
I had an issue where empty nodes were created every cron run. I managed to trace it to the publishing function executed in scheduler_cron().
The very root cause was that the nodes listed in the scheduler table were 'corrupted': the user that created these nodes was no longer present in the database, resulting in the node_load() for the nids from the scheduler table to fail.
The root cause was not the scheduler module, but it did add further 'corruption' (note the quotes) to an already problematic situation.
So, in my humble opinion, the scheduler module should check if the node_load() call was successful before modifying the node object and saving it back to the database.
When the load fails, it should log an error to the database so the admins know something's up and we don't just sweep it under the carpet.
A patch for this can be found in attach.
| Comment | File | Size | Author |
|---|---|---|---|
| #24 | 2011692-24-scheduler-missing_node_relations.patch | 1.35 KB | jonathan1055 |









{kind=link}
{kind=link}
Comments
Comment #1
jonathan1055 CreditAttribution: jonathan1055 commentedThanks malc0mn for explaining the problem and for doing the work to provide a solution. Yes I agree that even though this is not a scheduler bug we should test for a valid node_load() result and not compound the error.
The patch will need to be made to the 7.x scheduler version first. Do you have the means to do this? Also, just a few suggestions:
Thanks very much for helping, looking forward to the D7 patch.
Jonathan
Comment #2
malc0mn CreditAttribution: malc0mn commentedPatch in attach for 7.x-1.x
The exact error message logged to watchdog will probably need adjustment still... The reason for the wordyness is that I wanted to explain in short what to look for to fix this as the non-existant user is not the only root cause but the most likely one...
We cannot add the uid in the watchdog unless we do a separate query in the node table to get the uid. node_load() with a non-existent user will simply fail.
I added the empty node type check because that's a good pointer of immenent chaos (lol) as well. We should not act upon nodes without a node type to prevent who knows what.
The check could be split up as well to give a better error message maybe, but that might be overkill...?
Comment #3
jonathan1055 CreditAttribution: jonathan1055 commentedThanks for the D7 patch. Just a few points:
array('alias' => TRUE)to the call to l()Good work, thanks.
Comment #4
jonathan1055 CreditAttribution: jonathan1055 commentedI forgot to add that I tested the patch on a node where I had manually deleted the user row from the database. Scheduler did not give the new message about failing to load the node, because the node actually loads ok. Atleast, it did with my minimal set of modules in my test site, you may have additional functionality which is hooked in to node_load(). So that in itself did not trigger the new message. There were errors saying "Notice: Undefined index: 2 in user_node_load() (line 3606 of /Library/WebServer/Documents/drupal7/modules/user/user.module)" but this did not prevent the node from getting published. Annoyingly this error did prevent the normal scheduler watchdog line which says what action scheduler performed, but the node definitely got saved with the new publish status.
Then I took a different node which was scheduled for publishing and manually deleted the node row from the database table. This did trigger the new checking function and I got the new message in the dblog.
Jonathan
Comment #5
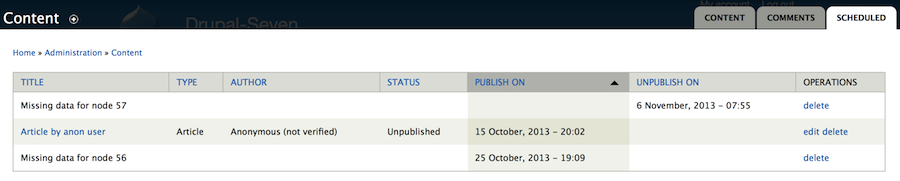
jonathan1055 CreditAttribution: jonathan1055 commentedCan I request another minor change to be added into this patch? On the sql join of the node and scheduler tables currently the nid value is taken from the node table. Obviously when everything is working correctly then this would be the same as the nid from the scheduler table, because the join is made on nid.
But in the cases we are discussing here, when something has gone wrong with the database, often the nid value may be null in this result. Then the watchdog message can give no information on what node scheduler was trying to act on. If the nid is taken from the scheduler table instead then it will be used in the 'view' link and the admin is given some idea as to where to start looking to solve the problem.
The change is highlighted in this image:

Thanks,
Jonathan
Comment #6
jonathan1055 CreditAttribution: jonathan1055 commentedFor reference, I have just closed #1410184: Scheduler breaks on Cron if a node has been deleted outside Drupal. as a duplicate of this issue.
One idea I had in #12 of that thread was the need to tidy up the {scheduler} table for nodes which have failed to load, otherwise they remain there forever. Should we incorporate that into this patch, as it is all related?
Jonathan
Comment #7
jonathan1055 CreditAttribution: jonathan1055 commentedChanging to a more generic title for better search results.
Marked #1906684: EntityMalformedException running cron job, when scheduler pointing to deleted node as a duplicate of this issue.
Comment #8
chrisfromredfinI just ran into this, and I'm not even sure how the database got into this state, but same overarching issues (appears in scheduler table but does not node_load). I took the existing patch from 2, and incorporated all the above feedback.
Comment #9
jonathan1055 CreditAttribution: jonathan1055 commentedGood work cwells, thanks for making the changes required. I've tested the patch and it all works as expected.
I've made a couple of changes, mainly in comments and coding standards. The only processing change is the addition of a fourth parameter $delete in _scheduler_check_node() which defaults to TRUE, but allows other functions to call this and not delete the row, eg from other modules implementations of hook_scheduler_nid_list_alter()
Here is a re-rolled patch and I'm happy to mark this RTBC. When it is committed, the credit should also go to malc0mn for making the first patch.
Thanks
Jonathan
Comment #10
pfrenssenI don't think this is the right approach. But let's take a step back first, at why this problem might be occurring in the first place.
This problem can be replicated quite easily I think. The cleanup of the scheduler table is done in
scheduler_node_delete(). This hook only fires if Scheduler is enabled, so this "corruption" can be simulated by creating a bunch of scheduled nodes, disabling Scheduler, removing a couple of the nodes and then enabling Scheduler again. Scheduler now has references to nodes that no longer exist, and will cause the trouble as mentioned above.Similarly, if users are removed from the system but their content remains, their user id will be set to 0. I think it might be wise to not schedule content from removed users.
The suggested solution is quite hacky though. It shouldn't be necessary to add checks in 3 different places, and I think it is a very bad idea to delete data in a function that is called
_scheduler_check_node(). This function name gives the impression that it just does some checks, and would not assume that calling this might cause data loss.IMO the right solution is much simpler, we just need to change the left joins to inner joins in scheduler_list(). This will prevent Scheduler from acting on invalid data.
Cleaning up the "corrupted" rows from the database is not our responsibility I think, after all this has been caused by external problems, but this can be discussed. If a developer causes this problem they can just as well fix it themselves:
DELETE FROM scheduler WHERE nid NOT IN (SELECT nid FROM node)Attached patch contains my proposed approach. I did not test it.
Comment #11
jonathan1055 CreditAttribution: jonathan1055 commentedI take your point. Yes it may be better to change the join to 'inner' as a better way to avoid the errors.
It does mean that the list of scheduled nodes in the admin content tab will simply never show the corrupted ones. Maybe we also need to provide some separate way for the scheduler table to be cleaned up by admins who do not have direct access to the database.
I'll test yout patch and have a think about this.
Jonathan
Comment #12
pfrenssenMaybe we can provide a drush command and/or an option in the configuration to "clean invalid data"?
Comment #13
jonathan1055 CreditAttribution: jonathan1055 commentedYep, I am working on that right now. Thank you for not passing my patch, as it was not the best solution. I did not really like the delete which cwells had added. That was not the cleanup I had imagined. But it has prompted us to make a better solution.
Jonathan
Comment #14
jonathan1055 CreditAttribution: jonathan1055 commentedI agree that the best way to avoid the errors during cron is simply to only process the good nodes. Clearing up the corrupt nodes will be dealt with in a separate issue.
I've tested your patch but you changed the sql in scheduler_list() which is used for displaying the scheduled nodes. The cron sql is in _scheduler_publish() and _scheduler_unpublish() so it is here that we need to change the join from LEFT to INNER.
I used your method to create corrupt nodes and tested the changes. If you have a corrupt node scheduled for publishing and another corrupt node scheduled for unpublishing, the cron run fails during _scheduler_publish() and does not get as far as _scheduler_unpublish(). With INNER for each, the bad nodes are ignored as required.
I also added an INNER join to the users table. This is to prevent problems described above where the user table has become incomplete. We should also consider implementing hook_user_delete() to remove rows from scheduled nodes when they are reassigned to the anonymous user, but that will be in another issue.
Here's the patch against 7.x-1.1+10
I do not have
git diff, I use justdiff. I have tried to find out how to format the patches in the a/ b/ style, but I have not found the option to do it.Jonathan
Comment #15
jonathan1055 CreditAttribution: jonathan1055 commentedRe-rolled patch for 1.1+15 dated 25th Sept, in git diff a/ b/ format.
Comment #16
jonathan1055 CreditAttribution: jonathan1055 commentedHere is a re-roll of the patch, now against 1.1+19. It still applies ok even after the .module patch in #1566024: Coding Standards and Coder Review #27 but with a fuzz and offset. So it should be able to be tested and committed at the same time without any further re-roll.
Jonathan
Comment #17
jonathan1055 CreditAttribution: jonathan1055 commented#16: 2011692-16-scheduler-missing_node_relations.patch queued for re-testing.
Comment #19
jonathan1055 CreditAttribution: jonathan1055 commentedThe patch applies manually with an offset and a fuzz value. So does the failure above mean that for automated testing it has to apply absolutely cleanly with no offset? or is it the fuzz which caused the problem? The reason given is:
There is no further explanation in the details. It would be useful to know if it was the fuzz or offset which causes the failure, as that would help to minimise the number of re-rolls we need to do.
Comment #20
jonathan1055 CreditAttribution: jonathan1055 commentedTo test this, here is the same code changes, in a patch which applies with two offsets. However I have corrected the line which caused the 'fuzz' value. This will show if the automated testing accepts patches with offsets.
Comment #21
jonathan1055 CreditAttribution: jonathan1055 commentedThe successful test result above shows that the automated testing does accept patches which apply with offset(s) but does not accept patches with a fuzz. That's useful to know, and means we have less re-rolling to do after the major code review changes in #1566024: Coding Standards and Coder Review
However, the patch does alter the code at the same places as in #1182450: i18n support - Synchronize scheduled dates in translated nodes so whichever is committed first, the other will need to be re-rolled.
Comment #22
pfrenssenLooking at this again I have one reservation: the inner join with the users table prevents to schedule nodes that are created by anonymous users. When this was discussed above we were thinking about users that were removed from the system but I realized there is also the possibility that websites allow anonymous users to create nodes, and these would become unschedulable. This might break existing websites. There are 50000 websites using this module so chances are that at least some of them have use cases for anonymously created nodes.
What would be the best option? Play it safe and only commit the join with the node table? That would still fix this issue, and not risk breaking websites.
Comment #23
jonathan1055 CreditAttribution: jonathan1055 commentedNo I already thought of that, and it's fine. The anonymous user is uid 0 and they have a row in the users table too, so the inner join will not exclude them. The join with users will only exclude nodes which are still 'owned' by a user which has been deleted without reassigning their content to a new user, and would thus cause node_load() to throw an error (which is exactly what we want).
Incidentally, I've also just tested anon user scheduled nodes in conjunction with #2110983: Improve UI functionality for scheduled nodes list and they both work fine together.
Jonathan
Comment #24
jonathan1055 CreditAttribution: jonathan1055 commentedRe-roll needed at 1.1+34
Comment #25
jonathan1055 CreditAttribution: jonathan1055 commentedComment #26
pfrenssenAlright, this is a straightforward fix, let's get it in. I don't think this really needs a test since this problem will not occur during normal usage. Writing a test that deliberately introduces database corruption is not really useful I guess :)
Committed to 7.x-1.x: commit 46c1d4a. Thanks!
Comment #27
jonathan1055 CreditAttribution: jonathan1055 commentedExcellent. Thank You. Yes I agree it does not need tests. Thanks for the other commits too.
Do you know how we can progress the fact that none of the commits from 23 Nov onwards are showing in the list from https://drupal.org/node/3292/commits and the dev package has not been refreshed since 18th Nov.
I have raised it on #2125405: Not all commits showing up but nothing seems to be happening on that thread.
Comment #28
pfrenssenIf it has been reported there is not much more we can do, the d.o team will certainly fix it when they get around to it. If you feel like helping out I'm sure they will be very grateful. Check out Contribute to Drupal.org.
Comment #29
jonathan1055 CreditAttribution: jonathan1055 commentedPieter,
Some fixes have been deployed on #2132659: [META] Problems with Project Release Packaging and #2150865: Saving release notes makes release disappear from project feed and project page release table. Could you edit the latest release and save again, and that might fix the -dev release not showing up. Worth a try anyway.
Jonathan