community does via collaborating together on issues. However:
a) This is a completely new and untested idea, not yet proven in the wild anywhere
b) Which means it's a Drupalism, and one of the big reasons we moved to Git was so people could use standard tools
c) The sandbox method is proven by Github, and since sandboxes allow multiple maintainers, it provides for "swarming"/collaboration.
d) The biggest reason for per-issue repos is for "one spot to check", but if we pull in commits from related sandbox, that accomplishes the same thing.
That's my spiel. :) Thoughts?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #0.0
webchickx
Comment #0.1
webchickUpdated issue summary.
Comment #0.2
webchicks
Comment #1
webchickJust a note that I edited the crap out of the parent node since this issue was first posted so if someone is subscribed to email, you should probably come back and look at it again. :)
Comment #2
timmillwood+1 to github style processes
Comment #3
daften commentedThe downside with the github style process, is that for each issue you either need one code contributor.
On github there are rarely multiple committers on a project, and while in theory you can add collaborators, it rarely happens. This means that for any pull request there, while everybody can comment on it, there usually is only one person writing code.
While here, for big patches, there are numerous people who have contributed to the issue and posted updated patches with maybe only slight changes. I think a similar approach needs to be possible very easily, without having to add people as collaborators on a sandbox (which means again, only certain people can contribute) and without having users force-forking a sandbox or something similar.
I have no idea how this can be done though ATM :)
Comment #4
damienmckenna@daften: Obviously this wouldn't *replace* the patch workflow, because you can always create a patch.
Comment #5
daften commentedNo, I think it should be able to replace the workflow, otherwise the added benefit probably won't stack up against the effort required to implement this.
Comment #6
damienmckenna@daften: we're arguing semantics - of course it could replace the current workflow but there wouldn't be and shouldn't be anything stopping someone uploading a simple patch file.
Comment #7
msonnabaum commentedTHis looks great to me.
Comment #8
neclimdulyes. Yes. YES!
Nit, the "Submit code from branch" form submit button says "Ok" but I don't know what that means. Can it say "Next" or "Pull" or "Submit". We might be able to make the text clearer about where you're about to end up with something like "Create issue to pull branch <select> to <parent>"
I also see some risks around the mixed patch/commit process @daften mentioned but we've put this off for far to long and this really needs to happen. Is the next step building a project plan and break out tasks/issues or are we going to dive into implementing it?
Comment #9
tnightingale commentedThe changes proposed above sound great!
I think d.o projects would benefit from something similar to github's network graph. On the larger projects that I have worked on, I have found it to be extremely useful for getting an overview of the activity and state of concurrent branches and forks.
We may find this to be an interesting/useful reference http://gitlabhq.com. I've only skimmed over its description and demo, but it appears to essentially be a self-hosted github clone. They have their own (not so pretty) implementation of a network graph. Ironically, all their source is hosted on github.
Comment #10
sunIn the end, the last screenshot is what I desperately want, but instead of individual sandboxes, it really maps to issue-based repos/branches that can be created and worked on easily.
Comment #11
dww- This is great work sketching out the UX for how this should all look and work. Huzzah and thanks!
- I could have sworn this was already an issue somewhere, but a quick skim of the Git Phase 3 tag and the CVS to Git: Phase 3 community initiatives page isn't turning it up.
- If we're going to ramp up sandbox usage, it's time to bump #1006300: Determine data model changes necessary to accomodate the repository proliferation in phase "next". In a nutshell, that issue is about the problem that VCAPI doesn't know that the same git hash (same exact commit) in N different projects is really the same commit. This problem is going to get much worse as we make heavy use of sandboxes.
- IMHO, a giant meta issue like this is totally unwieldy for actually getting this done. Until #1300972: Implement initiative content type is done, I still think book pages under http://drupal.org/community-initiatives/drupalorg are the best way to organize bigger initiatives like this. It's worked great for http://drupal.org/community-initiatives/drupalorg/distribution-packaging for example. And this sandbox initiative is definitely going to span many issues in many different projects. So, I'd vote for just taking the issue summary here, posting it as a subpage of the Git phase 3 page, closing this issue, and getting started on fleshing out an actual plan with discrete issues in the appropriate issue queues, perhaps all of them tagged with something like "Git sandbox initiative" or something.
Thanks,
-Derek
Comment #12
dwwps Sorry, x-post with sun -- didn't see his comment until I posted mine. He raises some valid concerns. I don't have time right now to respond to them, but just wanted to say that maybe this needs more discussion (which might as well happen here) before we start the project management job of fleshing out a roadmap and distinct issues to implement all of this. ;)
Comment #13
webchickCool, thanks for the detailed reply, sun.
1. Me too. :) Yay!
2. I agree. But unfortunately, 90% of developers coming into Drupal are going to be used to this workflow, thanks to Github. Fighting against it is utterly futile. This is why I made the second view of "Show me issues from related sandboxes" so that someone like you and I could browse that queue a few times a day and spot proposals when they're still in their conceptual phases (and perhaps move them to the "proper" core queue if we feel they deserve broader input).
3. Note that that "Related sandboxes" field is just a node reference field, and could be filled in at any time. While the screenshots lay out the Github workflow, an alternate workflow is you start your discussion in the core queue, then when you feel ready to code something, you spin off a sandbox and cross-link it to the issue. Then your commits to that sandbox would show up in-line along with the discussion, same as patches do today.
4. While I got lazy since it was 3am and I was exhausted :P, and just copy/pasted the commit blurb from Github, we could easily modify that box to include whatever we want. For example, a link to the commit diff, a link to the parent repo, *and* a link to the specific branch it came from (note that this is already specified in the pull request form). No more stumbling around in amongst 30 feature branches trying to find the one that's relevant to you; it's all right there in the cross-referenced commit data.
5. That's why there's a big green "Create a sandbox" button on the sandboxes page which would automate this for you. ;)
6. Yes, exactly. It's totally intended to work with contributed projects as well. Again, these are just node reference fields, that refer projects to projects, and issues to projects. And I tried hard to work on the discoverability problems in my other screenshots. Do you have other suggestions to make this better?
I disagree with per-issue repos, as much as I was a huge advocate of them back when the Git migration began. Per-issue repos are not how the rest of the Internet works. They also mean you have to explain to every new contributor that they must clone a git repo, commit to a branch (explain what branches are), explain which branch (because there could very well be 2-4 branches within each issue repo for different approaches), talk about things like rebasing and how not to step on someone else's work, how to undo things if some other person comes in and messes up your stuff (accidentally or on purpose), etc. It raises the bar 1000-fold for "normal" day to day fixes like docs and stuff. And finally, it's utterly vaporware. Also, if you want to talk about infrastructure load, imagine instead of 0-5 sandboxes (average being probably .05 or so) per 13,000 projects, you have one repo per 500K+ issues. :(
The nice thing about sandboxes (aka "forks") is that they're not only how development on the rest of the internet works, but we already have the capability today. We could start using them right now if we could solve the discoverability problem (which I absolutely agree with), which is what I attempted to do in the other screenshots.
@daften: Sandboxes can have multiple co-maintainers added to them, just as regular projects can. So for the situation where 3-4 people are collaborating on something (say, Bartik), they just get added as co-maintainers. If someone wanted to also jump in, they could either request co-maintainer access, they could submit a patch to either the parent project or the forked repo ("Here are your changes, plus some typo fixes"), they could make their own fork off the fork and cross-link their sandbox to the issue and work in that so their changes would appear, etc. Another option might be to let sandboxes have a "global write" flag, if you honestly don't care who helps you. Not sure how hard that would be to implement.
@neclimdul: YAY! :D glad you are excited. Duly noted about the form being confusing. I kinda just pull that out of my ass based on Github screenshots. :P I would actually be *thrilled* if someone wanted to start a d.o sandbox and start hacking on this stuff, and/or break the work into tasks. I don't really have bandwidth to lead it myself right now, I just wanted to make sure to document our discussion.
@tnightngale: I personally can't make heads or tails out of the network graph, and vastly prefer the model in the last screenshot so that I can just see what's going on. :) But if you wanted to take a stab at adapting gitlab's network graph code to a Drupal module that can read Version ControlAPI's data, I know lots of people would build you a freaking statue.
Comment #14
sdboyer commentedThere's a lot here, but let me respond to at least one thing that's easy to clarify, and respond to other bits as I go:
Server-side storage space need not be a concern. There is a fairly straightforward technique - indeed, the same one that github uses (I talked with them about it in fair detail at DC Chicago) - which we can use to cluster repository objects together. With that, there basically need not ever be a duplicate object stored.
There's some additional maintenance that it would introduce into the system, but nothing that should be concerning from a load perspective. Just from a "gotta make sure we get the code right" perspective.
Doing it properly will require some nontrivial architectural work on versioncontrol_git, though. The concept of a repository "family" isn't something we represent at the moment, and we'll need to (on several levels) in order to accommodate ANY of this effectively - be it forks/sandboxes OR per-issue repos. Note that I would say that with those architectural problems solved, doing one or the other, or both, would not be very difficult.
Comment #15
sdboyer commentedThis is not a case where following "the rest of the internet" is necessarily prudent. My position on this hasn't changed - they're a good idea, because they are a better match for the social dynamics of working on Drupal than isolated forks are. Such forks work well for github and other generic platforms because they can't assume anything about the underlying social structure. So they have to go lowest-common-denominator. We don't.
Comment #16
xjmRegarding this:
How would that happen? And I think it would quickly get pretty tedious to create a separate sandbox for every issue I work on... is there some way we could instead point an issue at a specific branch in our sandboxes? Currently, most times that I edit a patch, I branch my clone of core and name the branch for the issue number. I then sometimes branch off that branch to try stuff; theoretically I could squash whatever other work back into the branch named for the issue.
Then I could just have my own 8.x-xjm sandbox that I use all the time, on all the issues, and that would give me the ability to also test the interaction between different issues very easily.
Edit: I haven't used github enough to know if this sort of thing would be too magic or not for the non-Drupal-indoctrinated. But this is for the issue process, pre-RTBC (== pre-pull-request, I think).
Comment #17
webchickYes, sorry. That's what I meant. A specific sandbox + branch. So you'd have your xjm-drupal-8 sandbox, and create branches for 121221, 2372832, 2389293, etc. (or maybe this could even be automated) Then on the node reference field form (which I guess now is a 'vcapi repo reference field' form), you'd tell it which repo/branch to get the code from.
Another idea is we could just associate commits based on "#1232323" in the commit string, from any repo that's a sub-repo of the main project. Or I guess maybe globally, actually. Huh. Then that'd track maintainers committing stuff, regardless if it came from a patch or a sandbox merge. The only problem with that idea is commits can be part of multiple repos/branches, so not sure how you'd figure out the canonical one. :\
Comment #18
sunre: #13 @webchick:
To dig deeper into one of many examples, github encourages forking and distributions, on the grounds of a base paradigm that there is no unique origin. Contrary to that, the unique origin is crucial and essential for Drupal projects. It is what makes proper maintenance of projects possible, and is an essential requirement for interdependencies between projects. You'll easily find a dozen or even hundreds of forks of an arbitrary project on github - but you really should go the extra mile and witness how poorly the "main" projects are maintained (if at all). What you'll eventually find is that there are plenty of forks, having each many branches (or even just totally unorganized commits on top of master), arbitrary and unfocused changes everywhere, entirely incompatible changes in multiple forks by different people, close to zero reviews, and potentially even a few forks that are better maintained than the original repo. This model is completely incompatible with our development process. And that's just one of many examples.
Closely mapping to the above - this is not what we want. We want Drupal developers to collaborate with each other. If everyone starts to whip up their own sandbox to work on whatever crosses their mind, without any discussion or remotely any plan of attack, this proposal will effectively turn into a queue that shows hundreds (if not even thousands) of sandboxes/branches that change arbitrary things without any sort of deliberate collaboration and discussion upfront.
Good Developers™ will even go a step further and properly use separate branches for separate things. But separate things very quickly depend on each other, but none of them maps to a carefully thought-through battle plan in any way, so any change proposal/pull request you're looking at in any sandbox can and will depend and be based on N other atomic changes in other branches of the particular sandbox. None of them maps to a central, coordinated core issue.
Speaking of dependencies, don't forget to think 3D: A branch in one user's sandbox will depend on the changes in a branch of another user's sandbox. This inherently means that the other user's sandbox [branch] has to be pulled in and also pushed to the first user's sandbox. Otherwise, you need a new sandbox that no longer forks core, but forks the the other user's sandbox instead.
Sorry, this argument is moot. In Drupal core repo vs. per-issue repos/branches vs. per-user sandboxes+branches, everyone always has to deal with remotes and branches. There's no difference at all between the different scenarios. Contributors will absolutely have to understand remotes and branches either way.
One of the underlying main ideas of per-issue repos or branches was that the repos/branches would share the history of the main project repository. I'm not familiar with all discussed details, but at least I know that branches are very very cheap in git, so you can easily have thousands of them (in one repo) without any major/serious negative impact.
--
Lastly, let me state that I already considered multiple times to create my own sandbox for Drupal core to just simply hack away on many things. However, I never did so, because each time the considerations ended in: Will the changes be compatible with other proposed changes? Who's going to review my shit, early? Who even knows of all the feature/topic branches I'm going to create in there? Am I duplicating work in existing core issues? Even worse, will some of my branches totally duplicate the work that someone else did in some other sandbox, who's equally ignoring the core issue queue? Will this be a giant waste of my time?
Comment #19
daften commenteddidn't have time to read everything, but would like to point one thing out (sry if it was mentioned before):
forks of forks and so on can become very dangerous very quickly. That workflow would indeed be a good workflow, but maybe there will need to be some "automatic cleanup" so if people fork to solve a particular issue, if the issue is solved their repo is shown as outdated and they can optionally delete it quickly.
Comment #20
webchick@daften: Yep, sandboxes are able to be deleted by the author.
@sun: I'm pretty sure I *never* said anything like "github is always right". :) I actually hate GitHub's decentralized "I'm going to fork your project and run along ahead of you, maybe occasionally leaving breadcrumbs behind that you can sift through" development model, and much prefer our community's more traditional, centralized, collaborative approach. Most of your reply is trying to explain how GitHub works to me and all of the associated cons, and believe me, I already get that.
However, the reality is this:
- GitHub is the largest code host in the world, including a number of prominent open source projects.
- It's the entry point for how 95%+ of the world learns Git, and therefore "fork, pull request, merge" is how a lot of people think Git just works.
- Their development model plays really well to the anti-social nature of many developers, who actually hate collaborating with others and just want to solve a problem with as little friction as possible.
- Working off in a corner with a small, targeted group of people is much, much easier and less soul-sucking than doing so in front of an entire community of people chewing you alive. This is a human condition, and cannot be fixed.
GitHub is not going away, it's only going to get bigger and stronger and more popular. Efforts to try and "un-GitHub" contributors coming to Drupal.org is akin to trying to make the rest of the world use US measurements. It's just not a battle I'm interested in fighting anymore. It only increases friction and dis-incentivizes people from participating here with our community. However, if per-issue repos is an itch you feel like scratching, your help certainly wouldn't be turned away.
But the fact is, whether or not per-issue repos exist... despite what you may consider to be our reality... despite how much you may fundamentally disagree with it... this splintering into sandboxes is already happening, and is not going away. There are efforts going on right now, as we speak, that you and me and catch and everyone else has no idea about. It's a natural evolution as our community growth explodes, to want to hunker down into smaller, more tightly-focused teams in order to solve tough problems, and only move to the bigger group collaboration model when there's something to show for their efforts. We might not like it, we might agree with it, but here's "our reality" for you:
That commit hash is the first commit to Drupal core. That query reports that there are currently 49 sandboxes that are forks of core. A couple of them you already know, like WSCCI and CMI, and WYSIWYG in core, because those have been widely publicized through initiative work. The others I can almost guarantee you don't, unless you stumbled across them somehow in IRC or something. They include things like Redesign modules page, Menu in core, RobotsTxt in core, block entities and on and on and on.
Again, this is happening right now. This isn't going away. It's only going to get worse as more people come into the community and the level of problems we try and solve get bigger and bigger. Efforts to stop it from happening are far more likely to stop people from contributing to Drupal altogether than bring people around to thinking that our traditional way of collaboration is better. We need to accept our real reality and deal with how best to cope with our need for visibility into these spun-off efforts, and moving those spun-off efforts back into the fold of the main, canonical project.
So this proposal attempts to reach a middle ground. It acknowledges the fact that certain people / classes of problems are going to be developed this way, regardless of what ever happens with per-issue repositories, and regardless of what rules we try and enforce on peoples' behaviours.
" Will the changes be compatible with other proposed changes? Who's going to review my shit, early? Who even knows of all the feature/topic branches I'm going to create in there? Am I duplicating work in existing core issues? Even worse, will some of my branches totally duplicate the work that someone else did in some other sandbox, who's equally ignoring the core issue queue?"
These are exactly the questions I'm proposing we answer with some subtle design tweaks. So I'd like to refocus the conversation on this reality. It's already here, and here to stay. We can embrace it, or we can put our heads in the sand and pretend it doesn't exist. As you know, the Drupal community is all about embracing (hugging ;)). So what are we going to do about it? Please post specific critiques against the proposal, or come up with a counter-proposal.
Comment #21
dww@webchick: Yay, exactly. That's precisely why my initial instinct was to think "yes, please -- full steam ahead".
Whether per-issue repo functionality migrates from vaporware into reality, it's still a Good Thing(tm) for our sandbox projects to make forking a first-class operation, where we can actually track what's the canonical project and what are the forks, so the sandboxes know their parents and so the parents can see all their forked children. That isn't necessarily going to encourage forking, it's just going to make it more valuable and useful and more likely to result in eventual merging. This was all laid out by Sam, myself, Angie and Melissa in our "Git: Phase Next -- the Promised Land" talk in DC Chicago. Full-featured sandbox forking is not the solution to all our problems. In many ways, per-issue repos are a better fit for some of our problems. Sometimes you need a unicorn, other times you need a pegasus. ;) However, given that sandboxes already exist, and given that people are using them to fork existing projects, making the forking a first-class operation that our tools are setup to handle and so we can aim to get the forks folded back in upstream when appropriate is a solution to some of our problems. That is all. ;)
Cheers,
-Derek
Comment #22
sunThe answer to all the questions I've asked myself was and is still the same: Per-issue repos/branches.
That is, because it means that the mere existence of an issue allows others to inherently know that someone is working on a certain topic. It's impossible to grep thousands of sandboxes to figure that out. But it is perfectly possible to search issues for a certain topic. It also means that your work is directly attached to the project that it is for. Discovery, resolved. Lastly, it ensures focus and prevents scope-creep in the same way issues are doing that today already.
People can still work "in the dark" in that scenario. Just like you can create issues for any project and create nonsensical patches today. But the main difference is that others can easily find your work, give it a try, and perhaps even help you to get it into the project's mainline. Second, people don't need to learn and decide between two entirely different workflows.
Your query results and analysis only underlines that. How many times was Administration menu or Wysiwyg module forked into sandboxes? How many good change proposals am I missing? How much code could I steal from those forks? How many new co-maintainers could I have for my projects already? I've no idea. And sandboxes will not resolve that, unless you go the extra mile and turn drupal.org into github.com with the entire fork and pull request workflow as well as network graphs/reports.
So why don't we spend our time to work on per-issue repos/branches instead?
Comment #23
dwwIMHO, we need both. It's not one or the other.
Furthermore, per-issue repos are a *lot* more work than adding a node reference on project nodes and some UI tweaks, which is in effect what this proposal boils down to. So, you can't argue that doing this makes it harder to do per-issue repos or that we're stealing resources from that effort. The scale of what needs to happen and who's qualified or likely to do the work are almost entirely different. You're comparing apples and oranges.
And again, even if *we* would rather everyone use per-issue repos, that doesn't mean that's what people are actually going to do. So, we need to ensure our tools can handle the reality of how people are trying to collaborate. I'm not saying we always just tail the lowest common denominator. But, in this case, there are totally legitimate reasons to fork into a sandbox and for which per-issue repos are totally inadequate (if they existed, which is not an insignificant consideration for their effectiveness). For example, some of the D8 initiatives span dozens or hundreds of issues. Trying to organize all that code into per-issue repos is completely nuts. Given that a) there are legitimate reasons to fork into sandbox projects and b) people are already forking into sandbox projects (even if for illegitimate reasons) it behooves us to make that forking actually work in a way that encourages discoverability, collaboration, and eventual merging and "reconciliation".
Comment #24
xjmPer-issue BRANCHES. Not per-issue repos. It makes a pretty big difference. ;)
Comment #25
michelleI've never used github but this is so true for me. I realize collaboration in open source is important but I really suck at it and I have to force myself to do it. I'm very much a "go off and code something" type of person. Having my own sandbox to play in but also having it visible to cut down on duplicate of effort sounds like a really good compromise. And, in the reverse, being able to tell someone who wants to help on my module to make a sandbox and link up is a whole lot less scary than saying here you go, you're a co-maintainer and can commit when you want.
Michelle
Comment #26
dww@xjm: No, the alternate proposal is about per-issue repos, not branches. There might be multiple branches in that repo for different possible solutions to the issue. And it would be completely unworkable to have a single core repo with 1000s of branches for the 1000s of issues.
The question of branches comes up here in relation to how do you "alert" a given issue in the parent project about specific work towards that issue in a branch of a sandbox project somewhere. In that case, there could be separate branches for each issue. So yeah, I guess we're not *just* talking about a noderef to point sandboxes to their parent jproject. There's also this talk of a "vcapi branch" reference field that issues can use so that sandbox maintainers can advertise their work. However, I'm not even sure that's the best solution to that particular problem. I'm more fond of #443000: When viewing an issue, display a list of commits that reference that issue # for that (and many other things) as a way to discover what commits are happening for a given issue.
Comment #27
Crell commented1) The discoverability problem is not created by sandboxes. It's created by Drupal being big. Take this very issue as an example. How the hell did anyone find out about it if they don't sit and hit refresh on the Drupal.org customizations project? This is a critically important question about our development workflow, and as an active core contributor, subsystem maintainer, and initiative owner I have a huge stake in what comes out of this discussion. But I only found out about it because I was bitching in IRC about something and msonnabaum linked me to it. I suspect "was in IRC at the right time" is how most people here found out about this issue.
A dozen Drupal core issues a day go by that I have a vested interest in and don't know about, because I don't have the hours and hours it takes to camp out on http://drupal.org/project/issues/drupal page and hit reload all day. There's just too much there, most of which I don't actually care about but some I do. As far as I'm concerned, every issue is a silo already that is unreasonably difficult to discover. Sandboxes do not make that problem worse for anyone except the 5 or so people that actually do camp out on that URL; they now get to see what the rest of us feel like every day. :-)
2) I'm hardly one to argue against following industry convention, but I think in this case Sam and Sun are correct. Encouraging a bajillion personal forks of a project the way GitHub does is not a model that works for most Drupal development. It does for larger things (WSCCI, CMI, WYSIWYG, etc.), but not for most issues. Even with all technical issues solved, doing that and then creating a hack to link those commits back to a second issue somewhere is a band-aid, not an actual solution.
3) That said, Angie's point that most people coming in will be used to the GitHub model is certainly valid, and cannot be ignored. But that doesn't mean we should mimic it exactly; it means we should make sure our model is an easy transition for someone used to GitHub. Make it *Learnable*, not *the same*.
4) Which leads me to a similar conclusion as dww: Both "higher profile sandboxes" and per-issue repos are valid use cases. For instance, I did the DBTNG PSR-0 revamp in my own sandbox, because it was too big and complex to do as a single patch that lived only on my hard drive but not multi-faceted enough to warrant its own sandbox. WSCCI, on the other hand, has no business in the main core issue queue until it reaches certain milestones, but before it gets there we want 20 hands on it (just not 200), and those hands need a way to coordinate. They *need* to silo.
So to tie the last 2 points together, yes we do need per-issue repos for the majority case, but we need to make them more obvious and familiar to someone used to GitHub. To that end, it could simply be a matter of labeling.
To wit, replace the "create new issue" button on a project with "fork a new issue". That creates a new issue node, as now, and also does the magic behind the scenes to create the lightweight per-issue repo. It's the same thing that GitHub folks are used to; "Hey this looks cool, but I want to help, *fork*". But, that new fork is namespaced by project, not by user, and has very-wide write access.
Then, in the issue, do all of the commit-showing fun that GitHub does and that the mockups in the summary do. Enable full line-by-line commenting a la GitHub pull requests. Let me work on DBTNG-PSR-0 in its own little issue, with its own repo, but one namespaced to core, not to me. That makes it easier for "let me fix this little typo for you so you don't have to" assistance to stay up to date; I had to say no to a few of those in that issue because of the disconnect between patch and repo, and it pained me to do so. :-(
When it's "RTBC", offer committers a "merge" button, just like on GitHub. That does a straight up merge from a branch they specify in the issue back to the "main" repo for that project.
That is, per-issue repos *are* the GitHub model, just namespaced differently, if we label it properly. And the different namespacing is, I agree, important to Drupal's culture.
Comment #28
daften commented@Crell: I like the idea of per-issue repositories, it might make auto-management a lot easier. Some remarks/questions from the top of my head:
Comment #29
Crell commentedRe #28:
1) Throw it open to anyone that has checked the "I agree to behave, so give me git commit access" checkbox. They'll need git anyway to push stuff; anyone who's done that already has access to push anything they want to a sandbox.
2) Not sure, but a Git repo includes all branches. So the same issue can easily house D7 and D8 versions of a change, on different branches. We can even cherrypick back and forth, making the dual versions easier to maintain than they are now.
3) Possibly. I have no strong opinion at present.
4) I defer to Sam, Derek, and our other Git Gurus to make per-issue-repos cheap. I know they've talked about black magic to make it possible, but I trust them on the details. Worst case scenario, Git can do "shallow clones" that only pulls in the most recent few commits rather than the complete history back to the dawn of time.
Comment #30
sdboyer commentedto interested folks - i'm planning on having us tackle this issue, among others, at the BoF in Denver: http://denver2012.drupal.org/bof/git-roadmap-drupalorg
so, show up and be heard :)
Comment #31
marvil07 commentedSome specific discussion about the implementation of project families on #1546660: Project families
Comment #31.0
marvil07 commenteds
Comment #32
klonos...perhaps now that we are on D7 someone with the right permissions should move this to the 7.x branch so it can get some attention.
Comment #33
Crell commentedEveryone has this permission. :-)
Comment #34
klonosI get a "Access denied - You are not authorized to access this page." message when I try to update the issue.
Comment #35
tvn commentedThat's because in order to embed images from outside of D.o, this issue's summary had Full HTML format. Not everyone has access to that one. I switched it back to Filtered HTML, but had to replace embedded images with just links to them.
Comment #36
klonos...either that or this ;)
Comment #37
joshuamiComment #38
andypostLooks that could help to get more metrics about contributors and amount of work within each issue
Comment #39
geek-merlin