Updated: Comment #191
Problem/Motivation
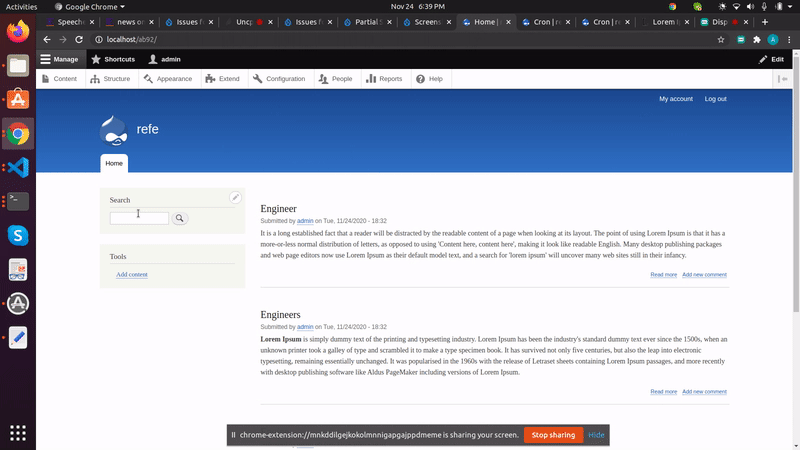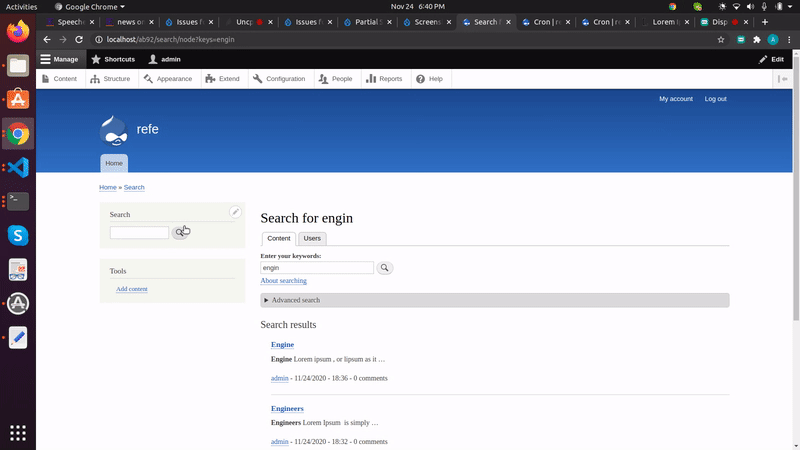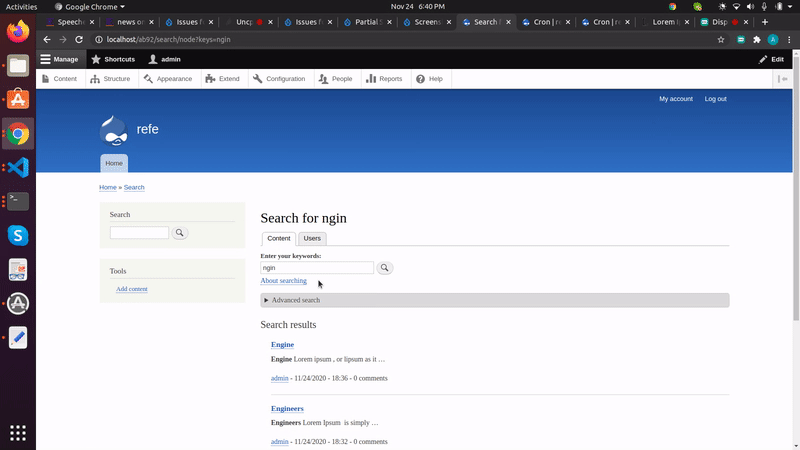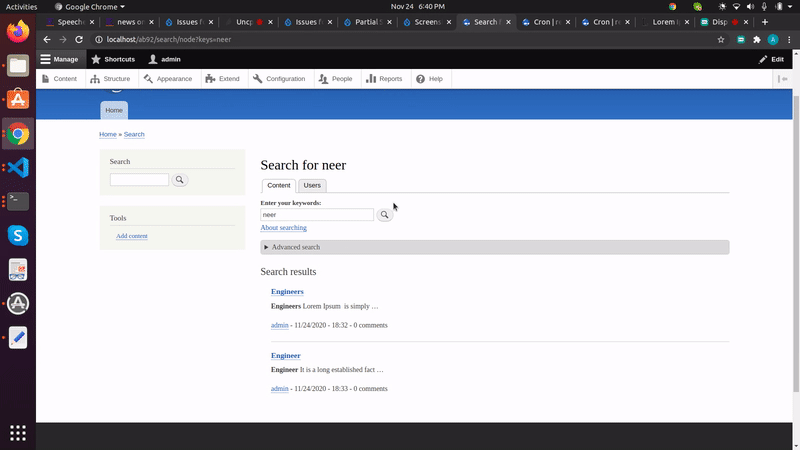
Search is working, but I noticed that it doesn't pick up on partial words. For example, if you search on 'quake' you would expect to get back results containing the term 'earthquakes' but there are no results.
This behavior is also the case with plurals: Searching on 'engineer' when a node only includes 'engineers' will not return that node in the results. It is pretty standard searching behaviour for people to omit plurals and expect to see them in results. For example, searching on 'engineer' should return:
engineers
engineering
engineer's
Proposed resolution
- Option 1. - Implement N-Gram searches, see comment #56
- Option 2. - Simple twaking of % wildcards in LIKE statements, see comment #163, where this idea brings in
Remaining tasks
- [X] - Create a simple solution with SQL wildcards and LIKE operator, without N-Grams
- [X] - Tests for the simple solution tweak on SearchQuery class
- [ ] - Tests for the simple solution tweak on search module view plugins
- [ ] - Decide if the N-Grams solution is finaly discarded or implemented via a contrib module.
- [ ] - Decide if this belongs in core or contrib, see comments #81 and #93
User interface changes
None
API changes
TBC



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
pwolanin commentedsee the porter-stemmer module
Comment #2
pwolanin commentedAlso, a "feature" of the Drupal development cycle is that new features are only considered for the latest version in development.
Comment #3
pwolanin commentedAlso, please supply patches in unified diff format, and it's considered bad form to RTBC your own patch. It needs to be reviewd by others. See: http://drupal.org/patch
Comment #4
augustd commentedPorter-Stemmer works for engineer->engineers, but not for quake->earthquake.
Attached is a unified diff of the same code.
Comment #5
pwolanin commentedI agree with you that this would be a nice feature, but the key question that will be asked by the people who might actually accept this change is the relative speed/efficiency of this query compared to the existing query.
Comment #6
RobRoy commentedThis is something I brought up a while back (in some issue I can't find) and was told that partial matching was too db-intensive. But, for 6.x I think we need to incorporate this. Most users expect partial matching to work. Sure, that's a blanket statement, but IMO it's valid. Ironically enough, I was searching for porter-stemmer module and searches for "porter stemmer", "porter", and "stemmer" all came up false for the project page. Only "porter-stemmer" brought it up. It seems we are expecting that searchers know almost exactly what they are searching for when that is main reason one searches in the first place. :)
What is a practical and feasible way to improve partial matching without sacrificing performance? Should we have an option in search settings to turn on partial-word matching?
Comment #7
spjsche commentedAnother point to note is that the search module does not perform searches within revisions.
Comment #8
jmanico commentedIt's heartbreaking that we need to wait until 6 for this basic feature that most users expect to see. Is drupal going to be a blogging engine or a enterprise ready system?
Might I suggest we roll this key feature into 4.7 but add a switch so the admin can turn this feature on-or-off if performance is a problem? Good job, augustd for bringing this up.
Comment #9
pwolanin commentedSuch a thing can be added to any version as a contributed module - take the current search module and tweak it and offer it as an alternative.
Comment #10
augustd commentedI'd like to avoid fragmenting the code base as much as possible. Besides if I was going to offer a separate search module I would rather create one to take advantage of MySQL FULLTEXT searching using MATCH ... AGAINST:
http://dev.mysql.com/doc/refman/5.0/en/fulltext-search.html
What I'm offering here is just a quick fix. How hard is it to roll this into the source tree? I can make the partial word feature an option if needed.
Comment #11
RobRoy commentedI'm pretty sure the only way it will get considered for core is if it's an option, defaulting to whole word matching. The setting could go under the Performance section. I'd say go ahead and roll a patch with a setting so it can get some reviews.
Comment #12
Steven commentedWildcard matching destroys the efficiency of the search index.
Have you asked Google when they are going to implement wildcard searching?
Comment #13
RobRoy commentedSo if we are to not enable wildcard matching (even as an option), we would need to make improvements to the indexer, correct? So we could match quake to earthquake, develop to development, etc. That's probably a pretty gnarly task, no?
Comment #14
Steven commentedNot really. All you need is a synonym list. You can solve this problem two ways:
- When searching replace a word by 'word OR synonym OR synonym'
- When indexing, replace a word by 'word synonym synonym'
The first is more exact, the second is probably faster (but does not behave well for e.g. phrase searches).
By the way, I just checked out MySQL FULLTEXT in more detail, and as far as I can tell it has no generic substring matching either.
The only thing we can do (and which MySQL FULLTEXT does) is to support wildcards of the form
foo*where the beginning is fixed. These queries still use indexes to some degree. However, the shorter the fixed string, the slower it will be.However, when I did the 4.7 search module update, I thought that such wildcards would not be very useful and better replaced by stemming. Stemming also has loads of other benefits, hence the decision was made to simplify the code and remove wildcards altogether. So far, nothing has really happened to change that decision.
Note that all of the existing search code is aimed at making word searches efficient. If you simply replace the matches by wildcard matches, the result will be incredibly slow because table indices can no longer be used. This is what the proposed patch does.
What you should do is skip the entire first pass of the search in (which was changed into a full table scan by this patch) and simply do a full table scan in the second pass in do_search(). However, then you might have trouble getting a good ranking going (as it is based on the search_index table).
Again, I doubt the usefulness of this feature. It is not easy to implement, it is slow and causes additional complications (ranking).
Comment #15
RobRoy commentedI was imagining some type of synonym list, just thought that might be intense to implement. So in terms of synonym list functionality the first option you mentioned is the way you'd want to go with this? This means a user searches for 'develop', and then we expand that to 'developer OR development OR ...'? In terms of translation, I guess we'd check any searches against the current locale's synonym table. I'm not super savvy on the translator end so maybe we could flesh that out a bit. I think this is an important improvement to the search module and would like to get some ideas rolling.
And for MySQL, if we used FULLTEXT we can get wildcard matching so we could even require at least 3 character root. Anyone comment on a comparable PGSQL solution?
@Steven, do you see both these as being core-worthy?
Comment #16
augustd commentedPostgres has a contributed module called TSearch2 that does full text searching.
Comment #17
nedjoThe contrib sql search/trip_search module uses MySQL full text indices, http://drupal.org/project/trip_search.
Comment #18
ray007 commentedsubscribing.
Partial word search is really something that should be supported nowadays.
Comment #19
Anonymous (not verified) commented+1 from me.
Please take the following into consideration as well.
There are languages (Dutch and German for example) where the English version of a phrase would be seperate words, the word in these languages would be one long single word.
For example:
The phrase "department secretary" would be in Dutch and German "departmentsecretary" (one long word).
If one would search on department in Dutch or German, the word departmentsecretary would not be found.
If one would search on secretary in Dutch or German, the word departmentsecretary would not be found.
Partial search is very much needed in these languages!!!
Comment #20
JirkaRybka commentedFeedback from east Europe: Our languages (my native Czech, but also Slovak, Polish, Russian and many more) build words on a prefix+base+suffix principle, so if going in the "synonyms list" way, we would need about 10 synonyms for almost every single word in the language! For example "Engineer", depending on gender, amount and context, may in Czech become
Inženýr Inženýra Inženýrovi Inženýre Inženýrem Inženýři Inženýrů Inženýrům Inženýry Inženýrech Inženýrka Inženýrku Inženýrce Inženýrko Inženýrkou Inženýrky Inženýrek Inženýrkám Inženýrkách Inženýrkami- and it's just one word, far from being extra complicated. Currently, the search in Drupal simply *doesn't work* in my language - the search box in fact requires to know full context where the word is used, to write a correctly-formed question. I'm even unable to find my own posts. No searching user thinks of all the possible variations. The common way across the web here is to specify basic form of the term (without pre-/suffixes), and expect all the results to show. As for synonyms list - I think it's no good: I can't imagine a translator person able to give correctly all the possible variations, and even then, special terms, colloquials and such won't work.So I strongly recommend to include partial string matching. Might be configurable to use it or not, but without this feature, Drupal's search is unusable for half the Europe, I believe.
Comment #21
puchal commentedI second that. In Polish i.e. verb "to drive" (jechać) depending on the direction and form of movement can take forms like: dojechać, przyjechać, odjechać, wyjechać, zajechać, najechać, podjechać, nadjechać etc. Also the end of the verb gets modified depending on gender, tense and quantity. Each of above forms can take shape of i.e.: przyjechał, przyjechała, przyjechało, przyjechaliśmy, przyjechaliście, przyjechali etc. etc.
There are several methods of code optimizing. One of them is "Add more RAM, faster disk and more processors" :-). I think many would cope with performance issues as long as we'd have a partial word search capability.
Comment #22
jsmithx70 commentedIs there any solution to be able to create search in 5.x of drupal.
so i can type things like this on the search box :
"george w"
and I'd like to have results like these:
"george w. bush"
"george washington"
"george wanders"
everything with the W, because right now it just does a word by word search and doesnt include the W (like with a wildcard).
It would rock
that's what I need.
I'm urgently needing it and I don't know how to do it. . . with Drupal 5.x
The porter-stemmer is not working for me as I'd like...
Comment #23
jsmithx70 commentedI'm basically using
Drupal Biblio
Drupal Biblio Facets
(Faceted Search)
and whenever I do search of biblio references with the Bibio Module, i get the righ tammount of results for a name.
And when I do search with the FAceted Search it brings less results even tho the words are there...
I'm sure im doing everything well..
What can I do to achieve great results and as I posted on the previous comment it would have to search like if it have wildcards.
I'm kinda frustrated.
Comment #24
robertdouglass commentedI've updated the title to reflect that this is a feature request. I've updated the version to reflect that no features will be added to Drupal 5 or 6.
This thread has very valuable analysis from Steven as well as important counter arguments from some non-English speakers who maintain that partial-word or wildcard searches are more valuable in Dutch/German/Polish etc.
Comment #25
Anonymous (not verified) commentedThank you.
Comment #26
Jesterw00t commentedLet me ask this question, what good is a search function if you have to know exactly what your searching for?
If i look at search terms used to find my website, 90% of them are partial word searches that resulted in something useful for the person searching.
If I have a site selling football equipment and someone types in ball, Drupal's search will come up with nothing. Doesn't make much sense from a user standpoint. It doesn't matter how "proper" or "slow" it could make code.. what matters is functionality, if a search function doesn't actually search anything but keywords, its useless.
Talk about Web .0...sheesh.
Comment #27
dwwHow about a setting to toggle if the query against the {search_index} table should be exact match or use an RLIKE? Sure, RLIKE might be too DB intensive for some sites, but for many, having better search results is more important than having performance/scalability. So, give people the choice. That'd be a healthy start, IMHO.
Comment #28
Anonymous (not verified) commented+1 for dww's comment #27
Comment #29
pwolanin commentedHmm, from the MySQL docs:
http://dev.mysql.com/doc/refman/5.0/en/string-comparison-functions.html
Comment #30
robertdouglass commentedI wonder if the example of the Czech words could be fixed by Czech stemming?
Inženýr
Inženýra
Inženýrovi
Inženýre
Inženýrem
Inženýři
Inženýrů
Inženýrům
Inženýry
Inženýrech
Inženýrka
Inženýrku
Inženýrce
Inženýrko
Inženýrkou
Inženýrky
Inženýrek
Inženýrkám
Inženýrkách
Inženýrkami
To my eye, these all have the same stem: Inženýr with one variant, Inženýř. I don't see the eastern european language argument in http://drupal.org/comment/reply/103548/479591#comment-479591 as being a compelling reason to implement wildcard searches. The earthquake argument is more compelling, but would require some sort of *foo + foo* type search which would never be fast. I think the fuzzysearch module with trigrams would be the best bet, but that module needs some algorithm love.
Comment #31
JirkaRybka commentedActually, that "Inženýr" example was just a quick one. In our languages also the begin of some words is variable - #21 applies perfectly to Czech, too. While "Dělat" may become "Přidělat", or "Dělali", but also "Přidělali" (and many more), we definitely need to search for something like *děla*, to have some usable results. Even that won't catch everything (the flexibility is quite big, we can also have "Přiděláno", and related is "Dělník"), but still it would be usable at least. I don't think we can implement Czech language rules / full dictionary, like Google seems to have, but having just partial words matching, the results will become more or less usable.
So, I support #27, unless someone come with a better choice.
Comment #32
robertdouglass commented@JirkaRybka: stemming could affect the prefix of a word, too. Please read the code here and tell me if it would handle your described cases?
http://members.unine.ch/jacques.savoy/clef/CzechStemmerLight.txt
Comment #33
JirkaRybka commentedThat code looks all fine, quite nice stuff going down the route of knowing the logic of the language, but I can't verify it's completness - I'm no language scientist, I don't know all the rules in abstract myself, there are lots of them. My impression is, that it's going to normalize (remove) the endings (suffixes) - at least the most common ones for sure. But the code doesn't seem to do anything about prefixes, and I suspect it might fail on some uncommon/atypic cases.
But most of all I'm worried about the code being Czech-specific solution. That won't work for Polish, Russian, German, whatever. This doesn't look like a solution for Drupal core then, and I'm not sure if a bunch of language-specific contribs is a way to go, to make a core module (search) usable. There's no need for other language-specific modules yet, as far as I see. That would be a lot of maintenance overhead (if someone steps out to do that), people will need to seek for contribs...
A simple, configurable *pattern* match (however slow it might be, although I'm unsure how the speed compares to the mentioned stemming code) looks to me much better, universal solution. I'm in favor of simplicity here.
Comment #34
robertdouglass commentedStemming will always be language specific. The challenge for D7 is to put the language awareness of our content to good use and make sure that stemming can be done in a language specific way. The first step is to build language specific stemmers. There are already Chinese, English and German stemmers. Please lead the effort to get Czech and Polish. The second challenge is to make the way search terms and indexed text are handled more flexible. I've already started this in the patch that makes both rely on the input format and filter system. With such a system we can switch processing based on language. http://drupal.org/node/257007
Comment #35
JirkaRybka commentedAlthough I've still a vague impression of seeing an overkill here, I must admit that this (if finished) will be a great thing to have. But my time and knowledge is way too limited to "lead the effort" to anything this size - Czech is a bit complex language. (Honestly, I'm now more or less leaving the Drupal development, for a variety of reasons.) If I can't have a simple partial- or wildcard-matching, I'll most likely disable search module and link to Google instead - don't take that as a complaint, that's just how my time-budget go.
Good luck, folks, anyway.
Edit: I've re-read that linked issue, and I want to add that it looks really very promising. But still I'm afraid that a sufficient Czech stemmer is not a trivial thing.
Comment #36
robertdouglass commented@JirkaRybka: have you tried trip_search? Doing things the right way is not overkill. We're talking about building correct tools, not about the quickest approximate way to a somewhat acceptable result.
Comment #37
dww@robertDouglass: We're talking about building correct tools, not about the quickest approximate way to a somewhat acceptable result.
That's all fine and dandy. ;) However, I don't think an optional partial word search on the index is only a "somewhat acceptable" result. For some (many?, most?) sites it would be acceptable performance, and _better_ functionality than even Google can provide. While I don't intend to jump into the "we need more flexible indexing" issues and shoot those down saying "partial searches on the index is the solution to all our problems", I also don't think it's fair to kill this issue using the reverse logic, either. I really don't see the harm in this. It can certainly default to 'off'. It'd add ~15 lines of code, and would be a great solution for many, many sites.
Comment #38
samc commentedI'd love to see partial word search available as module. One of the ways we use Drupal is as a hub for a software development community and forums are a major feature. The lack of partial word search poses serious usability problems for us when, for example, a user searches for the term "libxerces" and can not find a reference to "libxerces-c.so.2.7.0".
I don't know how the porter-stemmer module works, but if there is a way to take a similar approach to enabling partial word search, that would be great. In the meantime, I will be investigating the patch to core, which I hate to do.
If someone wants to organize a bounty for a clean solution to this problem, I'd be willing to contribute as long as it works on 5.x.
Comment #39
robertdouglass commentedOk, so the libxerces example is a case where the handling of the - is at fault. In Drupal's current indexing routine, the - is stripped and the resulting word in the index will be libxercescso270. One of the patches being worked on is repurposing the current input format and filter system to define how the text is handled during indexing. This would allow you to analyze the problem and decide that - shouldn't be replaced witn '' but rather with ' ' , at which point, your search for libxerces would work. So again, this isn't necessarily a problem that should be solved with partial word search.
Comment #40
samc commentedPoint taken. If you've got a link to that issue handy, please post.
OTOH, we'd also like a search for "xerces" to pull up the "libxerces-..." article, which does seem like a legitimate use case for partial word search.
Comment #41
robertdouglass commentedPoint taken. My proposed solution would be to extend the query builder in a way that adds an OR word LIKE '%%s%' segment to the query. To make this effective stemmers would have to stop replacing the words they stem and start duplicating them. %s in the query segment would have to be processed the same way, though. If the keyword is "matches", instead of stemming it to "match", it would have to be stemmed and added to the original with and OR, like this: "match OR matches"
Comment #42
Anonymous (not verified) commentedJust in case someone wants this for drupal 6, here's the patch adjusted for 6.2. Additionally, it highlights partial words in the snippets.
Comment #43
grn commentedHi. This patch (partial_word_search_6_2.patch 1.26 KB) worked great with Drupal 6.3 but something happened in 6.4:
# warning: call_user_func_array() [function.call-user-func-array]: First argument is expected to be a valid callback, 'search_theme_form' was given in C:\Inetpub\drupal_test\includes\form.inc on line 366.
# warning: include_once(./modules/search/search.module) [function.include-once]: failed to open stream: Permission denied in C:\Inetpub\drupal_test\includes\bootstrap.inc on line 563.
Any hints?
Comment #44
douggreen commentedMoving this back to a 7.x feature request. I agree with Steven's analysis, that doing a LIKE in the SQL here is NOT the solution we want, and will be slow.
Comment #45
lilou commentedComment #46
Anonymous (not verified) commentedI do understand all concerns raised by the developers here - in regard to not use the expensive 'like'. However, my real world view is based on the view of my customers. They want it. Period.
Thanks for this patch. It's simple, ugly and works.
Cheers,
Stephan
Comment #47
Frank Steiner commented@ #43: sounds more like you changed permission of the search.module file when patching it so you have no permission anymore to open this file.
Comment #48
grn commentedHey, I patched the file manually, it's working fine now.
Comment #49
yang_yi_cn commentedIt works. I've been using it for a while on my production site but found that there's a problem with the score factor.
Normally, search results are ordered by Drupal's search score, which uses the sum of matches. Each of the matches are weighted differently. For example, h1 has 25.
It works well when the partial word patch is not applied. However, when the partial word search is used, there are too many matches in the body, because it's much easier to get matched partially, and the result score overruns the title's score. Thus, practically, the weight system is not working.
Is there any way to improve that?
Comment #50
isidoromendez commented#42 related. (partial_word_search_6_2.patch)
Here is the patch made by Frank Steiner updated for Drupal 6.6
Comment #51
Anonymous (not verified) commentedThanks. Works for 6.8 perfectly, too.
Comment #52
timatlee commentedWorks in 6.9 too. Thanks!
Comment #53
toddwoof commentedRe: Patch in #50: This works great for partial word search using the regular site-wide search box, but appears to break other things:
(1) I added an exposed Search filter to a View, to allow people to do a key word search within the view. With this patch applied, using the exposed search filter results in the View returning several duplicate copies of records (one for each version of the word, I suppose).
(2) And, the "Distinct" setting in a View can't be set in order to fix that problem, if this patch is applied. If you set it to "Yes" the result is that the view will return no records.
Comment #54
robertdouglass commentedHave you benchmarked this patch with a non-trivial index (say 100,000 nodes or more), and a tool like the Search Bench module? http://drupal.org/project/searchbench It is important for the proponents of this patch to show that it can be done in a way that doesn't cause a serious performance regression.
Comment #55
Frank Steiner commentedHere's a problem with the partial word search:
A query like
Bart Lisawhich is equivalent toBart AND Lisais converted into sth. likeThus, the AND query becomes a mysql OR query but due to the GROUP BY and the COUNT >=2 both keywords must match, so this is an AND query.
But when you have e.g. "Bart.Simpson@..." in a page, then the search index stores "bartsimpson", too. Then with the partial word search patch a node containing "Bart" and "Bart.Simpson" will deliver two matches for
i.word like '%Bart%', because it matches "bartsimpson" too. Thus, this page would be returned even when it doesn't contain "Lisa".Thus, the partial word search doesn't allow for a reliable AND search anymore.
Comment #56
Scott Reynolds commentedThought I would point out this comment by myself: http://groups.drupal.org/node/16760#comment-57327
It implements N-Gram searching. Basically, N-Gram will break the words into N-size pieces and those will be whats added to the index. Thus standard search queries will work as is but will find partial words. The actual code to do that all the N-Gram stuff is really small, the stop words take up most of the lines of code in that example.
For example, N = 3,
It will take Bart and break it into Bar, art. And it will take Bart@simpson.com and break it into Bar, art, rt@, t@s .....
And the way search api is written, all queries will be broken into 3-grams as well. So when you search for Bart, it will really search for words in the search index matching Bar, art, thus returning bart@simpson.com
Same is true for earthquake and quake. The module works by trading off the size of the search index for query speed. Which, in my experience is acceptable. Much MUCH MUCH better then LIKE queries /me shivers. I make use of this on a couple small sites that I have deployed with strong results. Pretty elegant module, simple and small.
N-Grams are language independent as well. (Where as, stemming is very language dependent.) Though, the stop words part of that module is language dependent.
I have not tested the current patch, but I would guess that my method is far quicker on query time. But will store more data.
Comment #57
Scott Reynolds commentedSo I took my module and ported it to Drupal 7 as a patch. It does a few things to note
It needs performance review even though it doesn't change the search query at all. It changes how things are indexed. It will result in a larger search_index table.
Comment #58
Scott Reynolds commentedAs promised, here is two screen shots.
search-3-gram.jpeg is with 3-Gram setting turned on. As you can see it found dogs and dog
search-no-gram.jpeg is normal Drupal search, with Full Word Match setting.
Comment #59
Scott Reynolds commentedSo I benchmarked the query results using a traditional 3-Gram using 5000 nodes 10000 comments. First the search_index went from 12Mb to 44mb. Which is a significant increase.
The apache benchmark results (see attached) state that it essentially doubled the response time. Which isn't good considering how slow the response time is on search pages already. (See attached for detailed results).
That all being said, I am pretty sure this is the only way to accomplish this goal reliably. Its an industry standard: http://en.wikipedia.org/wiki/N-gram and it is language independent (unlike stemming).
And this patch provides the user a way to turn it off. It can have standard Drupal search implementation (Full Word Matches only).
Comment #60
Anonymous (not verified) commentedHey Scott ,
your work is great news for those currently forced to use the hacked partial word search. Any chances you could port your solution to drupal6?
Thanks,
Stephan
Comment #61
Scott Reynolds commentedDon't need a patch just a module. Here is the module I wrote that I use on sites. You can probably even install it on Drupal 5 site. No modifications needed.
See attached. It even does stop word filtering for you. So all those words in English will be ignored.
It isn't do the search_wipe() when the gram size is changed, and maybe the english isn't as clear but it works.
Comment #62
Anonymous (not verified) commentedGreat, thanks a lot. I will start testing tomorrow.
Are you planning to move this module into a Drupal Contributions CVS account? I am interested to extend your stuff to also use stop words of other languages easily...
Comment #63
Scott Reynolds commentedI won't release this on D.o cause there is a similar module out there: http://drupal.org/project/fuzzysearch
See my post here: http://drupal.org/node/413726
Comment #64
Anonymous (not verified) commentedFuzzy search is not available for D6 either ;(
Comment #65
dww@Scott Reynolds: You rock. A) Nice solution. B) Thanks for resisting the temptation to duplicate an existing module. Don't let rickauer fool you into thinking you're doing the wrong thing by your honorable and responsible position. ;) Keep up the good work, and good luck getting fuzzysearch to accept your changes. Cheers.
Comment #66
Anonymous (not verified) commentedNobody is trying to fool anybody. Nor is anybody trying to make one think in a way you interpret it. I was merely stating that none of the solutions existing yet are usable for D6. Anything else is made up by your own imagination. If you had read my comment #62 you'd have seen I also appreciate the current efforts a lot.
Comment #67
Scott Reynolds commented@rickauer: I wouldn't take dww's comment as targeting you. He meant it as encouragement. Drupal community as a whole is tired of module duplication without good reason. And I feel there isn't significant reasoning to release this a separate module.
I am really interested to hear what Blake has to say. He is a pretty smart guy and I'm sure he looked at implementing this within Search API. Wonder why he choose not too.
@dww I do hope you get a chance to review this patch. It improves the search module significantly. I wrote somewhere in a draft of a comment that this patch "it is oozing with Drupal Goodness (tm)". It really is. It is able to work with most (if not all) languages. It can be turned off and configured.
The third hunk needs to be moved down so search API modules can use the hooks properly. And its missing unit tests (yes unit tests not functional tests, wrote the ngram function purposely for unit testing)
Those are my two minor issues with this patch as it stands.
Comment #68
dww@rickauer: Indeed, sorry -- that was not at all an insult or slight directed at you -- i was trying to be funny and encourage Scott, that's all. Didn't mean to slander you in the process...
@Scott: I'll certainly try to review some day, but my Drupal time is vastly over-committed at the moment, and struggling to get changes into core is not something I have a lot of energy for right now.
Comment #69
osimax commentedI've installed this module search_gram.zip at my Drupal 6.10 site and reindexed all pages with 3-gram. The search stopped working at all - it gives me nothing found and a kind of error - something like "You should use word longer than 3 chars and not excluded" (this is rough translation to English). My site uses Russian language locale and UTF-8 encoding.
Without search_gram search is working ok but as always no partial match :(
Any suggestions what's the problem with using search_gram ?
Thanks for your reply in advance.
Comment #70
JirkaRybka commentedThe module ZIP'ed in comment #61 above have one serious problem: It uses plain php's substr() function, which is NOT multibyte (utf-8) safe. So it works fine for English (where all characters are single-byte, i.e. plain old 7-bit ASCII), but not so good (I guess) for other european languages, where some characters (also known as 'accented') consist of more bytes in the utf-8 encoding - substr is just byte-oriented, and so it breaks these characters/sequences into invalid/incomplete utf-8 codes, instead of splitting the string at character boundaries). So I think the important point here is the russian language - it's an entirely different alphabet, having ALL characters multibyte (and longer than western "accented" ones too!), so I see it probably makes quite a mess with the strings. The same applies to all other non-latin languages (arabic, hebrew, chinese, japanese etc.)
The function substr() should be replaced with something that's multibyte-safe. PHP offers the function mb_substr() for this purpose, but it's an extension not enabled by default, so that's probably not a good choice (going to fail on some sites/webhosts). I suggest trying the Drupal's own alternative drupal_substr(), which is going to be slower, but hopefully working fine, and is always available for a module (it's in Drupal core). Arguments/syntax should be the same for all these functions, but I didn't examine in-depth.
Also, please don't recategorize long-standing development issues into support requests - you're not tagging just your comment/question, you're changing the location of whole thread, lowering it's chances to get appropriate attention. The initial topic was about solving the problem in core, not about these late workarounds.
Comment #71
osimax commentedHi JirkaRybka!
First of all, sorry for recategorizing issue. It was first time I was posting reply at drupal.org , so I was not completely sure how I should treat these parameters.
Regarding issue: I have mbstring enabled at my host. I've also noticed that strlen function should be replaced with mb_strlen . There is also such line of code as
$terms = preg_split('/([^a-zA-Z]+)/', str_replace("'", '', $text), -1, PREG_SPLIT_NO_EMPTY );I have replaced it with
$terms = mb_split('/([^a-zA-Zа-яА-Я]+)/', str_replace("'", '', $text), -1 );Now it looks like search is working fine . The only concern is that mb_split is omitting PREG_SPLIT_NO_EMPTY ... so a lot empty strings will be in result, right? How to solve this?
I am not PHP developer, but advanced user, and not very strong with regular expressions and multibyte charsets. If somebody can help me to resolve this last (and I think simple) question I will appreciate very much.
I've used SQL Search module with Drupal 5 and it worked ok. Still don't understand why it is not supported anymore ...
Comment #72
Scott Reynolds commentedawesome thanks for the review. I concur, need to use drupal_substr(). Interesting bit on preg_split. Anyone have any insights on that with other languages ?
I won't be updating the drupal 6 zip file. Just something i just put together and I carry in my toolkit.
Comment #73
JirkaRybka commentedI didn't really analyze the code, I only just spotted an obvious problem on quick read. #71 mentions more places to replace functions with their multibyte-safe counterparts, that's obviously good direction too. As for the regular expression, apart from the multibyte-safe issue (solved by mb_split(), if available), I see a problem in the list of character ranges 'a-zA-Z' being insufficient for many languages. osimax added ranges for russian alphabet, but there is more around the planet... So I would suggest to search for some character-classes stuff (either in the regex, or other php extensions), where you can specify characters by groups like "letters", "numbers", "punctuation" etc.
Just a quick comment, otherwise I have no time to really work on this, let alone solving it for core (if that's going to be even accepted, which I doubt after the above long discussion - it's a pity how de-motivating feel the Drupal community often give). An extra module, if that's the way to go, should really get an own project, or be merged with another, or posted to some kind of own thread, IMO. Just thinking out loud.
Comment #74
Scott Reynolds commentedOk updated the patch with changes mentioned.
1.) use drupal* functions so its multi byte compliant.
2.) move the N-Graming down in the process so as to allow modules to preprocess the whole word text not the n-grammed
3.) Fix highlighting. It appeared to work by chance. this change works for English Im sure. other languages, needs that tested. It uses the [\w] regex character which might not work with other languages?
See screenshot with working highlighting.
Comment #75
JirkaRybka commentedGreat, I'm going to test on Czech site, but unfortunately my *very* limited time of these days is not really promising, as for my review coming soon. Other reviewers welcome, as always ;-)
On quick read, I see two hunks in the patch just removing blank lines somewhere - that's most probably a leftover from previous edits, and might as well be removed from the patch. As for the regex part, now I see there's already the 'u' modifier at the end of pattern, so it should work for UTF-8; I'm only unsure about '\w' vs. UTF-8 specific '\pL' (plus '\pN' and perhaps more) as mentioned here, but I'm rather new to this sort of thing and didn't test yet, so don't take me too seriously :)
Great to see progress here, really.
Comment #76
Scott Reynolds commentedso interesting tid-bit though i think it actually failed to answer my question
"A "word" character is any letter or digit or the underscore character, that is, any character which can be part of a Perl "word". The definition of letters and digits is controlled by PCRE's character tables, and may vary if locale-specific matching is taking place. For example, in the "fr" (French) locale, some character codes greater than 128 are used for accented letters, and these are matched by \w."
And looking at this comment http://www.php.net/manual/en/reference.pcre.pattern.syntax.php#54830 it appears that \w will capture locale specific stuff.
but it mentions that "traditional escape sequences such as \d and \w do not use Unicode properties in PCRE" so I don't know anymore :-D. Just needs someone to review to tell me if it needs work
Comment #77
cburschkaPartial word matching sounds very, very cool. But even on reading the patch very thoroughly, I was unable to understand how the final matching works.
Does it break search terms into N-Grams as well? If so, will we get "heartburn" when searching for "earthquake" on a four character index?
Or does it only match full search terms? In which case we miss out "earthquake" if we search for "quake", because earthquake is only broken into "eart", "arth", "rthq", "thqu", "hqua", "quak" and "uake", and "quake" isn't in there at all?
Either of these would be a show-stopper, and I'm not sure how you avoid both of them.
Comment #78
JirkaRybka commentedI didn't have time to review and test so far, but I'm under impression that if we break both indexed contents and searched terms into the grams, then we get on a 4-characters index :
'Earthquake' => eart + arth + rthq + thqu + hqua + quak + uake
'Hearthburn' => hear + eart + arth + rthb + thbu + burn
Searching for 'Earthquake' (=> eart + arth + rthq + thqu + hqua + quak + uake):
'Earthquake': 7 matches out of 7 possible, relevant search result
'Hearthburn': 2 matches out of 7, not much relevant, falling to the bottom of search results
Searching for 'Quake' (=> quak + uake):
'Earthquake': 2 matches out of 2, relevant result (as oposed to current core bahavior, where we get NO result at all)
'Heartburn': 0 matches out of 2, no result
Searching for 'Heart' (=> hear + eart):
'Earthquake': 1 match out of 2, not much relevant result
'Heartburn': 2 matches out of 2, relevant result
We might as well check the score, to remove results where - say - less than 50%, less than 2/3 or so matches.
I don't really know how the current patch works yet, just thinking out loud.
EDIT: Now I realize, that we most probably want to just use the AND logic, so that all the subparts of search term must match. (I don't know how that plays with the AND/OR logic of search terms, nor whether we want to do something about the grams needing to be in a row rather than randomly around the content item, but this is too deep water given that I didn't really test the patch yet, so I'm not saying any conclusions. BTW testing might be tricky for me, as my localhost environment is not able to install D7 due to php/MySQL versions being kept in sync with my production site due to other testing).
Comment #79
cburschkaThank you for the clarification. Of course with a scored ranking all this makes more sense.
There are still some pitfalls if each N-Gram is treated as a separate match rather than calculating a matching score for each keyword, because many badly scored keywords could eclipse a few well-scoring ones.
For example, in a three character index, a post that contains "heartburn", "hearing" and "near" could score more highly than a post containing "earthquake" when searching for "earth":
Comment #80
JirkaRybka commentedQuite right. I was also adding a P.S. to #78 (not expecting you to reply so fast), with more thoughts. But as I said there, I didn't really find the time to test this, or think through properly, so I can't go to further discussion until I do that. My apologies.
Comment #81
pwolanin commentedGiven the possibly serious performance implications of doing this (a ballooning of the index size, for example) it seems like it might be better to provide the hook (if absent) so that this can be implemented in contrib?
Comment #82
JirkaRybka commentedIt's debatable of course, but from my (non-English based) point of view, the core search module is broken horribly (being unable to find even very basic things, such as my own post I forgot URL for, despite throwing 10 different searches), and if I were a user not knowing about this issue, I certainly won't think this was something to be fixed by a contrib module rather than filing a bug report against core. Just thinking out loud, it's a question of the borders between bug report / feature request / additional functionality[module], really. It might be an usabilty issue, too. The performance implications are a little discussed above (i.e. making this optional, the patch have a setting for that - many sites are not that large / searched that often).
But anyway, none of the proposed solutions here were my ideas, I'm only just highly supportive to this functionality, since I see it as one of very major, long-standing problems of Drupal. I voiced my support already, so no need to rant further ;-)
Comment #83
Scott Reynolds commentedOk as the patch writer a few comments:
Before commenting please note: this setting is optional. It can be turned on and turned off. If this setting is giving your site performance issues, turn it off as suggested by dww in comment 27. I know people get wrapped up in talking about performance, without realizing that all this does is provide an option to do N-Gram searching.
The assertions about how n-gram searching works is accurate. But afraid your over thinking this a bit. If a user just searched quake, the top result appears to be the only post on earthquake. Heartburn was returned but ranked lower. This is the situation that Fuzzy Search handles by adding a minimum score parameter therefore, removing things with low match rate. This is doable, but requires us to use temp tables, I think. I believe that would be the only way to achieve this with cross-db. Temp tables are slow, and purposely removed from core search in D6.
And truthfully, I do not believe its that a big of an issue. The purpose of this technique is to broader the search results. And in your very limited 2 content (with each piece of content having exactly one word) it still did just that for you. I would encourage you to do a checkout of HEAD, use http://drupal.org/project/devel to create a bunch of content and test it out.
Re: hook and a module for contrib:
See comment #61: http://drupal.org/node/103548#comment-1388532. The hooks required for this are already there.
What would need to change is the snippet Regex (as the original Regex expects a whole word match. In the latest patch, the new regex is there).
This is the hook: http://api.drupal.org/api/function/hook_search_preprocess/7
Comment #84
chx commentedThat's a bit ironic, people hacking search module and askin' Unicode support. preg optionally supports Unicode. Steven had the wisdom to not rely on that instead extracted the relevant classes into nice preg defines on top of search module. Use them.
Comment #85
Scott Reynolds commentedI use all those preg defines. What the question surrounds is the following problem
I searched for "dog", and it return a result with the word "doggie". I want to highlight "doggie". The current Regex, expects the matched word (in this case "dog") to start and end as a complete 'word'. So what was added so that we can achieve what we want is a lil change
That allows us to match around punctuation, brackets and the whole slew of unindexable characters.
What I think needs to be changed is instead of using [\w]* it should be [\p{L}]*. Which says "has property letter".
http://www.pcre.org/pcre.txt
Comment #86
Scott Reynolds commentedso basically, need to define a new PREG_CLASS that matches all "L" characters. And we then need to update regex to match the N character classes (with the use of the puncation class as well) and the "L" character classes.
unicode provides code charts for this: http://unicode.org/charts/
Comment #87
robertdouglass commentedI smell a core patch for the L classes.
Comment #88
Scott Reynolds commentedHere is the updated patch. chx comment #84 was right on the money, not sure why I didn't leverage it the right way before. The index contains more then L
* Lu Letter, Uppercase
* Ll Letter, Lowercase
* Lt Letter, Titlecase
* Lo Letter, Other
* Nd Number, Decimal Digit
* No Number, Other
So, instead why don't we say [^SEARCH_EXCLUDE]*. So thats the improvement in this patch
Comment #89
Scott Reynolds commentedOk so there was a coding style error and a bad if statement in the Validate function. This patch fixes that. It is now ready for another review.
Something to think about.
Should we not allow users to choose the gram size and just set the gram size equal to the minimum word length?
Then that would allow users to select a radio, full word matches or partial word matches. That better and less confusing then current options?
Comment #91
Scott Reynolds commentedRe-roll. Surprise it didn't apply last time. It worked with
Comment #93
jhodgdonI am not in favor of this being added to core as an option. I think it should remain as a contributed module, as I think it is now for Drupal 6.
The reason I think this is that for some sites in some langauges, stemming modules are a better option for improving search results than n-grams (more efficient, linguistics-based so no false matches, etc.). It would be helpful if Drupal's documentation made it more clear that the core Search module is doing exact word matching only (people's search expectations are keyed to Google, which doesn't have that restriction), and perhaps if the search module's set-up page or help page suggested that people check out stemming and n-gram modules as methods for changing this behavior. But I don't think Drupal core should be endorsing the n-gram approach, when it isn't necessarily the best approach for all sites and all languages.
Comment #94
amc commentedtagging
Comment #95
dwwIf the criteria for a feature being in core is that it's the "best approach for all sites and all languages", Drupal is doomed. Almost nothing satisfies that criteria...
Comment #96
dww(Sorry, cross-post)
Comment #97
jhodgdonWell, how about at least making sure the help screens for Search in core make it clear that search is exact keywords and there are two approaches (at least) for changing that behavior?
Comment #98
dww@jhodgdon: Sounds like a fine idea, but a separate feature request. Prepare yourself for a 100 comment "usability" bikeshed issue, though. ;) Please don't start that here. This is an issue for adding a working, helpful addition to core search functionality that could benefit many (definitely not all) sites. Thanks.
Comment #99
jhodgdonOK. I'll review the help screens and see what I can do/suggest. :)
Comment #100
dww@jhodgdon: Cool. Please add a link here to your new issue once you've submitted something, so any interested parties from here can join in the fun. ;)
Comment #101
jhodgdonFor anyone that is interested, I've just added (with a patch to the Search module's help text): #546302: Help screen for Search module doesn't make limitations clear
If this issue gets committed to core, that patch will need a revision.
Comment #102
catchMoving to Drupal 8.
Comment #105
Balbo commentedI'm not sure I understand what is going on here. Is this the patch I have to apply if I want to provide my drupal-site with partial words search? Why is the status ignored?
Comment #106
jhodgdonBalbo: This issue is now bumped up to Drupal 8, as it is too late for feature changes to Drupal 7. The testing bot is ignoring the patch because it is not a Drupal 7 patch.
As to applying the patch, are you running Drupal 7? If so, the above patch might work for you. If you are running Drupal 6, unlikely.
Comment #107
roberto.scaccaglia commentedWaiting for Drupal 8 i have changed, based on some posts above, five lines of code of search.module (by Drupal 6.15 version) and now
i can search partial words and highlight the search key in strong style. I have tested the cahnges on few contents but
they seem to work (waiting for something more efficient and sophisticated). I have attached a file text with the changes.
Comment #108
jhodgdonSorry, but feature requests are not accepted for Drupal 6 any more. Feature requests are also past time for Drupal 7. We are only considering feature requests for Drupal 8 at this time.
Comment #109
sepla commentedDirections in #107 has been successfully tested against D6.15 & here is the patch.
As others reported the patch is also working with 6.16 to 6.20 releases.
Comment #110
jhodgdonSee comment #106 above...
Maybe someone could make this into a contributed module for Drupal 6, so that people wouldn't have to patch the core files of Drupal 6 to get this functionality?
Comment #111
Anonymous (not verified) commentedI've updated the patch made by Sepehr Lajevardi (see comment #109) in order to have partial search in drupal v6.16.
EDIT: ups... it must be applied within the search module folder "/modules/search"...
Comment #112
Grayside commentedFor thread completeness: Fuzzy Search already exists and has a new active maintainer in the last few weeks.
Comment #113
daniel wentsch commented@SumyTheSlayer (#111) you made my day. Thanks a lot :)
Also works within views search filter (which Fuzzy Search does not, unfortunately).
Comment #114
tomsm commentedDoes this patch also work for 6.17?
PS: A contributed module is a great idea.
I just applied the patch to 6.17. Works great. Thanks!
This is very useful, especially with Dutch language that contains many combined words.
Is it possible to show exact word results first followed by the partly results?
Comment #115
naveen123456 commentedyes it really works (comment number 48 - partial_word_search_6_2.patch)thanks. you just need to replace two liens-
$query2 = substr(str_repeat("i.word = '%s' OR ", count($arguments2)), 0, -4);
TO This
+ $query2 = substr(str_repeat("i.word like '%%%s%%' OR ", count($arguments2)), 0, -4);
and
- $boundary = '(?:(?<=['. PREG_CLASS_SEARCH_EXCLUDE . PREG_CLASS_CJK .'])|(?=['. PREG_CLASS_SEARCH_EXCLUDE . PREG_CLASS_CJK .']))';
TO THIS
+ $boundary = '';
Comment #116
Sadi commentedsearch.module_9.patch queued for re-testing.
Comment #117
danny englanderSubscribing
Comment #118
Scott Reynolds commented- myself
Comment #119
houdelou commentedPatch at #109 is working with 6.19. Thank you very much for this patch.
Comment #120
henrijs.seso commentedPatch at #109 is working, I just wonder how to get that partial word to highlight
Comment #121
jhodgdonHighlighting words with preprocessing is a separate issue. Specifically:
#493270: search_excerpt() doesn't work well with stemming
#916086: search_excerpt() doesn't highlight words that are matched via search_simplify()
Comment #122
henrijs.seso commentedThanks for tips jhodgdon
I went with jQuery + updated version + code in comments to take value from search field and highlight results. http://johannburkard.de/blog/programming/javascript/highlight-javascript...
Comment #123
krupsonline4u@gmail.com commented#4: search.module_10.patch queued for re-testing.
Comment #125
cptX commentedHi to all, I tried patch 6.15 from #109 but it didn't work in drupal 6.19. Any ideas why?
For example, I have a very large word alskdjlfkasdjlfkaskf and I get a part of it lets say "djlfk". This is found correctly. Then if I change a single letter let's say "djkfk" the search can't find it. Please advise...
Comment #126
jhodgdonDid you run cron to index your changed page?
Comment #127
cptX commentedYes, of course!
Comment #128
frankie commentedWhat about D7?
Comment #129
guyFawkes-2 commented#4: search.module_10.patch queued for re-testing.
Comment #130
frobsubscribing
Comment #131
pwolanin commentedPer discussion with jhodgdon, this is not appropriate for core at this point, so please do it in contrib, or look at non-SQL search engines that already provide this.
Comment #132
govind.maloo commentedsearch.module_9.patch queued for re-testing.
Comment #133
pwolanin commented"won't fix"
Comment #134
govind.maloo commentedokay i'll try something else
Comment #135
daniel wentsch commentedConfirming search.module-6.16.patch from #111 working on 6.24
Comment #136
tyb commented#111: search.module-6.16.patch queued for re-testing.
Comment #138
clemens.tolboom[Stock response from Dreditor templates and macros.]
This issue was resolved and/or closed before.
It is considered impolite to the developers to continue discussion as they are notified on fixed work.
If you think there is value for the current discussion best thing to do is to create a new issue to get the attention your discussion deserves.
Comment #139
mxmilkiib commentedComment #140
wsherliker commentedNot sure if anyone is still interested in this but I updated the patch to search.module-6.26.patch as attached. Seems to work for us.
Comment #141
Jenechka commentedSame patch for Drupal 6 search module. But now you can control search condition by implementing a hook in your module.
Comment #142
ianthomas_ukComment #143
janis_lv commentedI'm sorry, but witch patch to use for d7 search?
Comment #144
jhodgdonMaybe comment #91? I'm not sure. You might also check out https://drupal.org/project/fuzzysearch
Comment #145
janis_lv commentedfuzzy search is broken on d7, won't install :[
Comment #146
floatingpointmatt commentedIs n-gram searching scheduled for release in D8?
Will it be backported to D7?
I may be missing something here, but it seems like this "issue" is still in limbo.
I understand the arguments against pushing into core, re: scope of search functionality (search can be a specialized need, how do you please everybody) and the obvious potential for performance issues; however, isn't it a little embarrassing that something hasn't been included after 8 years of discussion?
As a content management system, can Drupal afford to offload what is arguably a crucial user experience concern (which is heavily related to content management)?
Shouldn't this be an "out of the box" expectation?
I'd settle for an option to change the search style from "matches" to "contains" in admin/config/search/settings with a good faith disclaimer that the change could impair performance.
(NOTE: I realize that's an oversimplification; however...)
Not to trot out unrelated comparisons, but WordPress (circa 3.7 - Oct. 2013) realized they had search issues and rewrote their search functionality to better support end users. Since that project is similarly core + plugin/module driven, does this not further the notion that search is a core issue?
(Putting aside WordPress, I'm having difficulty thinking of another search that forces an exact match at the moment...)
I realize that Solr, Search API, Porter-Stemmer, Fuzzy Search (only considered production ready for D6), and other alternatives exist. I'm just in favour of having something a little stronger (and with fewer dependencies) available.
I wish I could support this stance with a "here's the code," but I'm not there yet...
Comment #147
jhodgdonIf you want to have N-Gram searches, I believe there is a contributed module that you can add to Drupal to do this in Drupal 6 or 7. If that module is broken, you may make an issue with the developers of that module.
Drupal Core has never been the only thing you need to build a site -- you'll always need add-on modules. Most larger sites will not use the Drupal Core search module -- they'll be using Solr or something like that -- but we can't add Solr to Core, since it requires more than a generic PHP/MySQL server to run. And we're not going to be adding something like Porter Stemmer that only works for English to Core -- that is definitely add-on territory since it is specific to one language, and as noted in comments above, it is probably a better alternative than N-gram.
I'm not actually convinced that N-gram is a very good alternative at all... maybe someone could research search technology alternatives and make a better argument than "this kind of works" to say why we should adopt it and incur the database size problems?
Comment #148
floatingpointmatt commentedThanks @jhodgdon for clarifying. I'll have another look for N-Gram searches.
I agree that search is complex (especially regarding appropriate handling in multilingual situations); however, despite understanding that, it still boils down to getting different search results when doing simple searches like:
apple vs. apples
I can explain until the cows come home to the folks I'm supporting that it's not an exact match, so they're missing results, but that's not user-friendly, or expected. People are used to Google, Bing, Yahoo, word processing software, spreadsheets, text editors and a multitude of other software that tells them to expect partial matches.
With a key feature like search, which supports weighting based on HTML markup, taxonomy, etc. and an advanced feature to let me filter by content types and to perform other filtering/criteria refinements, but that doesn't cover a fairly common use case feels unnecessarily detrimental to Drupal adoption.
I understand Drupal provides a stable base for customized builds, and that third party product integration (like Solr) would rarely (if ever) be added to the core (even if it didn't carry significant dependencies) -- but in this case, I'd make the argument that the core should solve common problems and this qualifies.
I'm presently at a spot where the core search (with N-gram) would do exactly what I need done (which is to serve as an anchor for some deeper auto-complete functionality), but I'm now trying to figure out what I can use (Porter-Stemmer tinkers with search_index values and still leaves gaps, Search API doesn't inherently honour permissions, Solr is super heavyweight for what I want to do, etc.).
I don't expect to shift things (after all the discussion to date), but I wanted to at least offer up my vote for a review of core search functionality.
As a final note, I do want to recognize the work to date on the core search functionality. There has obviously been a lot of thought that has gone into the implementation. I have not been privy to all the groundwork to get to this point, and it's true that core + contrib will get most things done.
Anyhow, that's my $0.02...
Comment #149
jhodgdonYou've made your point. :) Really, I do understand. But expecting Core to do everything is not realistic either, and having to install another module you download from Drupal.org is not considered a bug.
In any case, I don't think we necessarily need to have this be "postponed". If someone wants to make a viable patch for Drupal 8, I think we'd at least review it.
Comment #150
jhodgdonSince 8.0.x-beta1 has been released, our policy at this point is No feature requests until 8.1.x. See #2350615: [policy, no patch] What changes can be accepted during the Drupal 8 beta phase?. Sorry, it's just too late for 8.0.x at this point, so even if we had a viable patch, the core committers would not commit it. So unless we decide this is a Task or a Bug (and I don't think it is), we'll have to delay it.
Comment #151
izmeez commentedIssue #498752: Partial word search for Drupal 7 was previously closed as a duplicate.
It is a different and less complex approach. It is certainly related to this issue and has now been tagged as such.
However, that issue should remain active as a feature request for a 8.1.x-dev so that both approaches can be considered.
This issue is also being tagged as related to the other issue.
Comment #156
VBN commentedWhy oh why is this not implemented yet...?
It's a big thing in my pov that leaves a feature request for years now and has no alternative as a module form...
Comment #158
anybodyThis issue is for smaller sites where search_api / Solr / Elastic / ... is just too big. And it makes sense (from my point of view) to have a better solution than the current full-word search only.
I agree with #156. The core search is quite powerless without partial word search. It lacks a partial / ngram feature since Drupal 6, which is really essential for a functional search. At least there should be an option to enable partial word search for smaller sites if it's too much for larger sites or the page owner decides a full word search is enough / required.
Could we please discuss & decide if:
to make further development in this issue possible and fix this long waiting issue finally?
This issue could be a good solution for Drupal 8 while we could fix #498752: Partial word search for Drupal 7 for Drupal 7 with the result of the discussion the same way.
Any core maintainers who may leave a comment?
Comment #161
tostinni commentedFor those looking to solve this issue with core search, the Porter-Stemmer module is restricted to English and was not working as expected in my case.
However I found that the snowball stemmer module will greatly enhance core search, it will allow "partial" words search based on roots of words.
So yes search on 'engineer' will return all those : engineers, engineering, engineer's but won't find earthquake if you search for quake.
It will also help find plural words when looking for singular.
You can also try its algorithm here : https://snowballstem.org/demo.html
Comment #163
devad commentedJust in case somebody will need, here is partial word search core hack for current Drupal 8.8.x-dev and 8.9.x-dev.
The patch implements partial word search inside D8 Core views search filter also.
Similar core hack for D7:
#498752-41: Partial word search for Drupal 7
Hack for D7 Views filter partial search:
#1480594-5: Filter Search Terms partial matching
Comment #165
devad commentedJust an update... patch #163 applies cleanly to latest D8.9.7 and D9.0.7 as well.
If you want to use this patch (or any other core patch) with composer here is the "how to" guide:
https://groups.drupal.org/node/518975
Comment #167
NitinLama commentedUpdated patch as per #163 for 9.2.x-dev. And it's working fine.
Attaching ss.
Comment #168
NitinLama commentedComment #169
devad commentedHi @NitinLama. Thnx for D9.2.x patch.
BTW, not a big deal, but the interdiff_163_167.txt is wrong - you have just uploaded a new patch as interdiff also.
Comment #170
abhijith s commentedApplied patch #167 on 9.2x and it works fine.The partial search feature is working fine.Adding recordings below
Before patch:
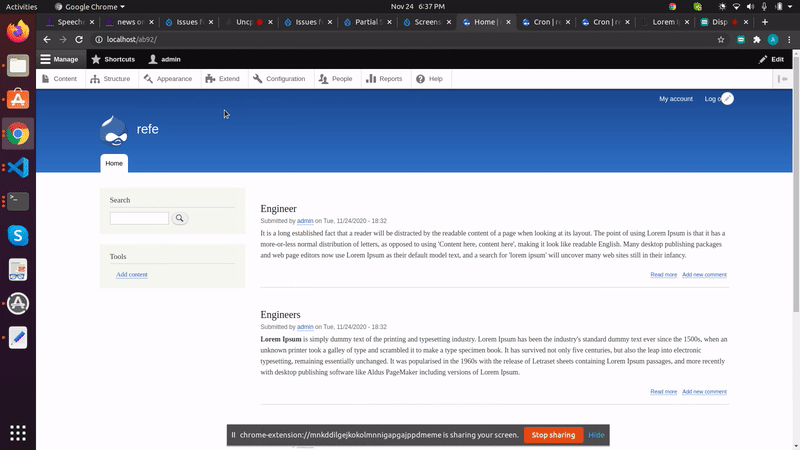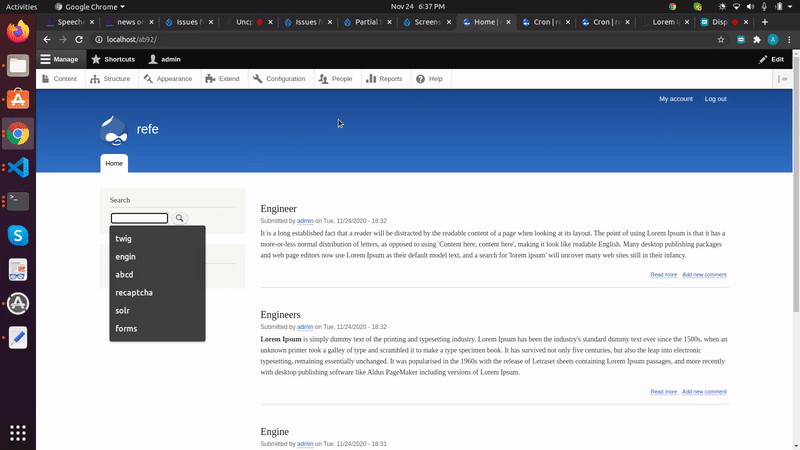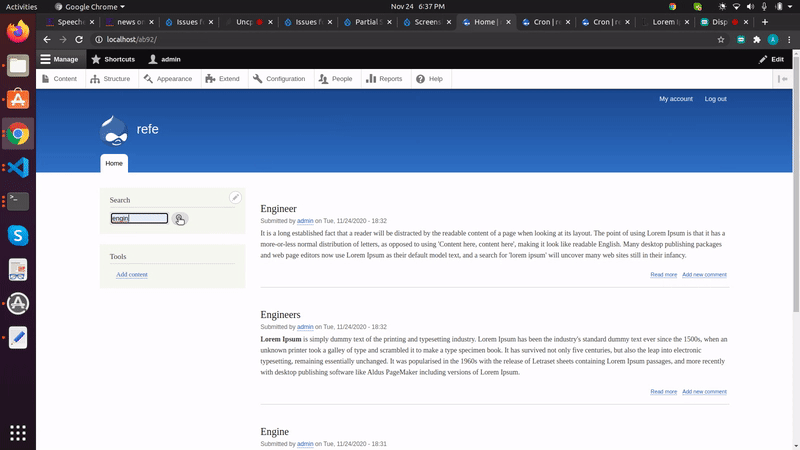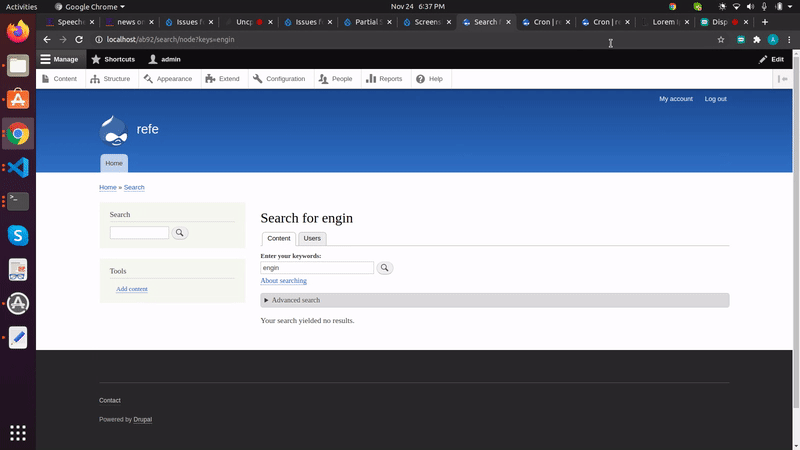
After patch:
Comment #171
abhijith s commentedComment #172
alexpottThis issue definitely needs test coverage if it is to go forward. It also needs a change record to outline the behaviour change.
I wonder if @jhodgdon still feels the same way as #147 and that this shouldn't be part of core search. I'm going to add the needs product manager review tag because I think that decisions like this belong there.
I do agree with @jhodgdon that if you can achieve this by installing search_api and the snowball stemmer module then maybe this is best left in contrib.
Comment #173
devad commentedFor English only sites this feature may not look so essential. However, for all slavic languages this feature is must-have because search by whole world is completely useless.
These are some variations of "drupal" in Croatian language:
drupal, drupala, drupalu, drupale, drupalom, drupalovi, drupalovog, drupalove... and the list is much bigger.
Search API is an overkill for small sites.
"Partial search" checkbox in core Search module settings would be great. And it can stay unchecked by default for BC reasons of course.
If this feature would be hard to implement my vote would go against it. But the logic needed is already here and it works. One more checkbox in settings and some tests are needed of course.
Comment #175
robert_ws commentedApplied patch #167 but it didn't work as expected - I got matches for my partial search that did not have any matches to my query
Comment #177
aaroncompubase commentedPatch #167 did work for me with Drupal 9.2.x. After the upgrade to Drupal 9.3.0 the patch couldn't be applied anymore because of the changed line numbers. I've re-created the patch #167 for 9.3.0.
Comment #178
devad commentedComment #179
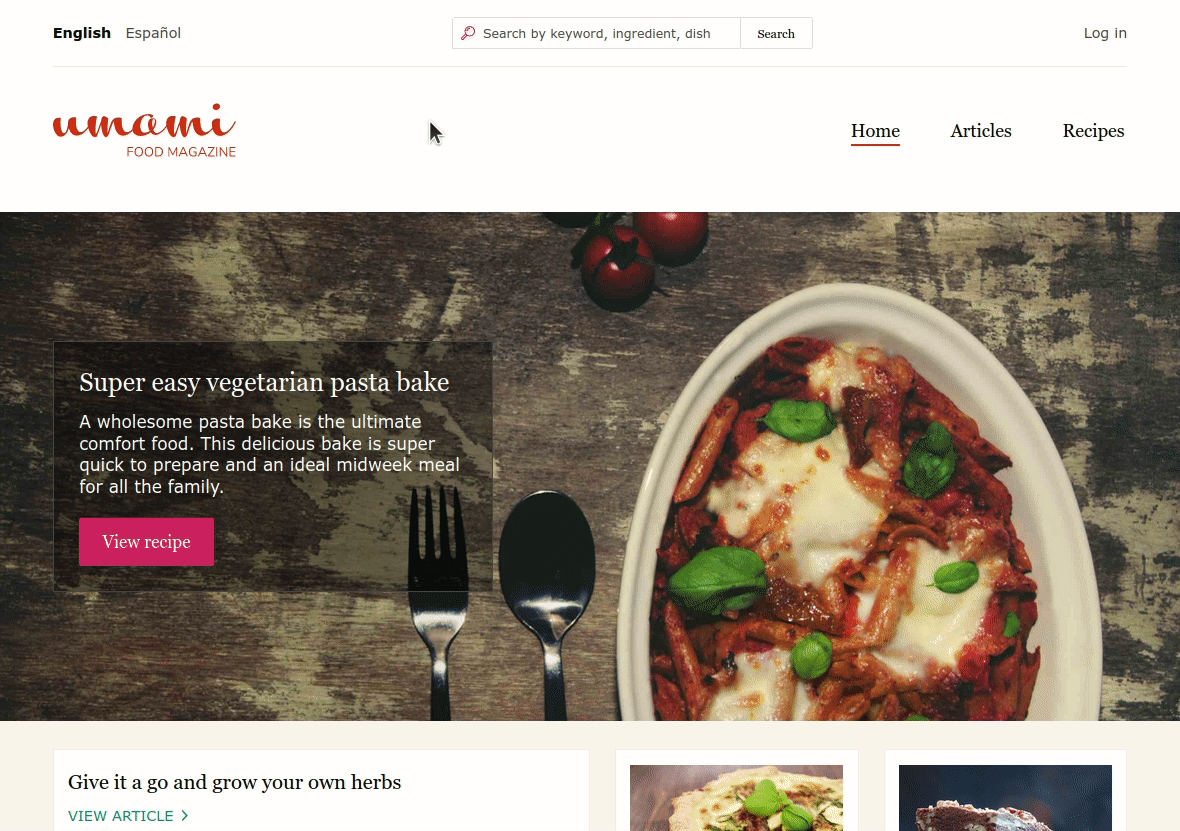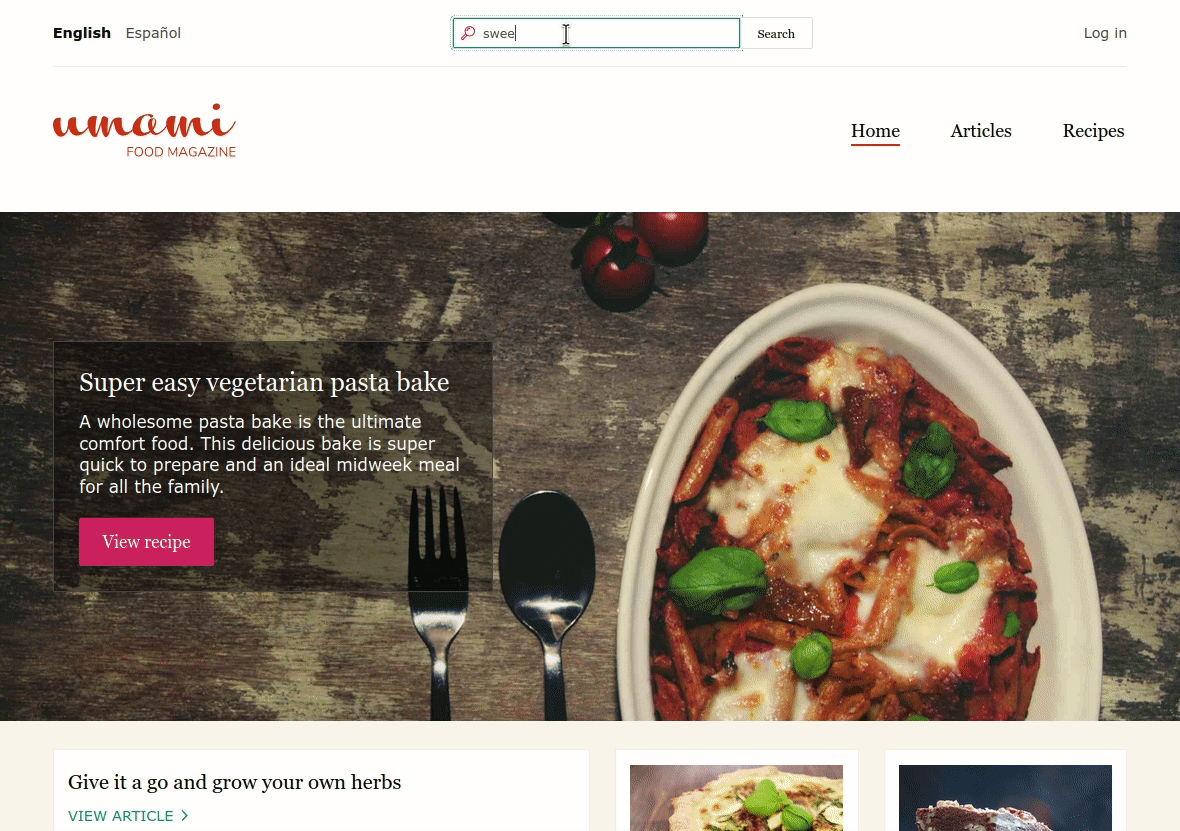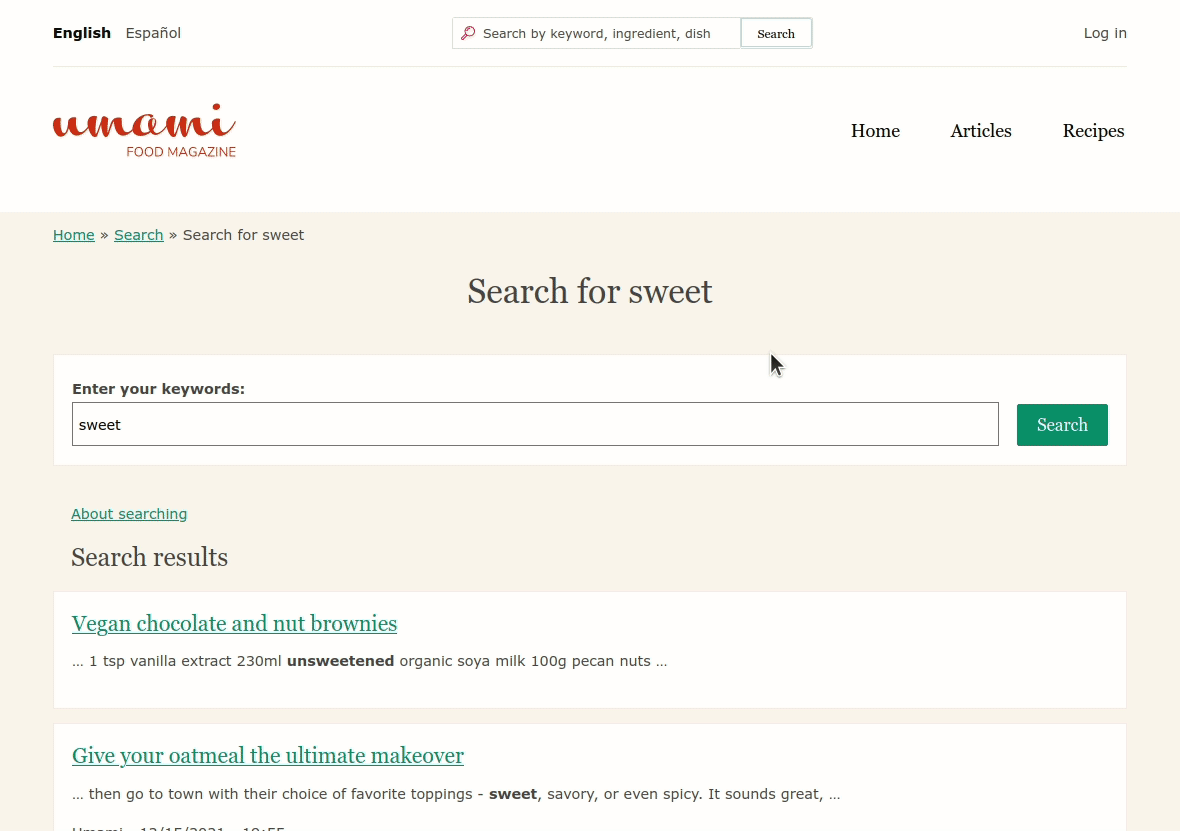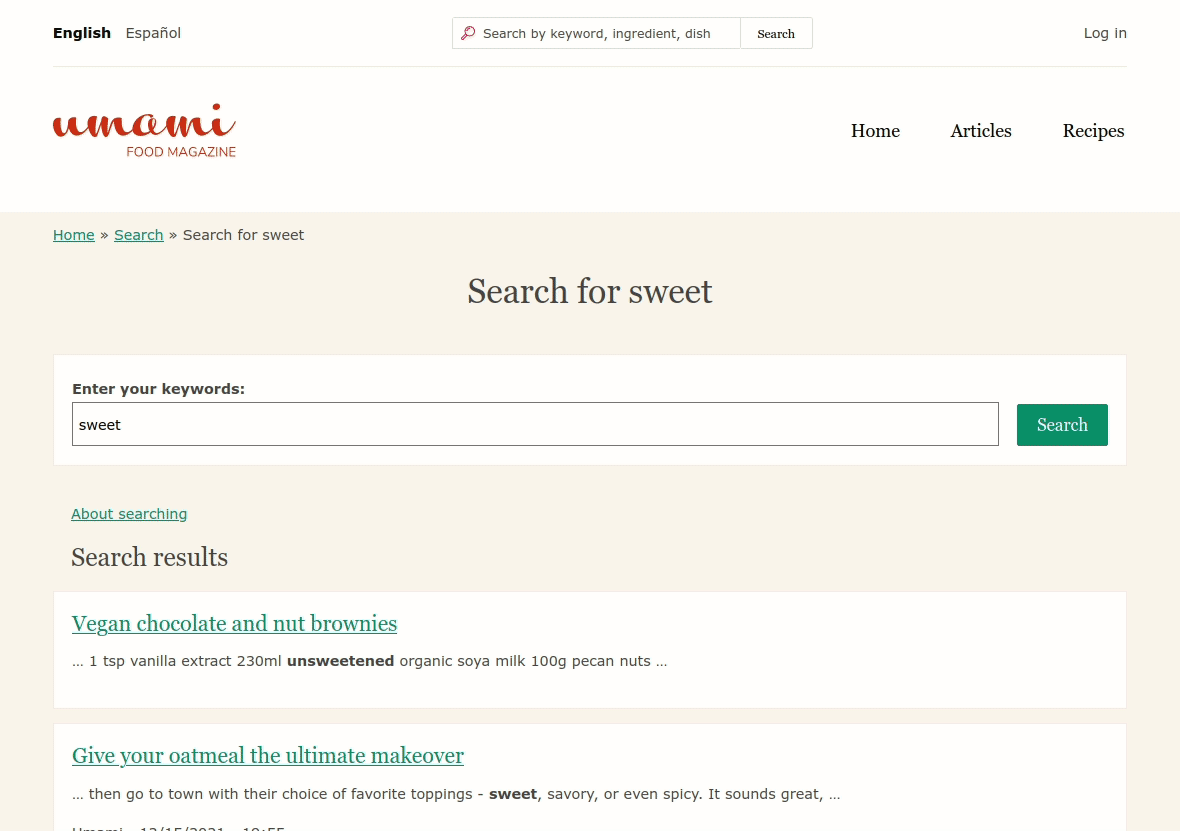
ressaThis would be a great improvement for sites who wants better search, with limited resources. The latest patch applies against 9.4.x and finds "unsweetened" when I search for "sweet" in the Umami installation profile. Without the patch, the "Vegan chocolate and nut brownies" recipe is not found.
PS. It's so awesome to be able to spin up a fresh Drupal instance in less than a minute with the Quick Start command:
Comment #180
devad commentedPatch #177 works for me with D9.3.0.
Comment #181
danflanagan8This still has the Needs tests tag which was originally added by a core committer, so I don't think it has any chance of getting committed without tests.
Setting back to NW for tests.
Comment #182
devad commentedRe: #181
I do not see this ever committed unless full backwards compatibility is preserved.
"Partial search" checkbox in core Search module settings would be great. It can stay unchecked by default for BC reasons.
And tests of course.
And if Partial search functionality is not going to be ever added to the core Search module due to simplicity reasons... maybe we can have it as a contrib module who adds such checkbox to the core search module settings?
Comment #183
izmeez commentedThere is a D7 issue with a working patch #498752: Partial word search for Drupal 7
Comment #187
devad commentedD10.2.x reroll.
Comment #188
devad commentedD10.2.x patch fix.
Comment #189
smustgrave commentedSeems to have many test failures.
Comment #190
mayuri_verma commentedPatch #188 works for me with Drupal 10.2.6 and PHP 8.2. Thanks!
Comment #192
vidorado commentedI've created a MR with the patch from #188 and a simple test for part of the changes. I couldn't figure out how to test the "argument" and "filter" view plugins that were also modified.
We also have to decide if the N-Gram solution is finally discarded in favour of this simple solution, and if this solution should be configurable (I believe it should be)
Comment #194
flyke commentedI just wanted to note that I wanted the default drupal search form to do partial search.
I applied MR10544 to a D11.2.8 project, cleared caches, and partial search immediatly worked.
I don't want to set this decades old issue to 'reviewed & tested by the community' myself, but I hope others can also confirm that this works.
One note though: should this be a setting at the /admin/config/search/pages settings form to enable/disable this, or do we all agree that it is logic to have search perform a partial search so this MR needs no changes ?
Comment #196
quietone commentedThe Search Module was approved for removal in #3476883: [Policy, no patch] Move Search module to contrib .
This is Postponed. The status is set according to two policies. The Remove a core extension and move it to a contributed project and the Extensions approved for removal policies.
The deprecation work is in #3565780: [meta] Tasks to deprecate the Search module and the removal work in #3565783: [meta] Tasks to remove the Search module.
Search will be moved to a contributed project before Drupal 12.0.0 is released.